Circa 2016, nlp strategy
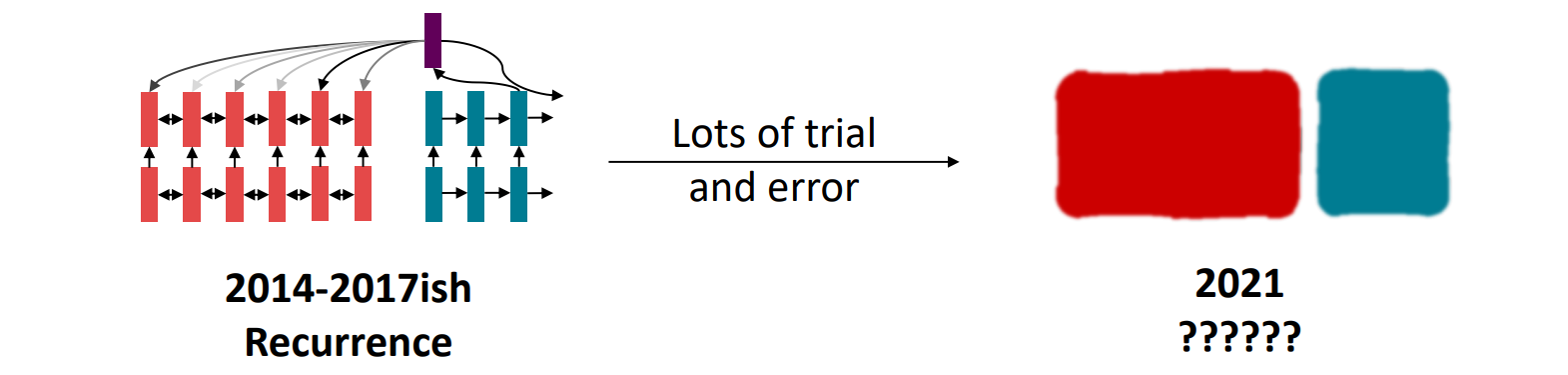
- bidirectional LSTM으로 문장 encoding
- LSTM decoder
- attention을 이용해 메모리에 유연하게 접근
- 2021년, 모델에서 최적의 building block은 무엇일까
RNN의 문제
Linear interaction distance
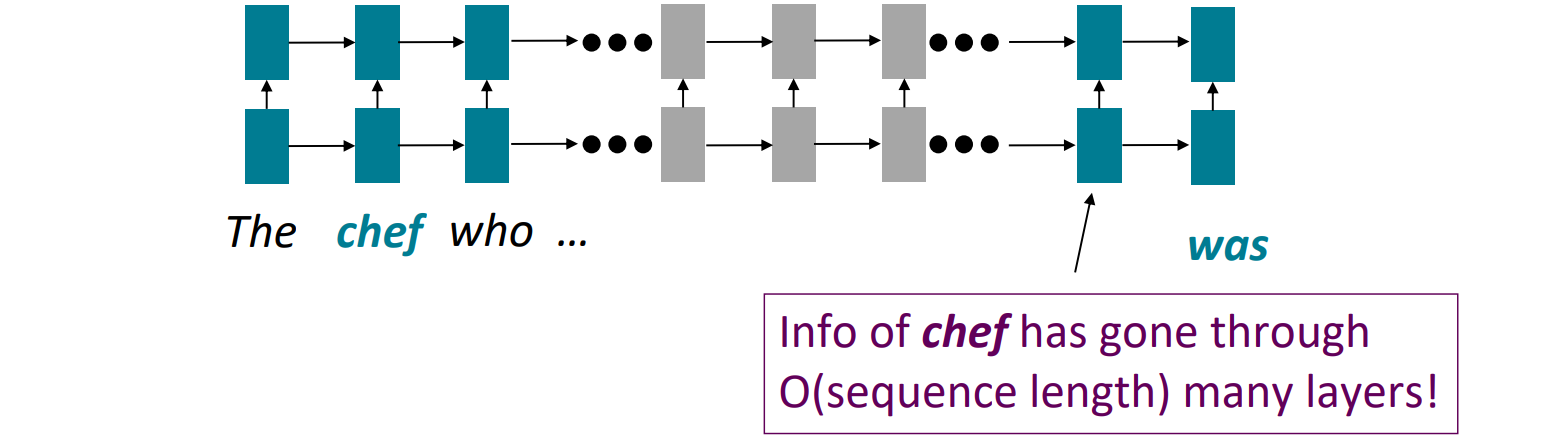
- gradient vanishing으로 long-distance dependencies를 학습하기 어렵다
- 선형 인접성을 인코딩하는데 linear order isn't the right way to think about sentences
Lack of parallelizability
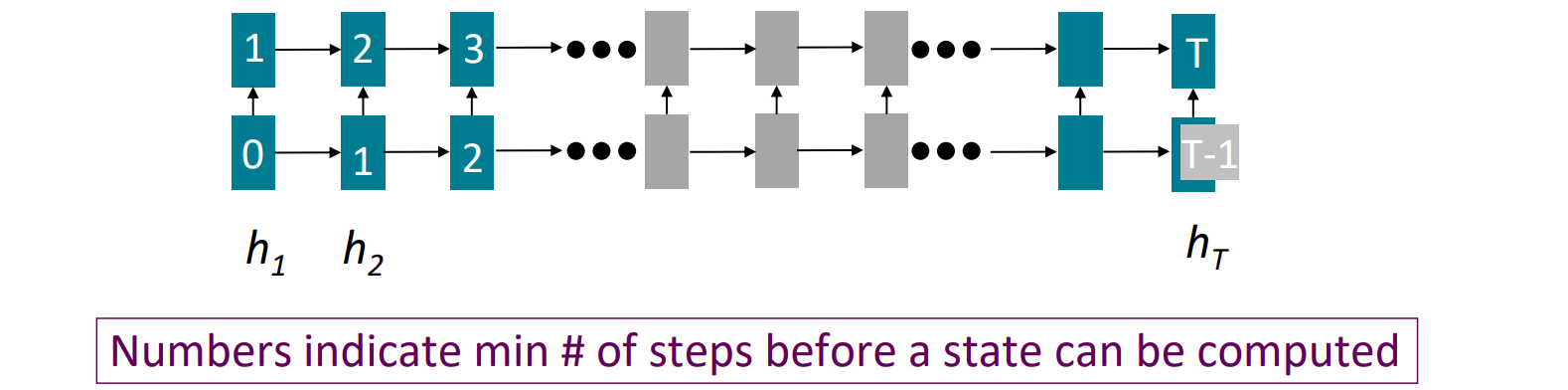
- 앞에 거 계산해야 뒤에 거 계산할 수 있다 → GPU 병렬 계산 활용 불가
Self-Attention
- queries /
- keys /
- values /
- keys, queries, values는 같은 source에서 생성된다
만약 이전 층의 출력이 (단어 당 벡터 하나) 라면, 로 모두 같은 벡터
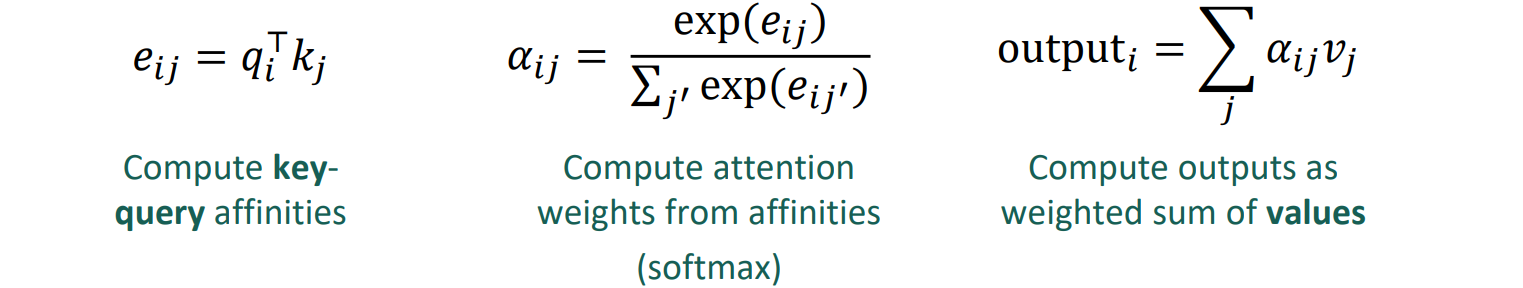
Self-Attention as an NLP building block
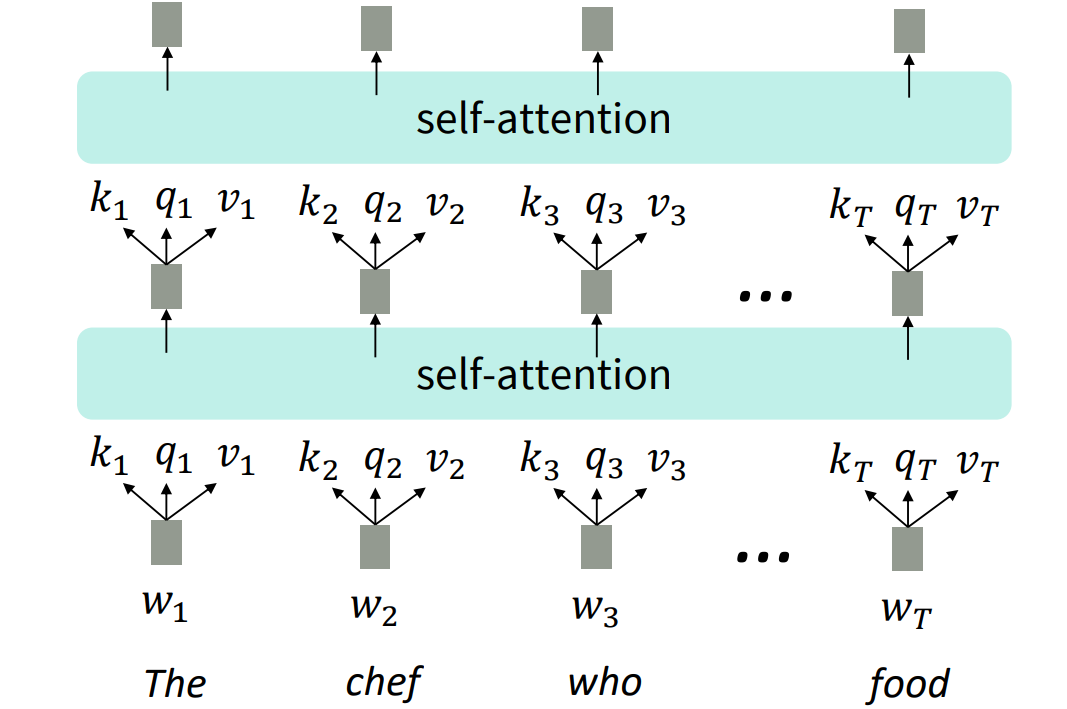
- LSTM을 쌓았던 것과 같이 Self-Attention block을 쌓았다
- Self-Attention은 집합으로 연산되기 때문에 순서에 대한 정보가 누락되어 있다
- 위치벡터의 필요성 제시
position vector
- Sinusoidal position representations: concatenate sinusoidal functions of varying periods
- Learned absolute position representation: 모든 를 학습가능한 매개변수로 놓자
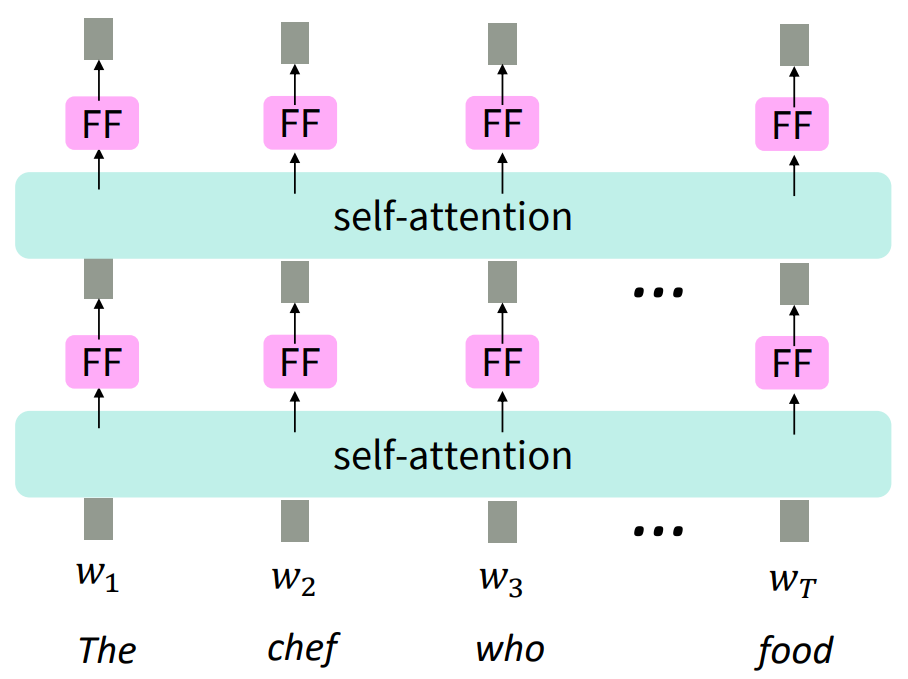
Adding nonlinearities
- add a feed-forward network to each output vector
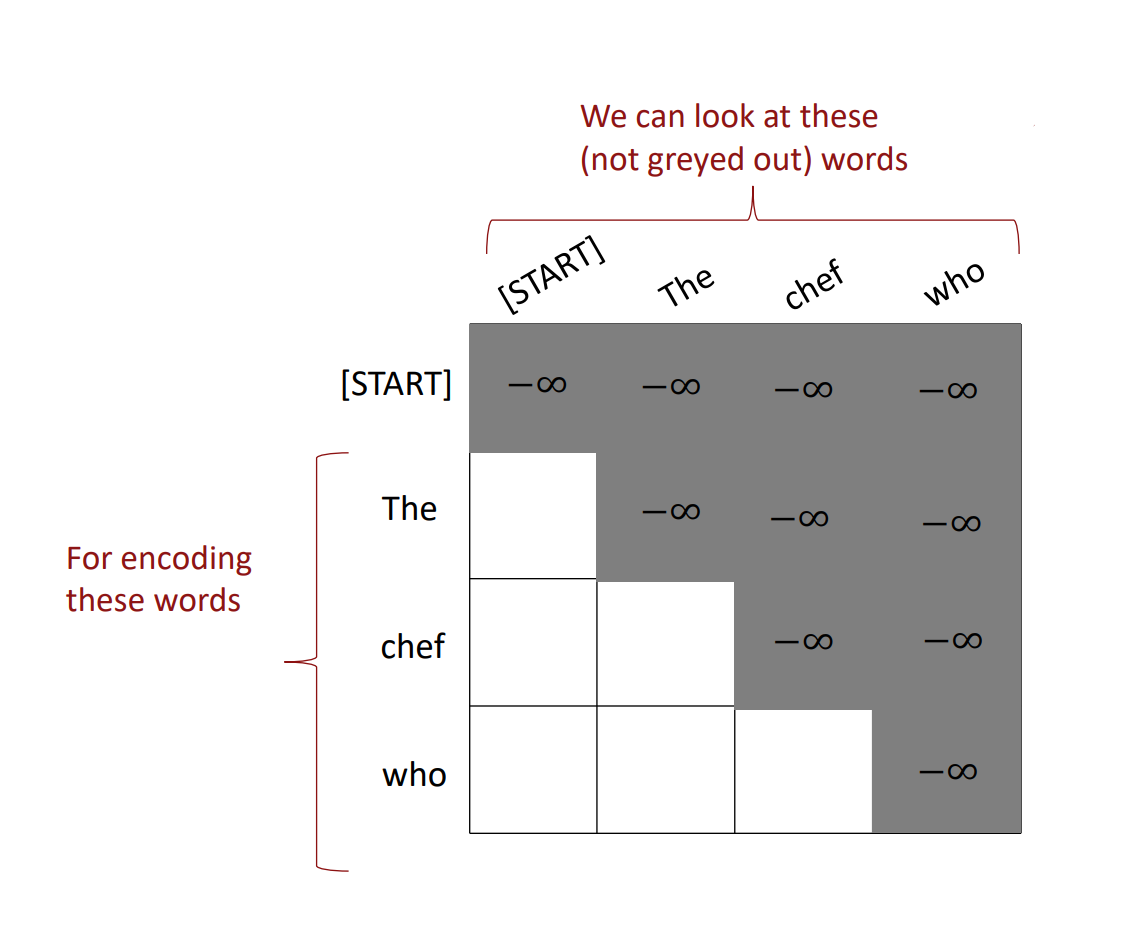
Masking the future
- mask out attention to future words by setting attention scores to
Transformer Encoder: Key-Query-Value Attention
- concatenation of input vectors
- key matrix /
- query matrix /
- value matrix /
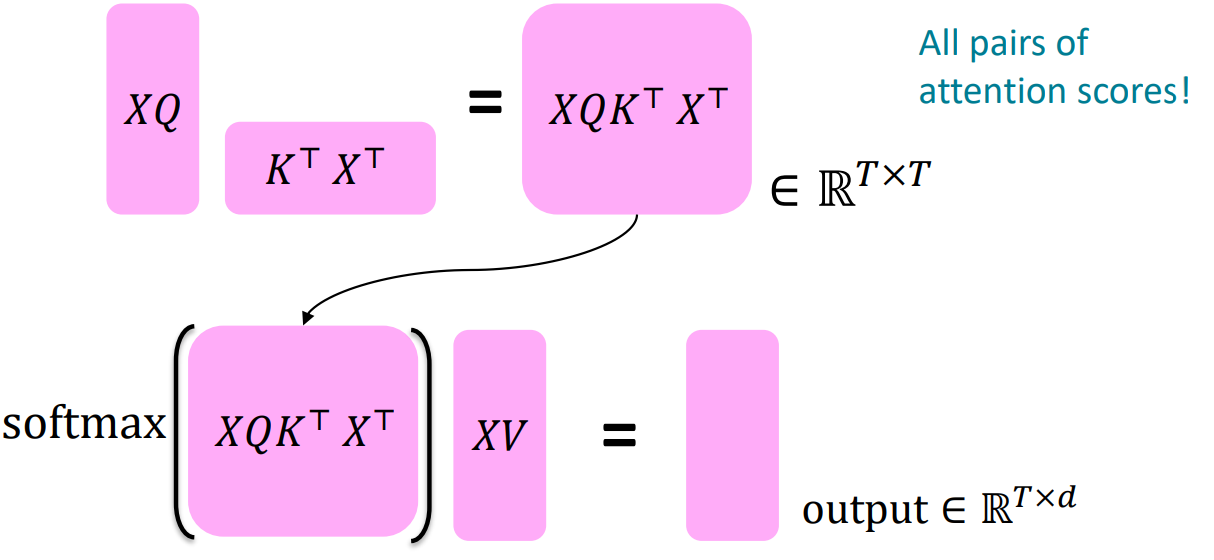
- key, query로 softmax 구해서 value랑 weigthed sum
Transformer Encoder: Multi-headed Attention
- 문장 내 여러 곳을 동시에 보려면
- /
- /
- 각 head는 각기 다른 것에 집중하며 서로 다른 벡터 생성

Transformer Encoder: Residual connections
- X^{(i)} = X^{(i-1)}+\texttt{Layer}(X^{(i-1)})
- layer 가 layer 과 어떻게 달라야 하는지만 학습
- gradient vanishing problem 완화
Transformer Encoder: Layer normalization
- hidden vector의 불필요한 정보 변동을 표준화를 통해 제거
Transformer Encoder: Scaled Dot Product
- 차원 가 증가하면 내적인 attention score 역시 커짐
- score가 커지면 softmax의 일부 값이 굉장히 커지게 되고 낮은 확률을 지니고 있던 값들도 너무 작아져 기울기가 0으로 수렴하는 문제 발생
- attention score을 로 나누어준다
Transformer Encoder-Decoder
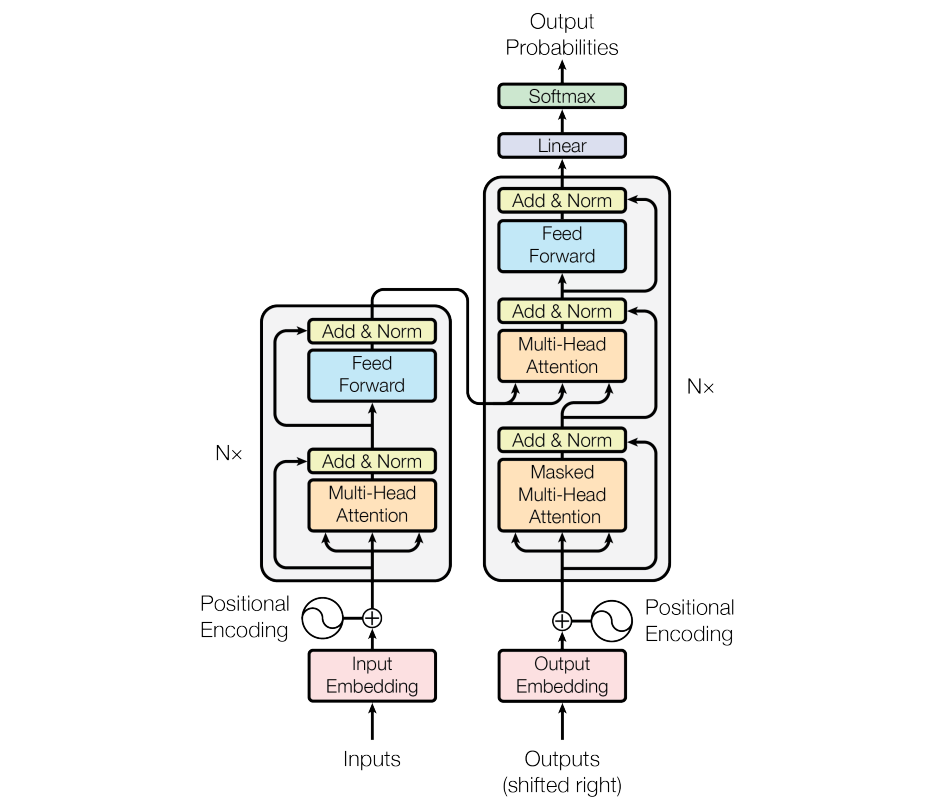
- 매 층마다 residual과 layer normalization 수행
- feed forward는 attention 연산이 완료된 후에 적용
- encoder는 단순 multi-head attention
- decoder는 미래를 추론해야 하기 때문에 masked multi-head attention
- cross-attention: encoder의 출력값과 decoder의 출력값 합쳐서 attention 수행
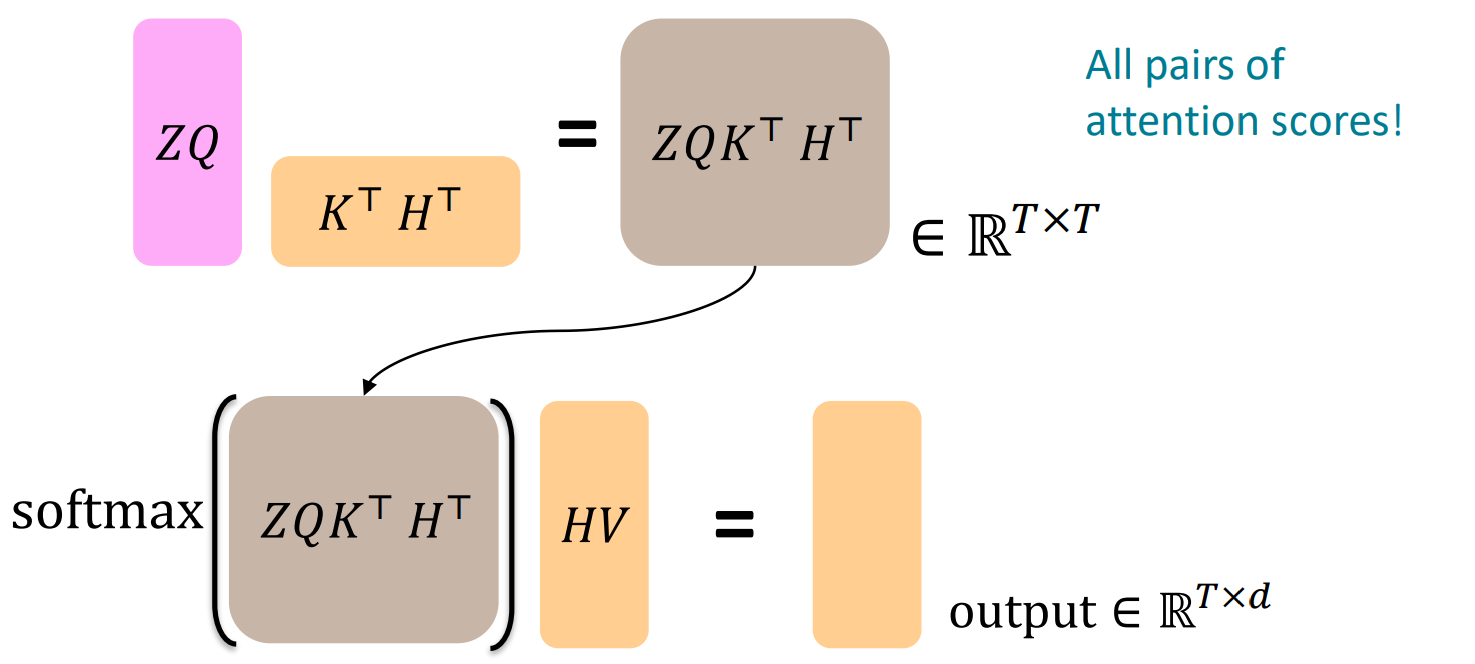
Transformer Decoder: Cross-attention
- encoder vectors
- decoder vectors
- keys와 values는 encoder로부터
- quries는 decoder로부터

개발자 연습생