Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 7 - Translation, Seq2Seq, Attention
cs224n
목록 보기
1/2
Attention
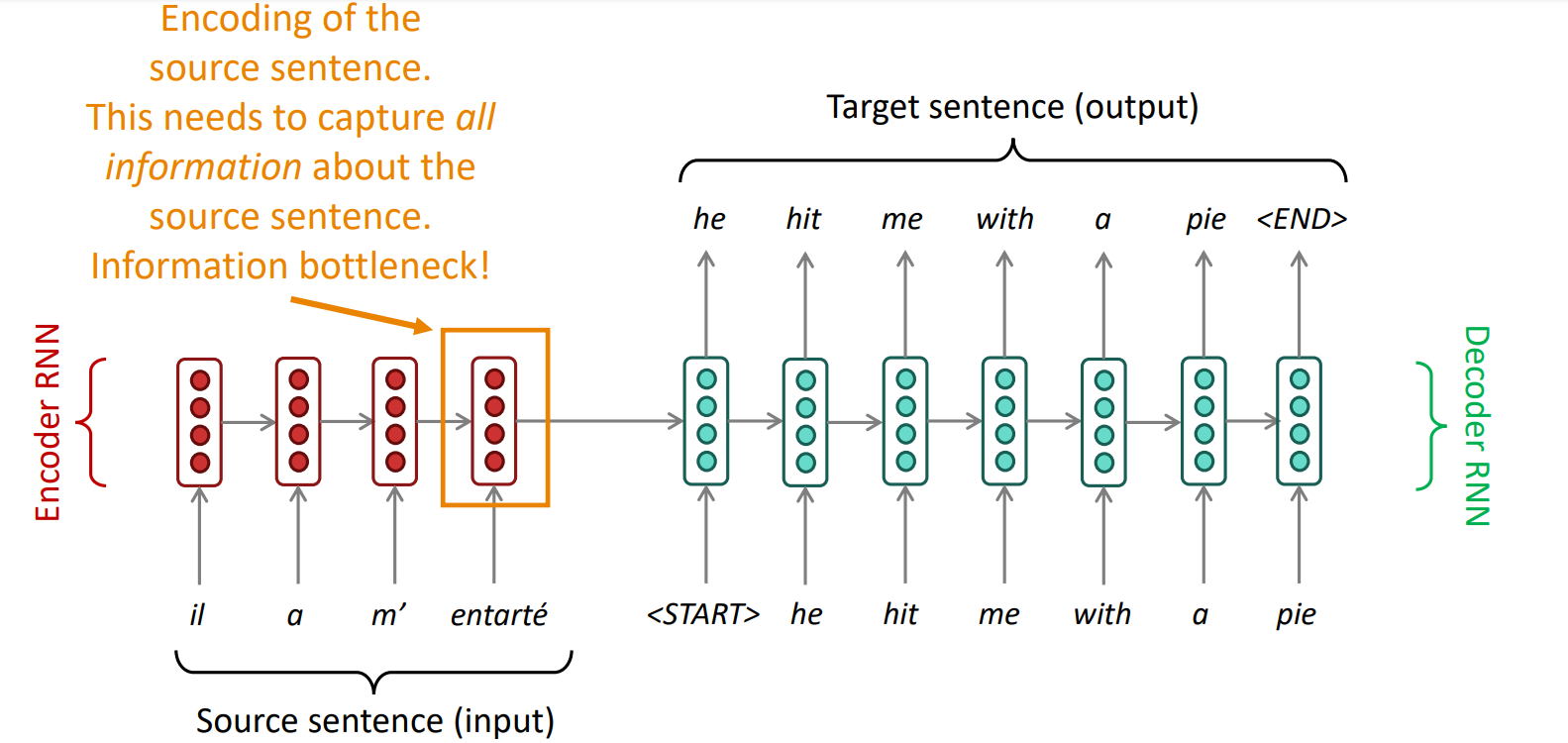
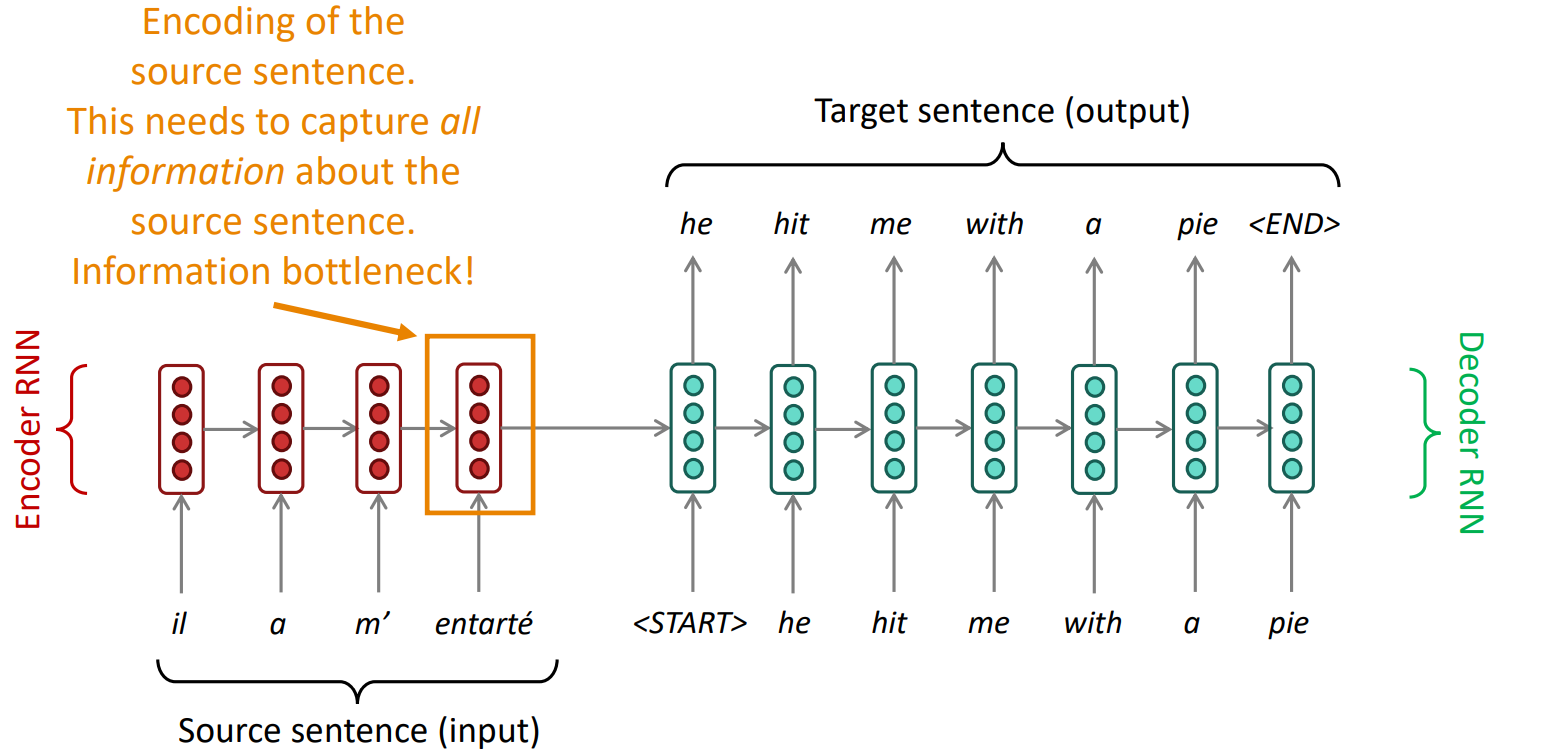
Seq2Seq에서의 bottleneck problem
- encoder RNN의 마지막 hidden state에 모든 정보가 쏠림
- Sentiment Analysis task에서는 문장 전체를 보지 않아도 좋은 performance를 낼 수 있었지만 NMT task에서는 아님
- 사람이 번역을 할 때도 source sentence를 확인하며 필요한 부분에 attention
Attention
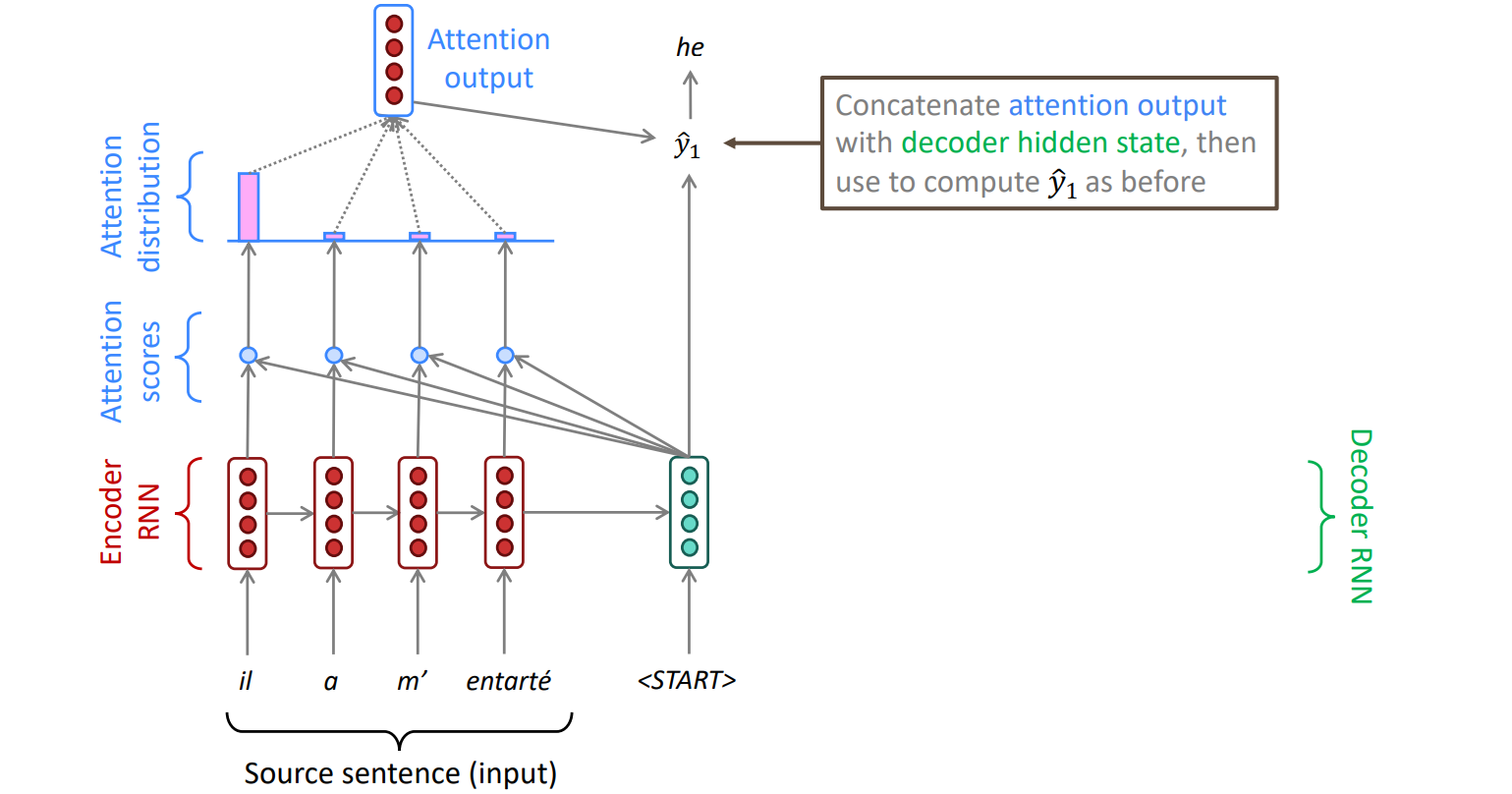
- decoder의 hidden state와 encoder의 각 단계에서의 hidden state를 내적 → Attention Scores
- 각각의 attention score에 softmax 취함 → Attention Distribution
- 번역할 때 어떤 단어에 초점을 맞춰야하는지 알 수 있다
- attention distribution으로 encoder states 가중 평균 → Attention Output
- [decoder hidden state; attention output] → 단어 예측
- source sentence로부터 더 많은 정보를 가져올 수 있고 그 결과 더 좋은 번역이 가능하다

개발자 연습생