
1. 순환 신경망(RNN)
1.1 순환 신경망(RNN)이란?
- Recurrent Neural Network
- 시계열 데이터를 처리하기에 좋은 뉴럴 네트워크 구조
-음성 인식
-음악 생성기
-DNA 염기서열 분석
-번역기
-감정 분석RNN vs CNN
-CNN이 이미지 구역별로 같은 weight을 공유한다면,
-RNN은 시간 별로 같은 weight을 공유한다. 즉, 과거와 현재는 같은 weight을 공유한다.
1.2 First Order System
- 현재 시간의 상태가 이전 시간의 상태와 관련이 있다고 가정
-First-order system: 현재 상태()가 이전 시간의 상태와 관련이 있다는 것 - 이 시스템은 외부 입력 없이 자기 스스로 잘 돌아간다
- autonomous system: 자기 자신의 이전 상태에 대한 함수 - 현재 시간의 상태가 이전 시간의 상태와, 현재의 입력에 관계가 있는 경우
-상태: x, 입력: u
-식
1.3 State-Space Model
- 1차원 시스템의 모형:
- 모든 시간 에서 모든 상태 가 관측 가능한가?
-날씨 예측 ===> 중에 일부만 관측 가능함
-주가 예측
- 1차원 시스템의 모형 :
에서, 관측 가능한 상태만 모아 출력 => - State-Space Model의 함수 정리
-어떤 시스템을 해석하기 위한 3요소:
- => input
- => output
1.4 State-Space Model as RNN
- 상태 가 의미하는 것?
-는 이전까지의 상태와, 이전까지의 입력을 대표할 수 있는 압축본이라고 할 수 있다.
-상태 는 시계열로 들어오는 입력들을 최대한 상세히 표현할 수 있어야 한다. - State-Space Model에서 근사하는 함수는 2개:
- 함수 f와 h를 근사하기 위해서 뉴럴 네트워크를 사용한다.
- 뉴럴 네트워크에서 비선형 함수를 표현하는 방법:
- 뉴럴 네트워크 셋팅으로 함수 근사:
- 사용하는 parameter matrix는 총 5개
1.5 RNN: Basic Structure

1.6 RNN:Training
- ANN, CNN 에서처럼 back-propagation 이용
- Back-propagation through time(BPTT)
1.7 RNN: Problem Types
- Many-to-many
-input 여러개, ouput 여러개
-training 할 때는 실제 참값 여러개와의 차이를 보고 전체에 대한 loss를 계산해서 back-propagation
-(문장 단위 등)의 번역
-sequence to sequence 모델(seq2seq): many-to-one + one-to-many = many-to-many - Many-to-one
-output 1개, input 여러개
-시계열 예측 등의 '예측'에 많이 쓰임
ex. I love eating => pizza - One-to-many
-input 1개, output 여러개
-문장 등 '생성'에 쓰인다.
2. GRU & LSTM
2.1 RNN의 한계
- exploding/ vanishing gradient
-RNN 구조에서 state 에는 가 계속 곱해지게 된다.
-곱해지는 값이 1보다 크면 무한대로 수렴 => exploding gradient
-곱해지는 값이 1보다 작으면 0으로 수렴 => vanishing gradient - Exploding Gradient
-학습 도중 loss가 inf(이상한 값)이 뜰 경우, 학습이 더 이상 진행 불가능
-해결책: Gradient clipping - Vanishing Gradient
-학습 도중 파악이 어렵다: Gradient가 0이 되면, 학습종료인건지 V.G인지 구분하기 어렵다
-초기화를 간결하게 해주는 방법이 존재하지만 다른 네트워크 구조를 제안하는 것이 훨씬 편하다=> Gated RNNs: LSTM/ GRU
2.2 LSTM: Long short-term memory
- Gradient flow를 제어할 수 있는 "밸브" 역할을 한다고 생각하면 쉽다.
- state space의 입력, 상태, 출력 구조는 동일
-Gate 구조의 추가
-4개의 MLP 구조: input, forget, cell, output - RNN vs LSTM
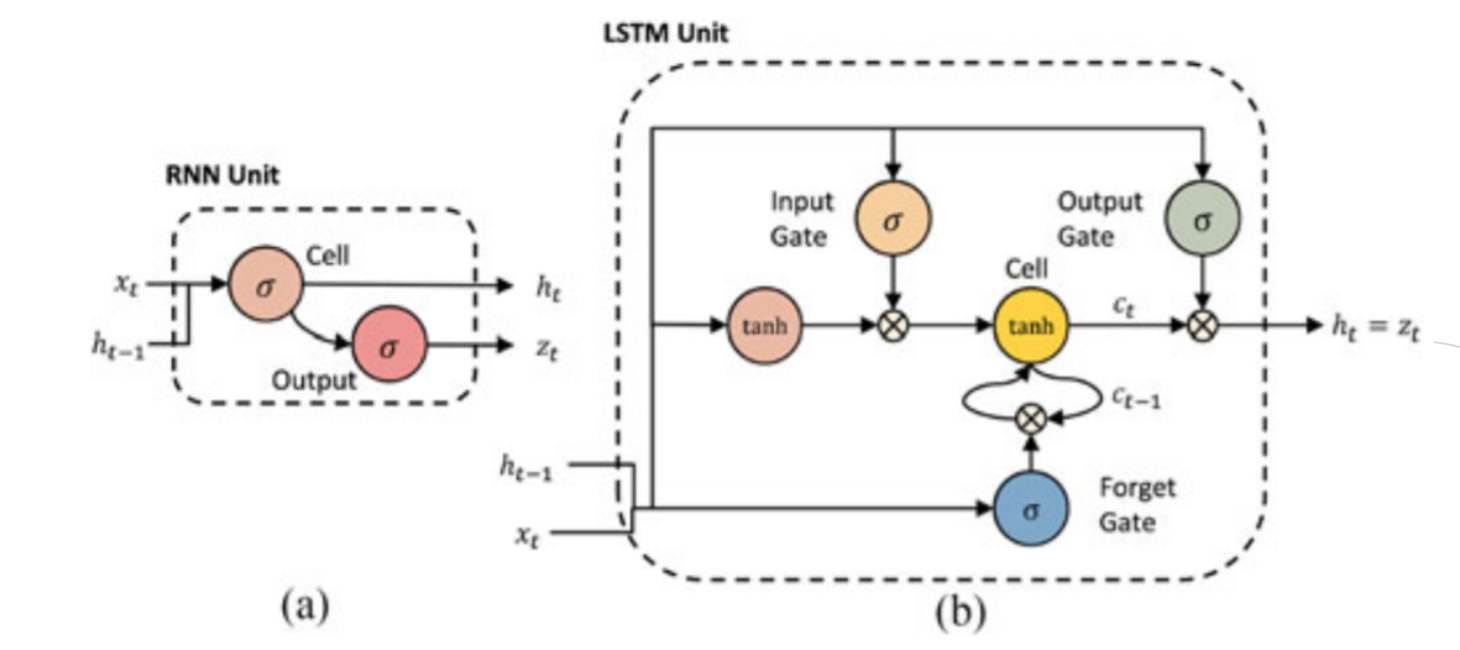
2.3 LSTM: Four Regulations
- step 1: 새로운 입력과 이전 상태를 참조해서 이 정보를 얼마의 비율로 사용할 것인지를 결정 or 얼마나 잊어버릴 것인가?
- step 2: 새로운 입력과 이전 상태를 참조해서 이 정보들을 얼마나 활용할 것인가 결정 + 어떤 정보를 활용할 것인가도 결정
- step 3: step1과 step2를 적절히 섞는다.
- step 4: 일련의 정보들을 모두 종합해서 다음 상태를 결정
2.4 GRU: Simplification of LSTM
- GRU는 LSTM의 간소화 버전: cell state가 없음
- LSTM보다 파라미터 수가 적으므로 training time이 절약된다.
- LSTM보다 성능이 좋은가? -> Task에 따라 천차만별
-But, LSTM과 GRU가 RNN보다는 확실한 성능을 보장한다.
*사진 출처 메타코드 '딥러닝을 이용한 자연어처리 입문강의'

머신러닝 딥러닝 학습기록