Importance Estimation from Multiple Perspectives for Keyphrase Extraction (EMNLP 2021)
keyphrase_extraction
Abstract
- NLP에서의 keyprhase extraction (KE)은 보통 2개의 파트를 포함함
- candidate keyphrase extraction
- keyphrase importance estimation
- 이전의 KE 방법론들은 bias results을 추출했음.
- 이 논문에서는 to estimate the imoportance of keyphrase from multiple perspective를 위해 KIEMP를 제안하는데 크게 3가지의 moudules로 구분됨
- chunking module to measure its syntactic accuracy
- ranking moudule to check its information saliency (검출!?)
- matching module to judge the concept (i.e., topics) consistency between phrase and the whole document
- 위의 3가지 module을 end-to-end multi task learning model로 seamlessly (원활하게) 조합해서 각 파트를 강화시키고 세 가지의 perspectives의 효과를 균형있게 만듦
- 실험 결과로 KIEMP가 존재하는 최신 keyphrase extraction approaches에서 우수한 성능을 보였음.
Introduction
- 전형적인 KE는 candidate keyphrase extraction, keyphrase importance estimation으로 이루어짐

- 위 그림과 같이 keyphrase는 1개 이상의 단어들로 구성되어 있음
- KE에서 중요한건 뽑힌 candidate set에서 ground truth keyphrase set을 찾는 것임(important keyphrase)
- 이 논문에서는 keyphrase를 multiple perspective에서 보고 뽑는 것을 목표로 함
- chunking modules: 각 candidate keyphrase의 syntactic accuracy를 측정하기 위해 binary classification layer 사용
- ranking moudels: pairwise ranking approach를 통해 각 후보 구문의 semantics saliency를 확인함. 더 salient한 keyphrase를 추출하기 위해 candidate keyphrases 간의 경쟁을 유도함
- matching module: metric learning framework를 통해 document의 각 candidate phrase의 concept relevance를 판단함.
- 세 가지의 modules를 jointly training 진행하여 세 가지의 perspective의 효과를 균일하게 반영함
- 실험적으로 KIEMP가 다른 모델들보다 잘 나왔음을 확인함
Methodology
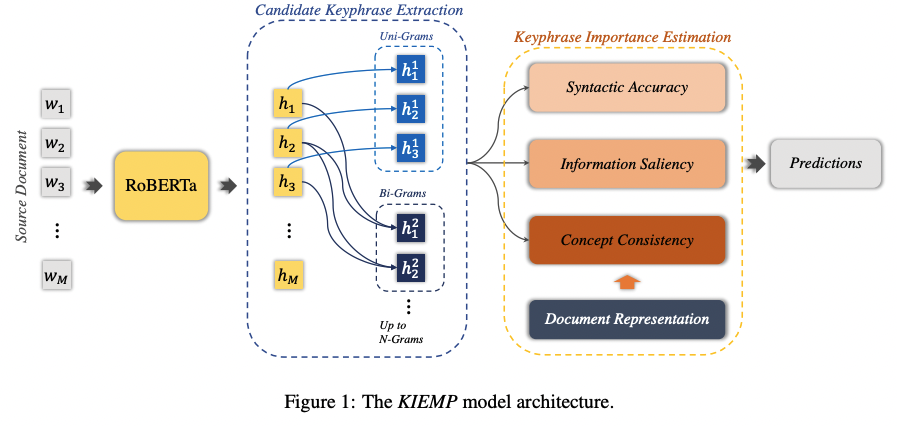
- Document를 D = {w{1}, ..., w{i}, ..., w_{M}}으로 정의.
- KIEMP는 multiple perspectives의 representation에 기초하여 그들의 n-gram으로부터 set of keyphrase를 추출하기 위해 학습함.
- KIEMP는 mainly consist of two submodels:
- candidate keyphrase extraction: identifies and extracts candidate keyphrases
- keyphrase importance estimation: estimates the importance of keyphrases from three perspectives simultaneously with three modules to determine which one should be extracted.
1. Contextualized Word Representation
RoBERTa를 각 단어의 representation을 표현.
H = {h_1, ..., h_i, ..., h_M}
H = RoBERTa{w_1, ..., w_i, ..., w_M} (h_i는 RoBERTa의 [CLS] token)
2. Candidate Keyphrase Extraction
이전 연구들은 document에서 n-gram으로 뽑은 것들을 candidate keyphrases로 간주했음. 이전 연구들에 motivated하여 언어 속성을 고려하고 CNN에 의해 n-gram으로 문맥화된 word representations을 구성함.
i-th n-gram인 c^n_i의 phrase represenation은 다음과 같이 표현된다.
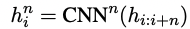
h^n_i는 i-th n-gram의 represenation을 가리킴.
n: length of n-grams
N: maximum length of allowed candidate n-gram
각 n-gram은 window size가 n이고 stride가 1인 CNN^n의 convolution filters를 갖고 있음.
3. Keyphrase Importance Estimation
세 개 모듈의 관점을 모두 반영하여 keyphrase의 중요성을 판단하는 것은 성능 올리는 데에 굉장히 중요한 파트임.
3.1 Chunking for Syntactic Accuracy
phrase의 syntactic accuracy인 c^n_i는 다음과 같은 chunking module로 계산됨
W_1, b_1은 trainiable matrix와 bias임. softmax는 가능한 모든 n-gram의 각 position i와 length n임.
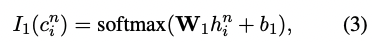
전체 모델은 cross-entropy loss를 통해 훈련됨.
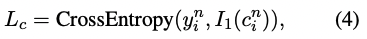
y^n_i는 phrase c^n_i가 original document의 keyphrase인지 아닌지에 대한 label임.
3.2 Ranking for Information Saliency
candidate keyphraes에 순위를 매기기 위해 모든 candidates사이의 saliency(현저함) pairwise learning approach를 적용한다.
먼저, candidate keyphrases에 대해 positive set은 P+, 다른 것들은 P-으로 labeling한다. pairwise learning model의 loss function은 hinge loss를 사용한다.
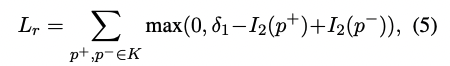
I_2는 information saliency를 나타냄. 세타_1은 margin을 나타냄.
KIEMP는 동일한 문서 내에서 P-보다 먼저 candidate keyphrases인 P+의 순위를 지정하도록 함. 구체적으로, i-th n-gram representation c^n_i의 information saliency는 다음과 같이 계산됨.
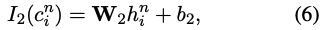
W_2는 trainable matrix, b_2는 bias.
pairwise learning model을 통해 모든 candidates의 information saliency를 rank할 수 있고, 더 두드러진 정보가 있는 keyphrases를 추출할 수 있음.!
3.3 Matching for Concept Consistency
phrases는 문서의 concepts에 따라 다르게 표현될 수 있음. matching module은 candidate keyphrases와 그들에 해당되는 document 사이의 concept consistency를 계산하기 위해 metric learning을 진행함.
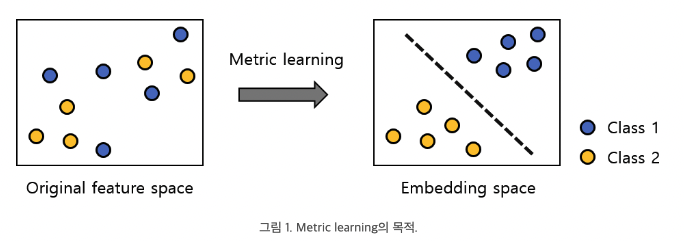
- metric learning: 기존의 feature로는 분류가 쉽지 않았던 데이터에 대해 데이터를 class label 별로 구분할 수 있게 만드는 metric을 학습하는 것.
먼저, document D에 variation autoencoder를 적용하고, candidate keyphrases K의 concepts을 얻기 위해 적용함. 각 문서 D는 standard Gaussian prioir를 통해 latent variable z로 인코딩 됨. 각 variable을 통해 documents에 숨어있는 latent concepts 결정하고 keyphrase를 유용하게 추출할 수 있음. encoding process동안 z는 Gaussian distribution을 위한 re-parameterization trick을 통해 sampled됨.
decoding process동안 document는 multi-layer network with tanh에 의해 reconstructed 됨. 게다가 candidate keyphrases도 documents와 같은 과정을 거침.
일단 document의 z의 concept represenation와 phrase z^n_i를 얻으면, concept consistency는 다음과 같이 계산됨.
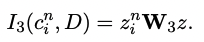
W_3는 learnable mapping matrix.
loss function은 triplet loss를 사용하고 다음과 같이 계산됨.
- triple loss: multi-class classification에 이용되는 metric learning임. 주어진 데이터셋에서 선택된 데이터인 anchor, 그리고 anchor와 동일한 class label을 갖는 positive sample, 다른 class label을 갖는 negative sample로 정의됨. embedding space에서 anchor와 positive sample의 거리는 가까워지고, negative sample과의 거리는 멀어지는 것을 목표로 학습함. 아래 그림 참고.
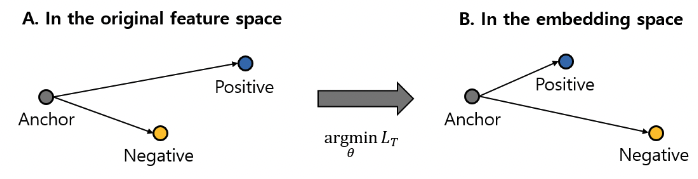
논문에서 사용된 triplet loss는 다음과 같다.

KIEMP가 해당 문서 D 내에서 non-keyphrase p- 보다 앞서 keyphrase p+의 conept consistency를 match하고 rank 하도록 강제함.
reconstruction loss를 최소화하고 prior distribution과 posterioir distribution의 discrepancy(불일치)를 penalize하기 위해 VAE는 다음과 같은 objection function을 통해 optimizing하도록 구현되었음.
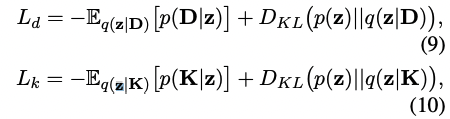
D_KL는 두 개의 distributions에 대한 Kullback-Leibler divergence를 나타냄. 그리고 final loss는 다음과 같이 계산됨.
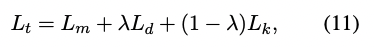
람다는 (0,1) 사이의 값이며 balance factor임.
concept consistency matching을 통해 document에서 high-level concepts를 포함한 keyphrases를 기대할 수 있음.
3.4 Model training and Inference
KIEMP는 syntactic chunking, saliency ranking, concept matching의 end-to-end learning을 진행함. 그리고 나서 training objective는 다음과 같은 conbination으로 학습됨
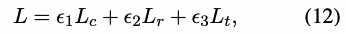
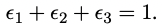
KIEMP는 keyphrase의 saliency에 따라 keyphrase를 추출하는 것을 목표로 함.
chunking과 matching은 적절한 candidate keyphrase를 rank를 enforce하기 위해 사용됨. 따라서 inference에서는 ranking module만을 사용함
Experimental Settings
Datasets
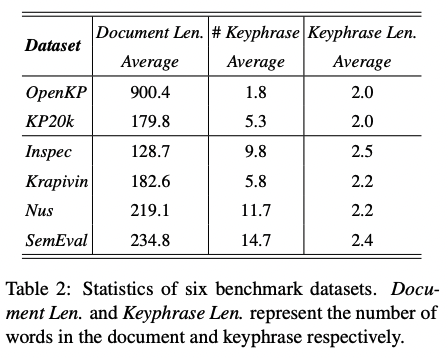
- OpenKP: 150K의 document로 이루어져 있음. training (134K documents), development (6.6K documents), testing (6.6K documents). 전문가들에 의해 labeling 되었으며, 문서 당 1~3 keyphrases가 태깅되어 있음.
- KP20k: high-quality scientific metadata로 이루어져 있음. training (528K documents), validation (20K documents), testing (20K documents).
KIEMP의 robustness를 증명하기 위해 Ispec, Krapivin, Nus, SemEval을 포함한 KP20k로 학습시킴.
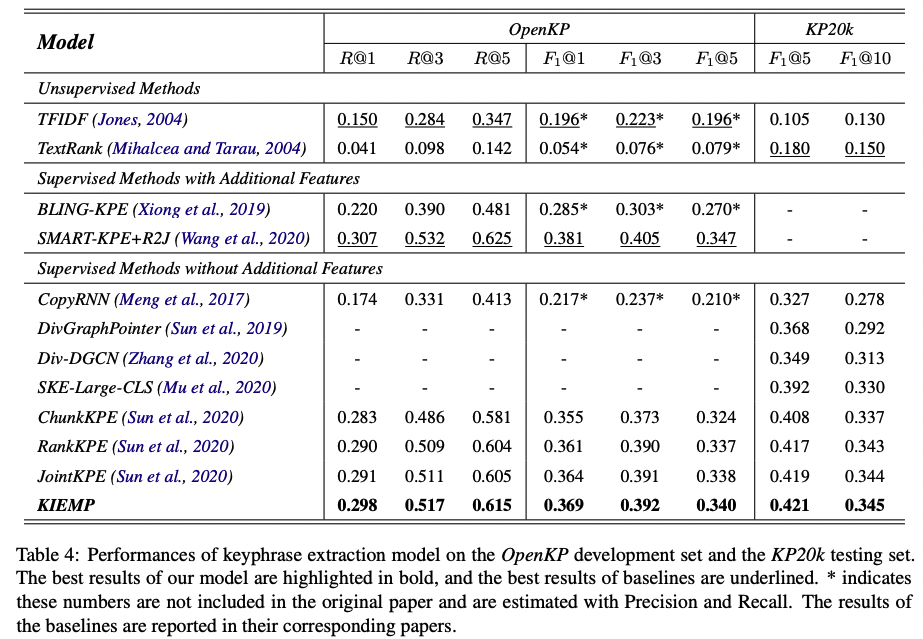
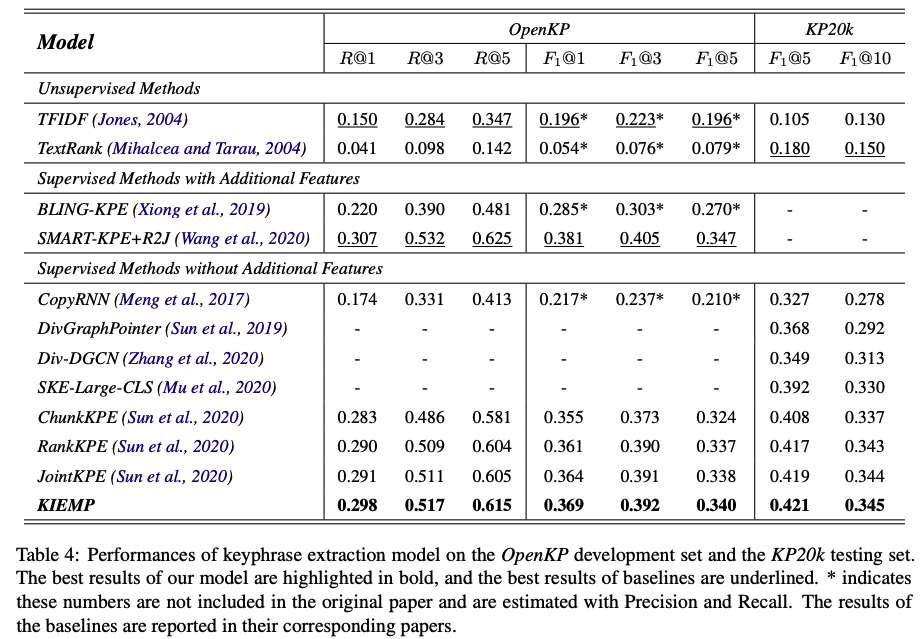
Baselines
- TextRank
- TFIDF
- CopyRNN
- BLING-KPE
- JointKPE
- SAMRT-KPE+R2J
- DivGraphPointer
- Div-DGCN
- SKE-Large-CLS
많은 모델을 사용하여 평가했다.... 각 모델에 대한 공부는 각자..
Evaluation Metrics
top k predicted keyphrases로 평가함. 이 논문에서는 marco-aveaged recall과 F-measure (F1)을 평가 지표로 사용했고, k는 1, 3, 5, 10을 사용했음.
Implementation

maximum document length: 512를 사용했음 (BERT의 limitations)
6개의 GeForce RTX 2080Ti GPUs를 사용했고, 31시간, 77시간 걸렸음.
Results and Analysis
Sensitivity of the Concept Dimension
유효성을 입증하기 위해 다른 concept dimensions로 실험을 진행함. latent concept representation dimension을 증가시킨다고 성능이 올라가지 않음. 반대로, 더 작은 dimension일 때 더 좋은 성능이 보임. 이러한 가장 큰 이유는 concept representation이 phrases or documents의 high-level conceptual information을 capture하기 때문임. 그러므로, KIEMP with concept consistency matching module은 주어진 document의 main topic과 유사한 keyphrases를 추출하는데에 초점이 맞춰져있음.
Case Study
제안하는 모델의 effectiveness를 설명하기 위해 different algorithms에 대한 case study를 진행함.

