1. 텍스트 마이닝
1.1 Word2Vec
- 정수 인코딩과 원핫 인코딩의 단점을 보완한 모델
Word Embedding
- 기존 정수 인코딩의 한계는 단어 사이의 연관성을 파악하기 어렵다는 것
- 원핫 인코딩(One-Hot Encoding)의 한계는 메모리가 많이 필요하고 희소표현 문제 발생
- 희소표현(sparse representation)이란?
-0과 1로만 이루어진 원핫 인코딩에서 단어의 개수가 많아지면 차원이 한없이 커지면서 0의 개수가 많아져서 계산이 어려워지는 문제 발생 - 밀집 표현(Dense Representation)
- One-hot encoding의 희소표현 문제를 보완- 벡터의 차원을 원하는 대로 설정할 수 있음 ex. 0을 소숫점 숫자(float)로 변환
- 데이터를 이용해서 표현을 학습함 => NN(Neural Network) 사용
Word2Vec
- NN 사용해서 Dense Representation 표현
- 단어 사이의 유사도를 사용해서 단어 맵핑
- 각각 종류별로 라벨링하는 것은 어려움이 있기 때문에 문장 안에서 자주 붙어 있는 표현 분석
Word2Vec의 두 가지 학습 방식
- CBOW(Continuous Bag of Words): 주변 단어를 활용해 중간에 있는 단어를 예측
- Skip-Gram: 중간 단어를 활용해 주변에 있는 단어를 예측
CBOW-Continuous Bag of Words
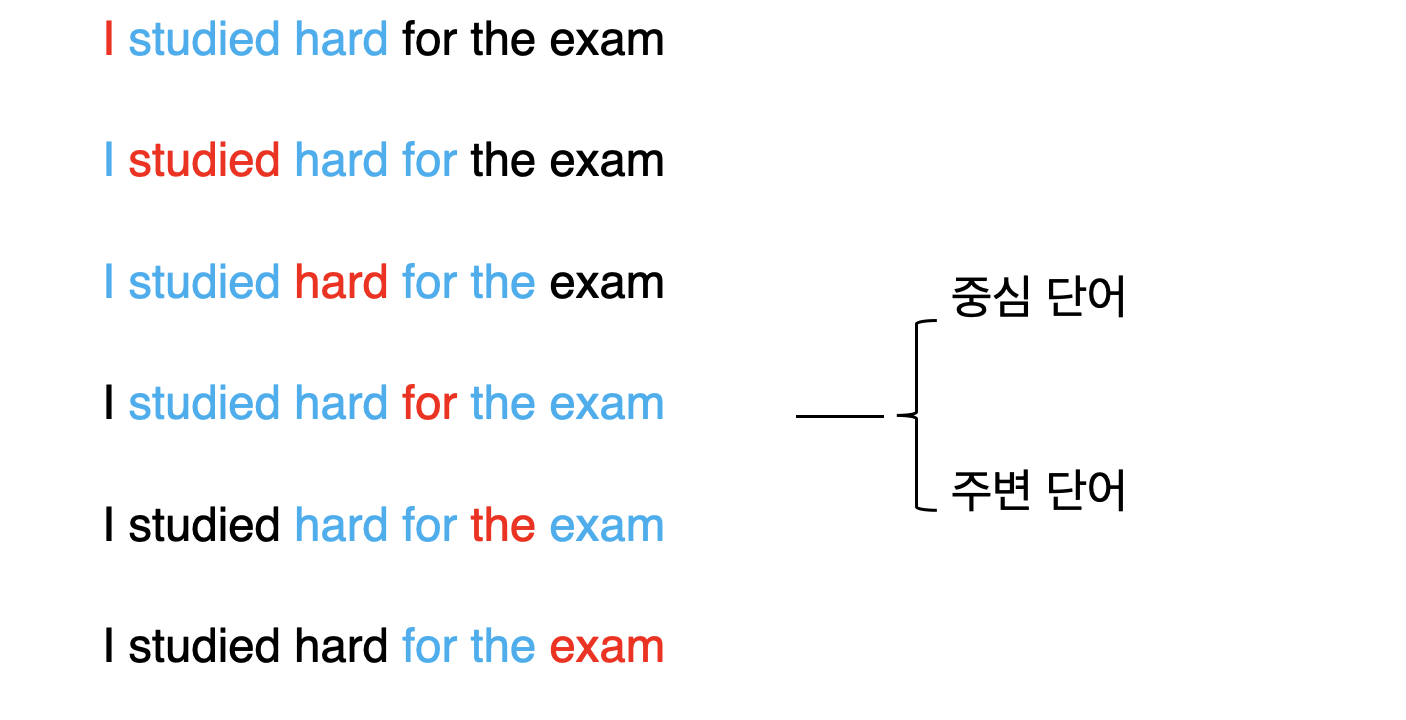
CBOW 모델의 신경망 구조
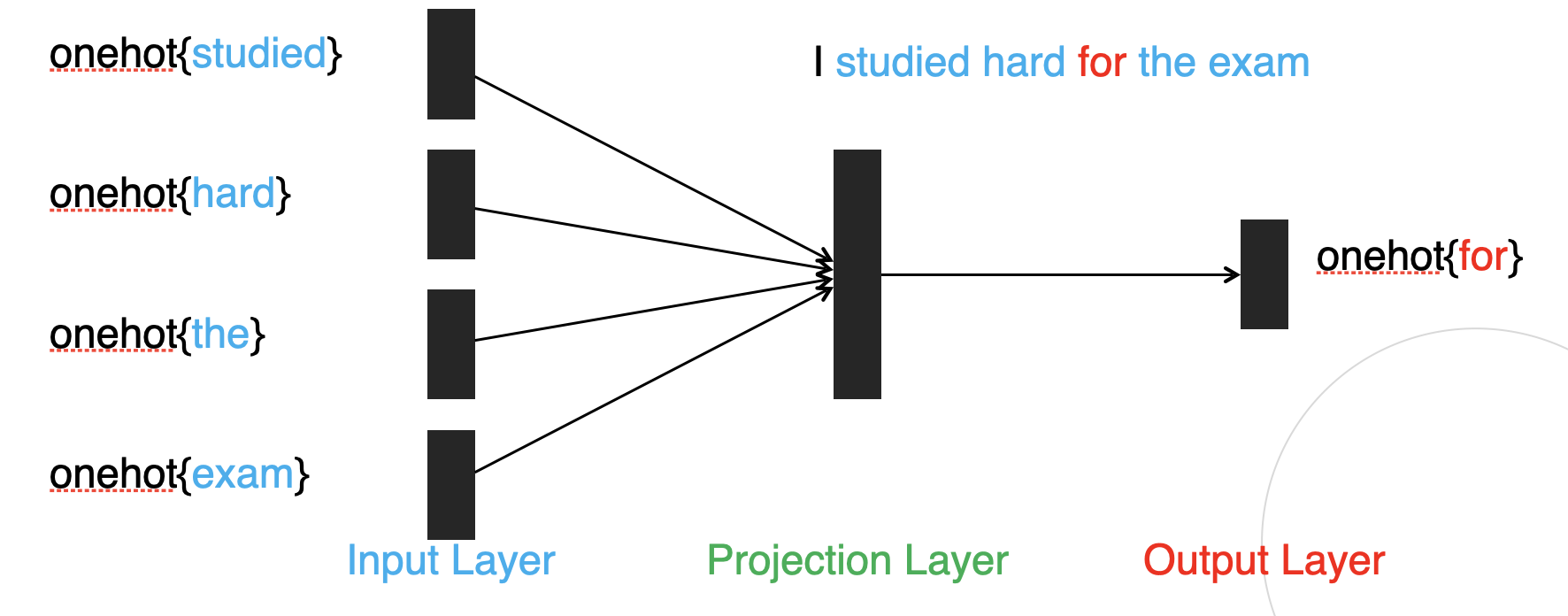
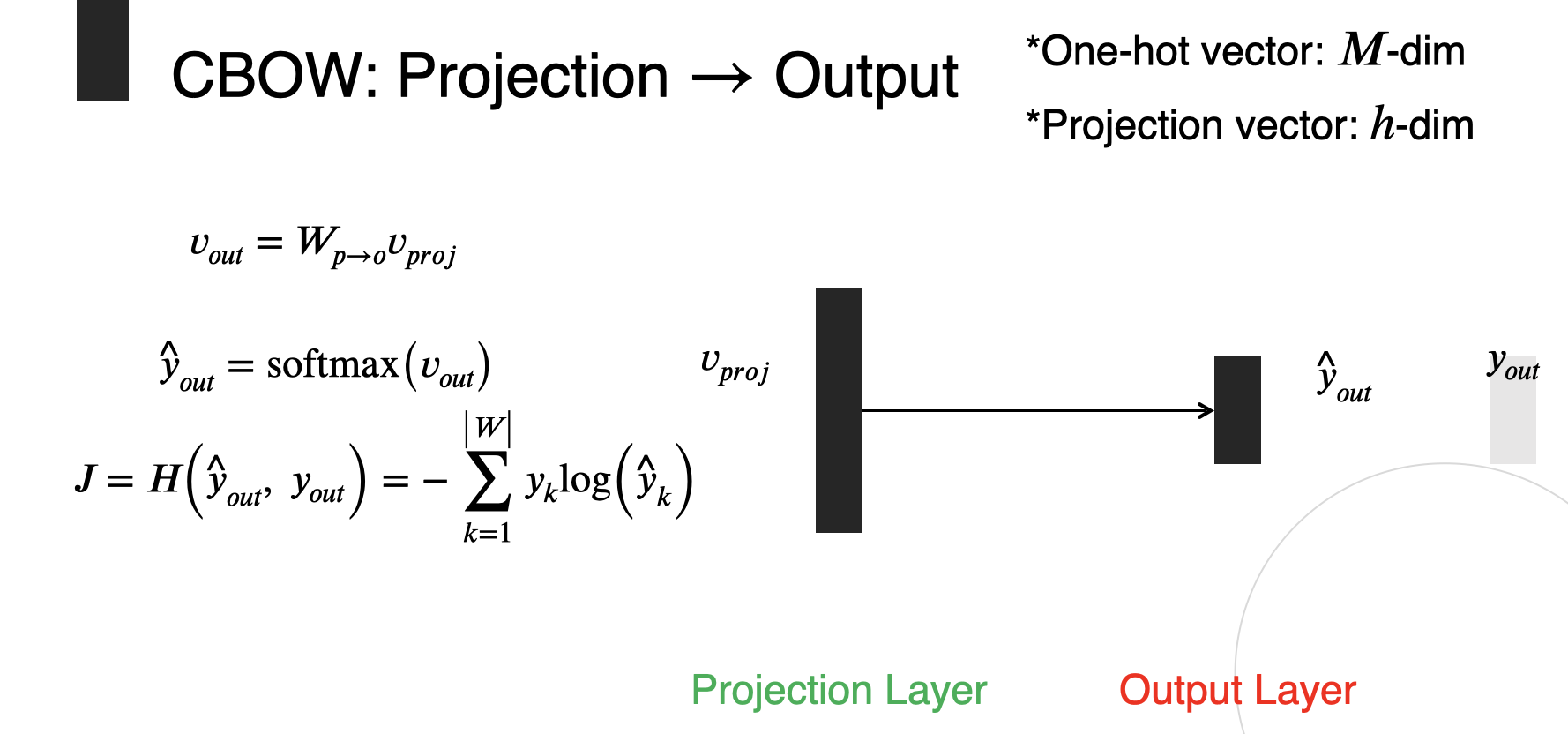
- 마지막 결과를 도출할 때 cross entrophy 사용하여 손실 값 계산
은닉층 뉴런의 수를 입력층의 뉴런 수보다 적게 하는 것이 중요한 핵심이다.
은닉층으로 정보를 담는 과정을 '인코딩', 은닉층의 정보로부터 원하는 결과를 얻는 작업을 '디코딩'이라고 한다.
- embedding vector 만들기
-은닉층(projection layer)은 중심단어의 dense representation으로 사용
-입력값에 가중치를 곱해준 후 그 값들의 산술평균을 구한 값이 은닉층 뉴런(dense representation)이 된다.

SkipGram-중심에서 주변으로
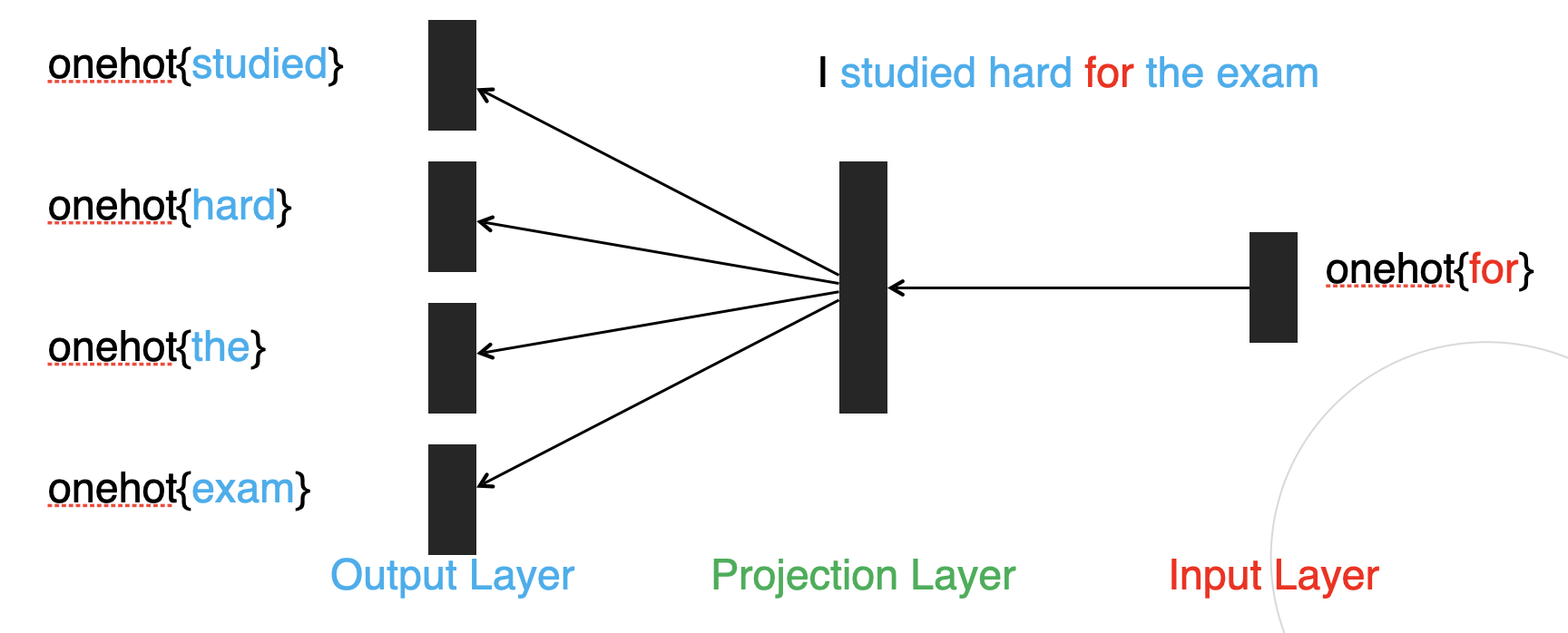
CBOW & SkipGram 차이
- CBOW: 주변에서 중심으로(input은 여러개, output은 한 개)
- SkipGram: 중심에서 주변으로(input은 한 개, output은 여러개)
1.2 NNLM:NN_Language Model
Recap) N_gram Language Model
- NNLM의 한계
-NNLM은 정해진 길이의 과거 정보만을 참조하므로 long-term 정보를 파악할 수 없다.
-문장의 길이가 달라질 경우 한계점이 명확하다.NNLM vs Word2Vec(CBOW)의 차이
-구조적인차이: NNLM은 앞에서부터 뒷 단어를 예측, CBOW는 주변에서 중심 예측
-연산량의차이: 연산량은 hidden layer의 개수에 따라 결정된다.
-예측 대상의 차이: NNLM은 다음 단어, CBOW는 중심 단어
1.3 SGNS: SkipGram with Negative Sampling
- SkipGram과 CBOW의 문제점
-단어 수가 많아질수록 예측 성능이 떨어진다.(유사도가 낮아지기 때문) - Negative Sampling
-Negative Sampling은 Word2vec 학습 과정에서 학습 대상의 단어와 관련이 높은 단어들에 보다 집중한다.
-SkipGram: 중심 단어로부터 주변 단어를 예측
-SGNS: 선택된 두 단어가 중심 단어와 주변 단어 관계인가?
1.4 GloVe
Co-occurence Matrix
- 단어의 동시 등장 행렬은 행과 열을 전체 단어 집합의 단어들로 구성하고, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬
I like studying math. I enjoy studying math.
| count | I | like | studying | math | enjoy |
|---|---|---|---|---|---|
I | 0 | 1 | 0 | 0 | 1 |
like | 1 | 0 | 1 | 0 | 0 |
studying | 0 | 1 | 0 | 2 | 1 |
math | 0 | 0 | 2 | 0 | 0 |
| enjoy | 1 | 0 | 1 | 0 | 0 |
Co-occurence Probability
- 동시 등장 확률은 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률
GloVe: Main Idea
- 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것
- Loss Function(손실함수)
: 주변단어가 k일 때 중심단어가 i일 확률
: 중심 단어 i의 임베딩 벡터
: 주변 단어의 임베딩 벡터
- 손실함수의 f 값이 커질수록 k단어가 등장했을 때 i가 중심단어일 확률이 높다는 의미, f 값이 작아질 수록 k가 등장했을 때 j가 중심단어일 확률이 높다는 의미
- 두 벡터()를 연산해서 스칼라 값()이 나오려면 벡터와 벡터를 내적을 시켜줘야 한다.
중심단어와 주변단어의 내적에 함수를 씌우면 확률값으로 쓰일 수 있다.
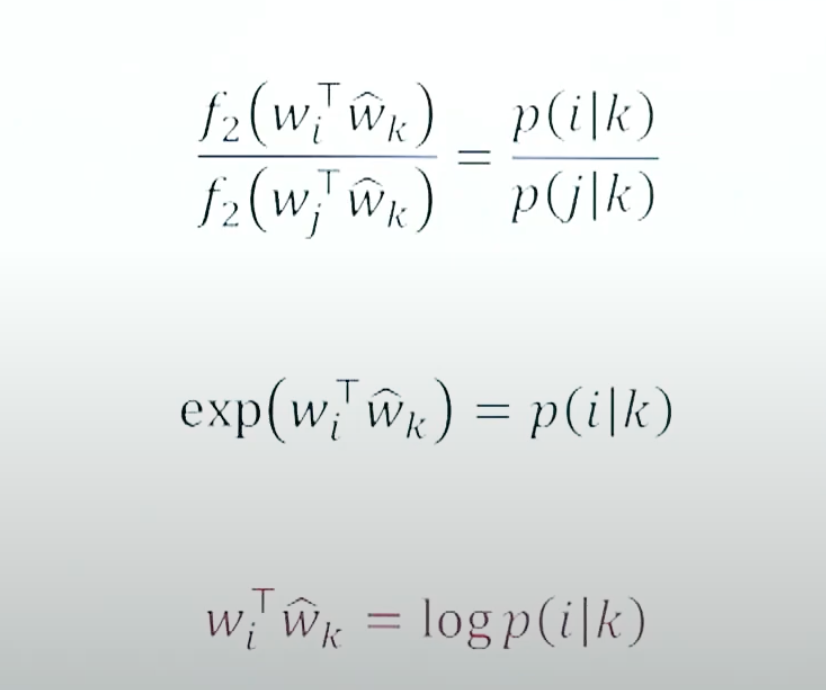
- 함수에 지수함수를 사용하면 두 번째 식이 도출되고, 그 식에 로그를 씌우면 맨 아래 식이 도출된다.
- 최종적으로 중심단어와 주변 단어의 내적을 구하면 확률에 로그를 취한 값과 같다.
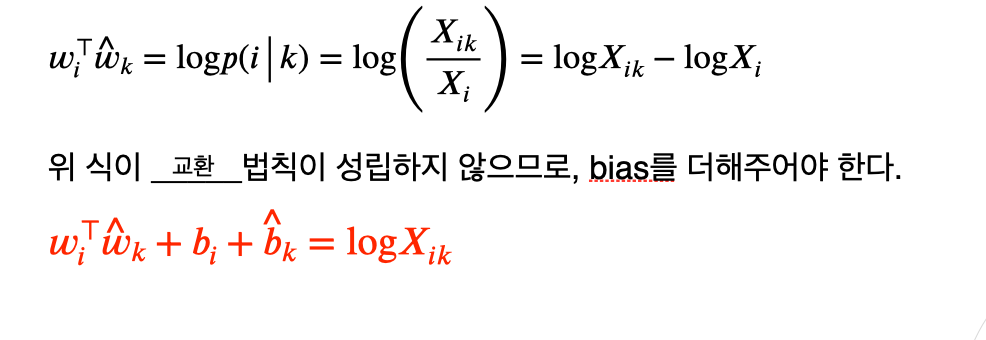
- GloVe Loss Function 문제점?
1) 값의 발산으로 인해 무한히 음수값이 도출 될 수 있음
-대안:
2) Co-occurrence 행렬 X가 sparse인 경우(단어 개수는 많은데 문장 개수가 적거나 occurency가 적어서 0값이 많을 경우)
-대안: weighted prob 사용 => 구현 단계에서 구체화 설명
1.5 FastText
- FaceBook에서 개발한 Word2Vec 알고리즘(n-gram word embedding 유형)
- 단어 단위에서 더 쪼갠 'subword' 개념 도입
-글자 단위의 n_gram
-mouse의 3-gram 표현: <mo, mou, ous, use, se>
-Then, mouse = <mo + mou + ous + use + se> - OOV(Out-of-Vocaulary)
-데이터셋으로 학습하는 단어의 수: 많아봐야 수만~수십만 개
-한 언어의 모든 단어 학습이 불가능
-모르는 단어(Out-of-Vocabulary, OOV)가 등장할 경우 대처 가능
-Word2Vec, GloVe에서는 처리 불가능
ex. breakthrough = break + through
모르는 단어를 아는 단어의 조합으로 파악 가능 - Rare words 처리에 강함
-빈도 수가 적은 단어들은 전처리 과정에서 제외하기도 함
-빈도 수가 적은 단어는 Word2Vec 임베딩 결과가 좋지 않음
-FastText는 Typo(오타)에 대해서도 강인함
1.6 사전훈련모델
- Pre-trained Word Embedding
-지도학습에서 training dataset이 적을 경우 underfitting 발생 가능
-이를 해결하기 위해 사전에 훈련되어 있는 model을 가져와 사용
-CBOW, GloVe, FastText 등으로 훈련된 사전 모델들이 존재 - Pre-trained Word Embedding: Procedure
1) 사전 훈련된 Word2Vec 데이터셋을 불러온다
2) 데이터셋의 특성과 자료형을 파악한다(visualization 등)
3) 원하는 Task 수행 - PCA(차원축소): Principal Component Analysis
-Word2Vec의 시각화를 위한 분석 방법
-3D-world에서 이해하기 - PCA for Visualiaztion
-Word2Vec 임베딩(100차원) -> 2차원으로 줄이기(평면 시각화)
*사진 출처 메타코드 '딥러닝을 이용한 자연어처리 입문강의'

머신러닝 딥러닝 학습기록