헷갈리는 모델에 대해 정리...
ALBERT
-
Challenge: BERT와 같은 Pre-training language represenation 모델은 일반적으로 모델의 파라미터 크기가 커지면 성능이 향상됨. 하지만 다음과 같은 문제 발생
1. Memory Limitation: 모델의 크기가 메모리량에 비해 큰 경우 학습시 OOV 문제- Training Time: 학습시간이 오래걸림 (BERT base의 경우 16개의 V100 GPU 사용시 5일 이상, BERT large의 경우 64개의 V100 GPU 사용시 8일 이상 소요)
- Memory Degradation: Layer의 수 or Hidden size가 커지면 모델 성능 감소
-
Contribution: BERT의 다음의 사항을 개선하여 모델의 크기는 줄이고 높은 성능을 보임
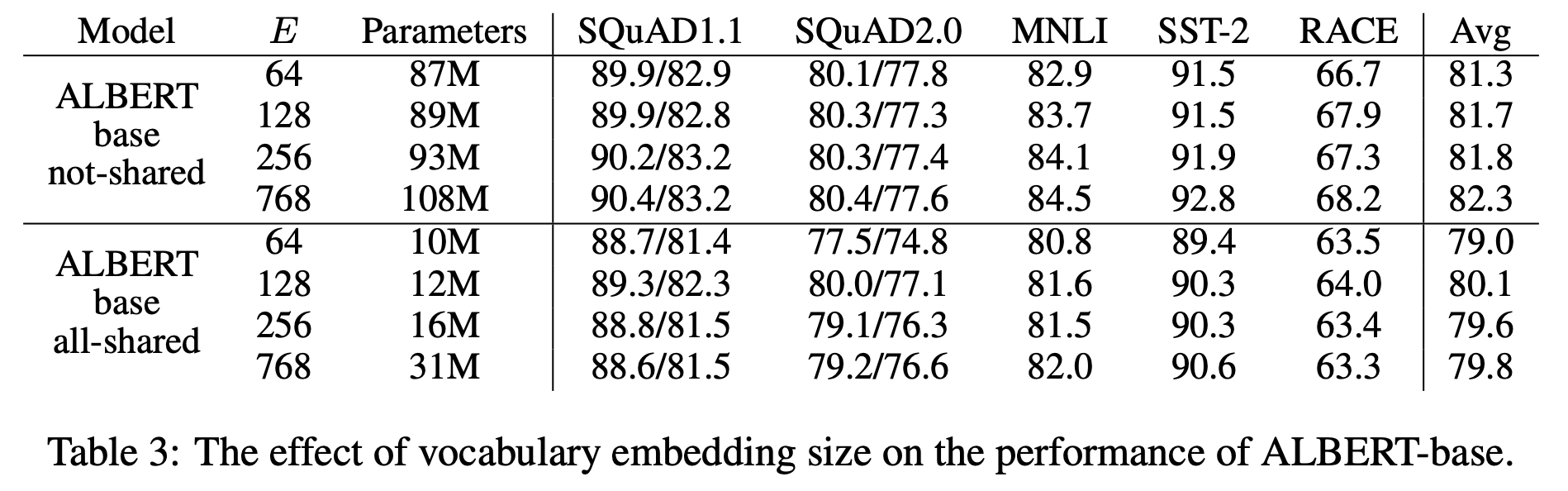
1. Factorized embedding represenation: BERT에서는 Input Token Embedding Size(E)와 Hidden Size(H)가 같음. ALBERT에서는 Layer를 한개 추가하는 방식으로 layer 크기를 줄였음. V가 vocab size라면
기존 BERT는 VH Martix을 활용하여 Token Embedding을 진행함. ALBERT는 VE, EH 2개의 Matrix를 곱하는 방식으로 진행하여 Parameter 수를 줄였음. (E, H는 상당히 작은 값). Embedding 과정을 2개의 Matrix으로 나눠서 수행하므로 Factorized Embedding이라고 부름.
-
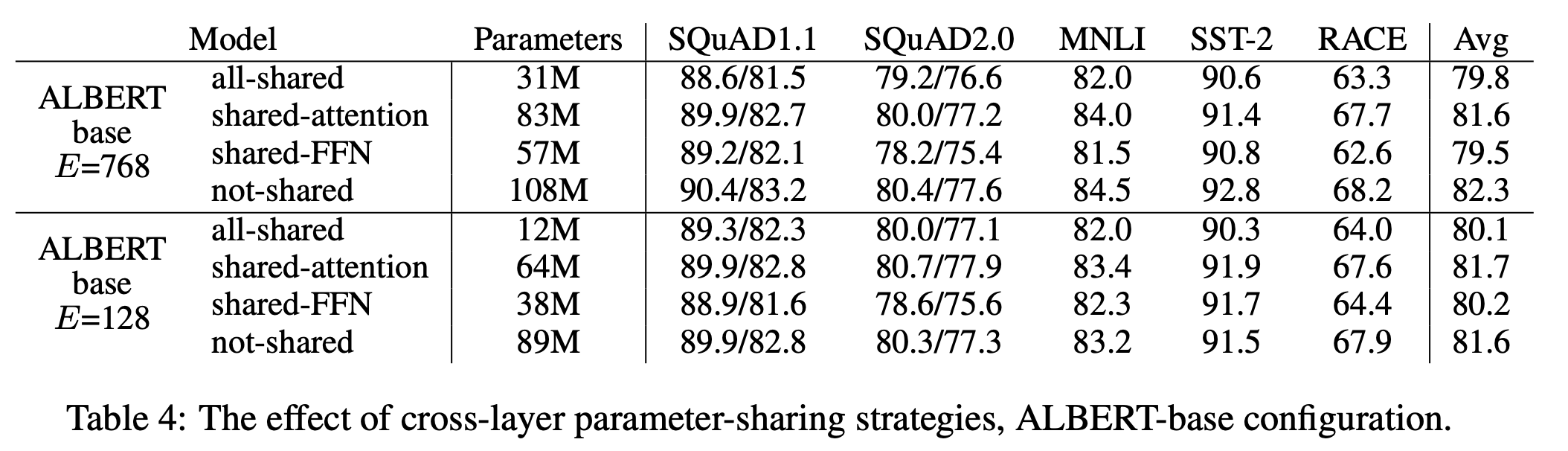
Cross-layer paramter sharing: transformer layer 간 같은 parameter를 공유하며 사용하는 방식임. 시험 결과 self-attention layer만 공유했을 때에는 성능이 크게 떨어지지 않지만, Feed Forward Network를 공유 시 성능이 다소 떨어졌음.
-
Sentence order prediction: Next Sentence Prediction(NSP) 대신 두 문장의 순서가 옳은지 여부를 판단하는 Sentence order prediction (SOP) 사용. 실험 결과 SOP로 학습 시 NSP는 어느정도 가능하지만, NSP는 문장 간 관계를 잘 학습하지 못하기 때문에 SOP 성능이 낮아짐.

-
