
1 언어 전처리 과정
1) 토큰화(Tokenization)
-
주어진 문장에서 '의미부여'가 가능한 단위를 찾는다.
- 구두점이나 특수문자를 전부 제거하는 작업만으로는 불가능한 경우가 있다. ex. 5:3의 승률 -
표준 토큰화(Treebank Tokenization)


-
문장 토큰화
-
한국어 토큰화의 어려움
-
주의❕ 패키지마다 토큰화의 방식에 차이가 있기 때문에 잘 확인해서 사용해야한다.
2) 정제(Cleaning) & 추출(Stemming)
정제
- 데이터 사용 목적에 맞추어 노이즈를 제거
- 대문자 vs 소문자
- 출현 횟수가 적은 단어의 제거- 길이가 짧은 단어, 지시(대)명사, 관사의 제거
추출
- 어간(stem): 단어의 의미를 담은 핵심
- 접사(affix): 단어에 추가 용법을 부여
- Porter Algorithm: 대표적인 stemming 방법
- 어간 추출 vs 표제어 추출
- 표제어 추출은 단어의 품사 정보를 포함하고 있음 => ex. bear는 명사, 동사의 뜻이 다름
-어간 추출은 품사 정보를 갖고 있지 않음
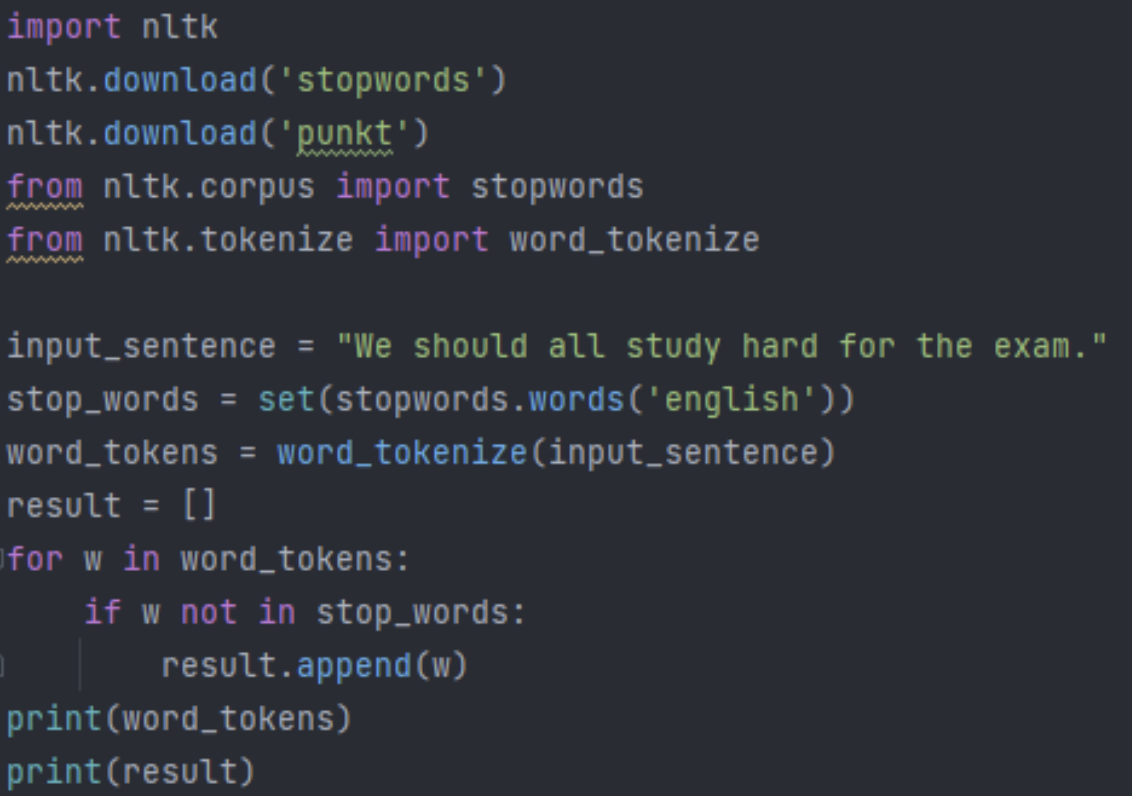
불용어(Stopword)
- 문장에서 대세로 작용하지 않는, 중요도가 낮은 단어 제거
- 불용어 제거 방법
1. 불용어(stopword) 목록을 받아온다.- 정제할 문장을 토큰화 한다.
- 단어가 불용어 목록에 없는 경우 정제결과에 추가
5) 인코딩
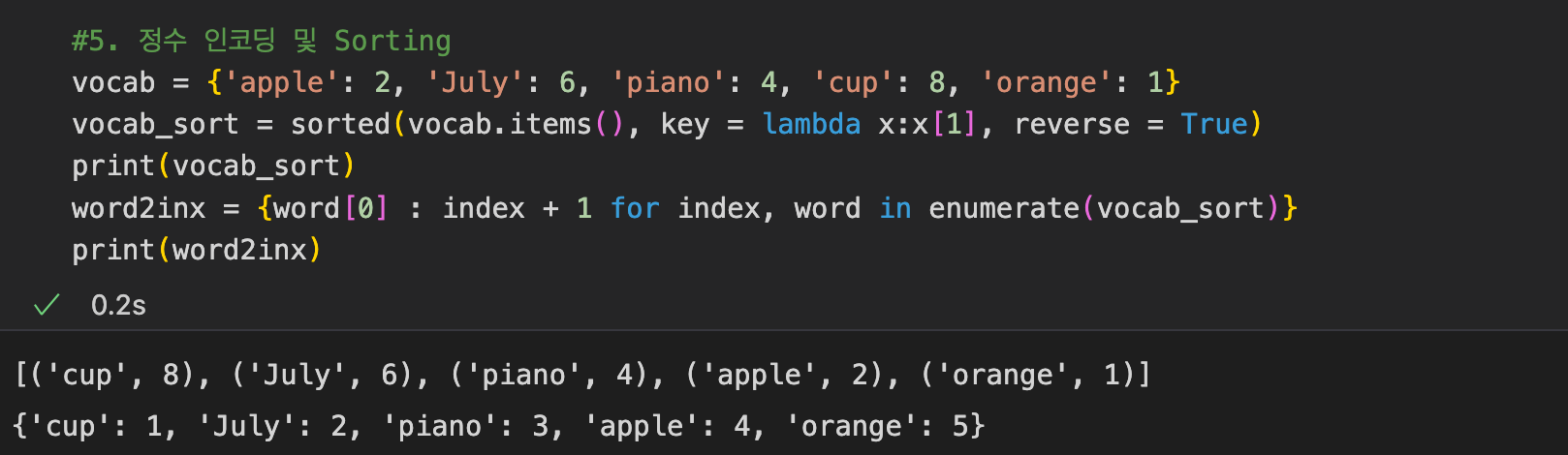
- 정수 인코딩(Integer-Encoding) setp 1 : Dictionary
1. 문장의 토큰화 - 불용어 및 대문자 제거 과정을 거친다.- 빈 단어 dictionary vocab={} 리스트를 만든다.
- 토큰화된 각 단어에 대해서:
단어가 vocab에 속하지 않는 경우 vocab[단어]=0
단어가 vocab에 속한 경우 vocab[단어]+=1
- 정수 인코딩(Integer-Encoding) step 2 : 빈도순 정렬
- Padding(Zero-padding)
인코딩의 길이를 맞추기 위해 빈 자리에 0을 채워준다.

- One-hot Encoding
-0과 1로만 이루어 지도록 인코딩
-메모리를 많이 차지한다는 문제점이 있다. - Word2vec Encoding
-단어의 유사성을 인코딩에 반영
-인코딩 벡터가 비슷하다 = 단어가 유사하다 - TF-IDF
-단어들의 중요한 정도를 가중치로 매기는 방법
-TF: 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값
-IDF: 단어 자체가 문서군 내에서 자주 사용되는 빈도를 나타내는 값의 역수
2. 통계 기반 언어 모델
- Markov Chain
- count-based approximation- 문장의 개수를 기반으로 통계를 내기 때문에 문장이 희소한 경우 sparcity problem 발생
- N-gram Language Model
- sparcity problem을 해결하는 모델- 특정 단어를 기준 앞의 n개의 단어만 참조
- 정확도는 떨어질 수 있다.
- 한국어 언어 모델
- 한국어는 단어의 순서가 달라도 의미가 같은 경우가 많다.- 통계 기반 언어 모델의 경우 순차적으로 문장의 단어를 탐색하며 의미를 분석하기 때문에 한국어에 적용하기 어렵다는 한계가 존재
3. 유사도 분석
벡터 유사도
-
Cosine Metric
- 두 벡터의 내적 한 결과를 두 벡터의 크기로 나눠주면 cosineθ
가 나온다.
- 벡터의 유사도가 크면 1, 작으면 -1 -
벡터의 내적과 norm
- 백터의 내적: 두 벡터의 성분끼리 곱한 후 더한다.
- 벡터의 norm: 성분의 제곱을 더한 후 제곱근을 씌운다.
- 코사인 유사도: 벡터의 내적 / 벡터 norm의 곱 -
문장 유사도 분석
- Bag of Words: Bag of Words란 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법 -
Levenshtein Distance
- 레벤슈타인 거리는 편집 거리라고도 하는데, 두 문자열이 얼마나 다른지를 나타내는 거리 중 하나이다- 단어 A를 단어 B로 수정하기 위한 최소 횟수

- 단어 A를 단어 B로 수정하기 위한 최소 횟수
-
Jaccard Distance
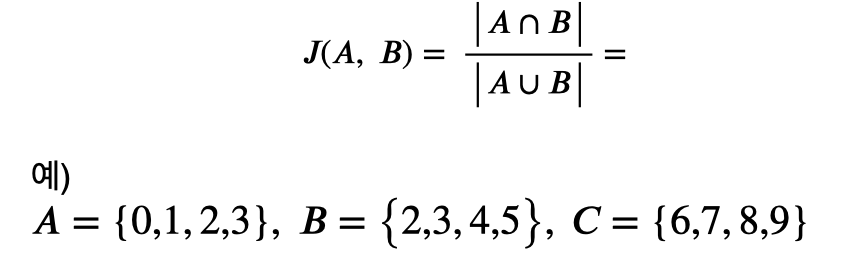
*사진 출처 메타코드 '딥러닝을 이용한 자연어처리 입문강의'

머신러닝 딥러닝 학습기록