확률적 경사 하강법
여기서 말하는 확률적은 무작위, 랜덤을 말한다.
랜덤으로 경사를 내려간다. 라고 표현할 수 있다.
모델이 데이터로부터 학습하고 훈련 데이터셋에서 랜덤으로 데이터를 뽑아 그 데이터 포인트에 대한 손실 함수의 기울기를 이용하여 하강한다.
모든 샘플을 다 사용하고도 도달하지 못했다면 다시 처음부터 훈련 세트에 모든 샘플 데이터를 넣고 랜덤하게 뽑아 실행한다.
그리고 모든 훈련 세트를 사용하고 다시 처음부터 할 때 그 횟수를 에포크(Epoch)라고 한다.
그리고 하나씩 랜덤하게 선택해서 하는 것이 아닌 몇 개의 샘플을 선택해서 하는 방식을 미니배치 경사 하강법이라고 한다.
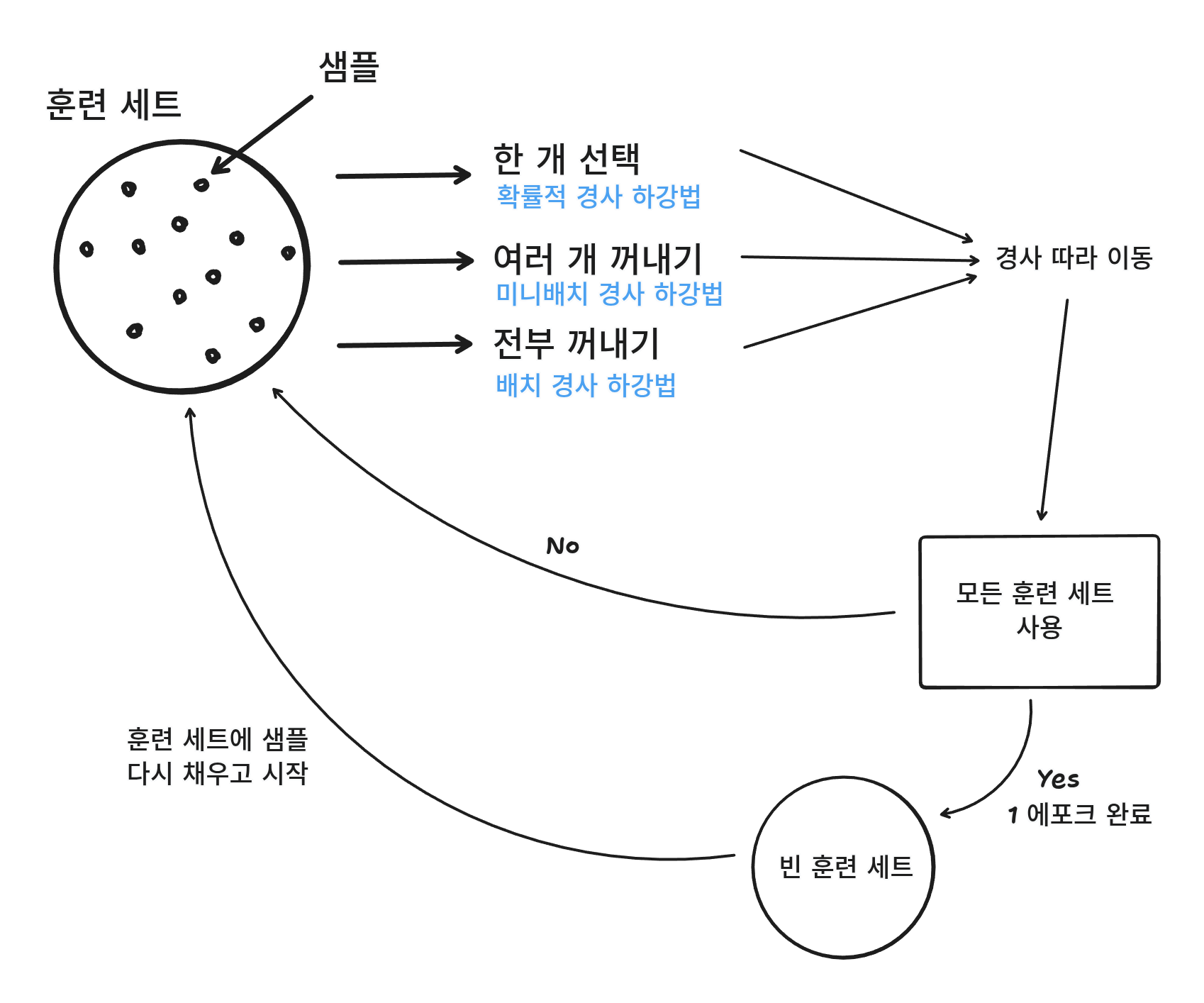
신경망에서 확률적 경사 하강법을 많이 사용하는데, 보통 신경망을 사용하는 경우 데이터가 너무 많아 한 번에 모든 데이터를 사용하여 학습할 수 없다.
그래서 이럴 때 미니배치 경사 하강법을 사용한다.
손실 함수
손실함수는 머신러닝의 알고리즘이 잘 된건지 아닌지 측정하는 기준이다.
비용 함수
비용 함수는 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합을 말한다.
로지스틱 손실 함수
예측 값과 타깃(1)을 곱하고 음수로 바꾼다.
만약 타깃값이 0일 경우에는 1 - 예측값을 수행한다.
만약 정답이 1이고 예측이 0.9, 0.3, 0.8, 0.2 일때
| 예측 | 정답(타깃) | 결과 | 점수 |
|---|---|---|---|
| 0.9 | 1 | -0.9 | -0.9 |
| 0.3 | 1 | -0.3 | -0.3 |
| 0.2 | 0 | 0.8 | -0.8 |
| 0.8 | 0 | 0.2 | -0.2 |
이렇게 나오게 된다.
이러면 -0.9, -0.8이 손실이 낮고, -0.3, -0.2가 손실이 높다는 것을 알 수 있다.
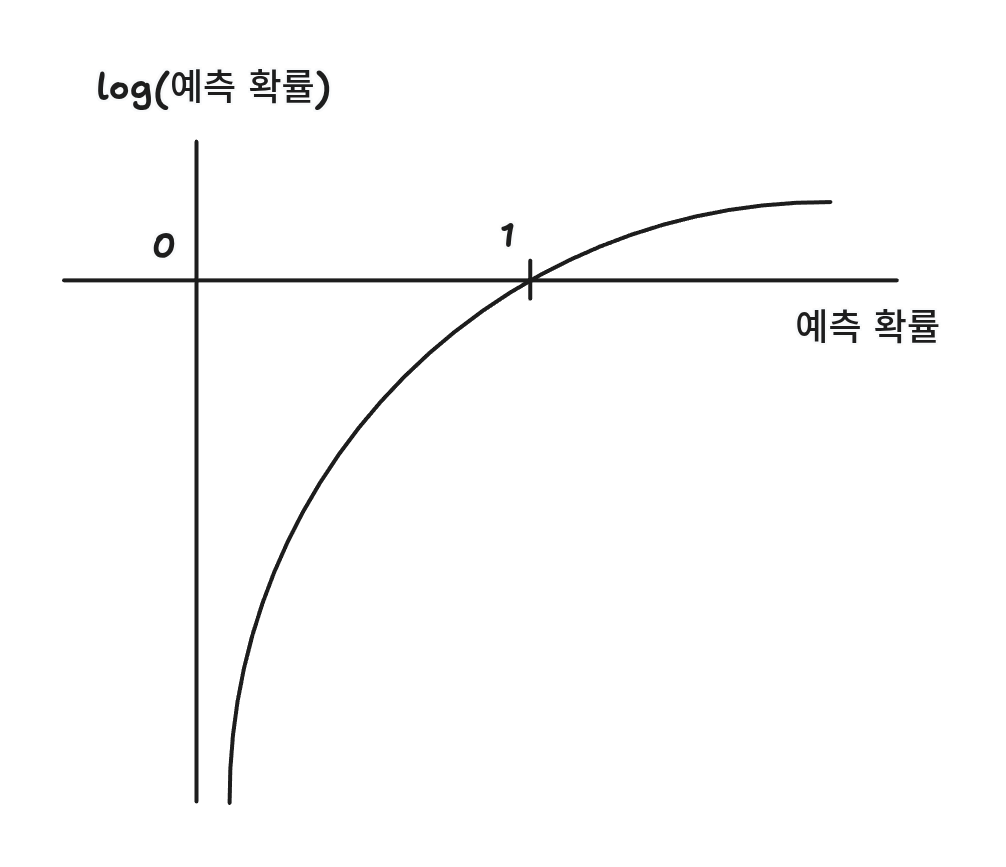
이 손실 함수를 로지스틱 손실 함수, 이진 크로스엔트로피 손실 함수라고 부른다.
구현
import pandas as pd
from sklearn.model_selection import train_test_split
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']]
fish_target = fish['Species']
X_train, y_train, X_test, y_test = train_test_split(fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(X_train)
X_train_scaled = ss.transform(X_train)
y_train_scaled = ss.transform(y_train)
from sklearn.linear_model import SGDClassifier
# 학습하고 정확도 보기
sc = SGDClassifier(loss='log_loss', max_iter=100, random_state=42)
sc.fit(X_train_scaled, X_test) # 훈련 완로 1 Epoch
print(sc.score(X_train_scaled, X_test)) # 0.7226890756302521
print(sc.score(y_train_scaled, y_test)) # 0.675
sc.partial_fit(X_train_scaled, X_test) # 이어서 학습 2 Epoch
print(sc.score(X_train_scaled, X_test)) # 0.8991596638655462
print(sc.score(y_train_scaled, y_test)) # 0.925에포크 & 과대 적합 & 과소 적합
에포크: 학습 횟수
과대 적합: 훈련 데이터에 너무 맞춰져 테스트 데이터를 전혀 예측 못하는 경우
과소 적합: 훈련 데이터를 잘 학습하지 못해 훈련 점수, 테스트 점수 모두 낮거나 훈련 점수보다 테스트 점수가 더 높은 경우
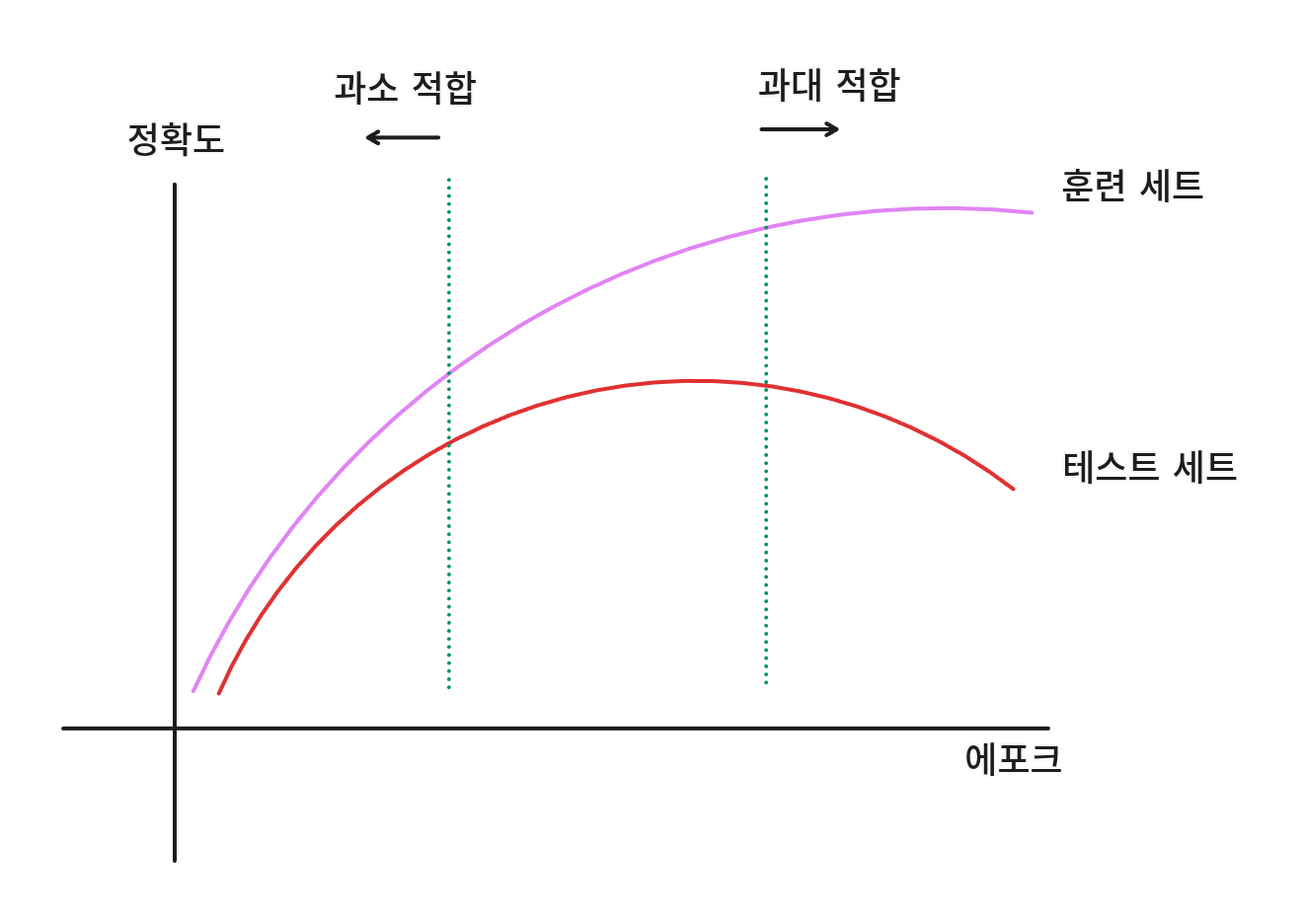
과대 적합이 되게 전에 적당한 선에서 점추는 것을 조기 종료라고 한다.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=100, random_state=42)
train_scores = []
test_scores = []
classes = np.unique(X_test)
# 300회 학습
for _ in range(300):
sc.partial_fit(X_train_scaled, X_test, classes=classes)
train_scores.append(sc.score(X_train_scaled, X_test))
test_scores.append(sc.score(y_train_scaled, y_test))
plt.plot(train_scores, color='purple')
plt.plot(test_scores, color='red')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()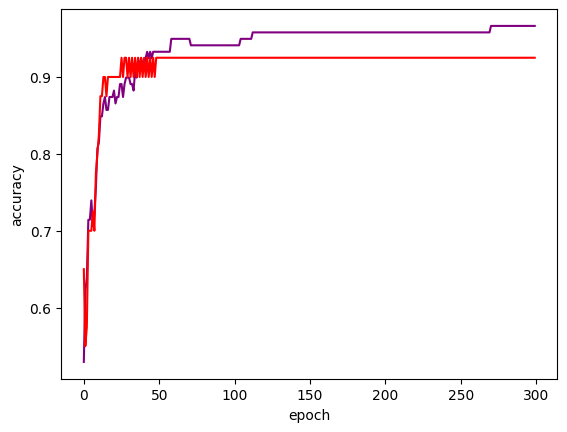
학습을 해도 더이상 변화하지 않거나 오히려 떨어지는 구간이 있다.
그렇게 되기 전에 딱 멈추는 것이다.
