만약 K-최근접 이웃을 통해서 예측하려는 값의 클래스 확률을 구한다고 한다면
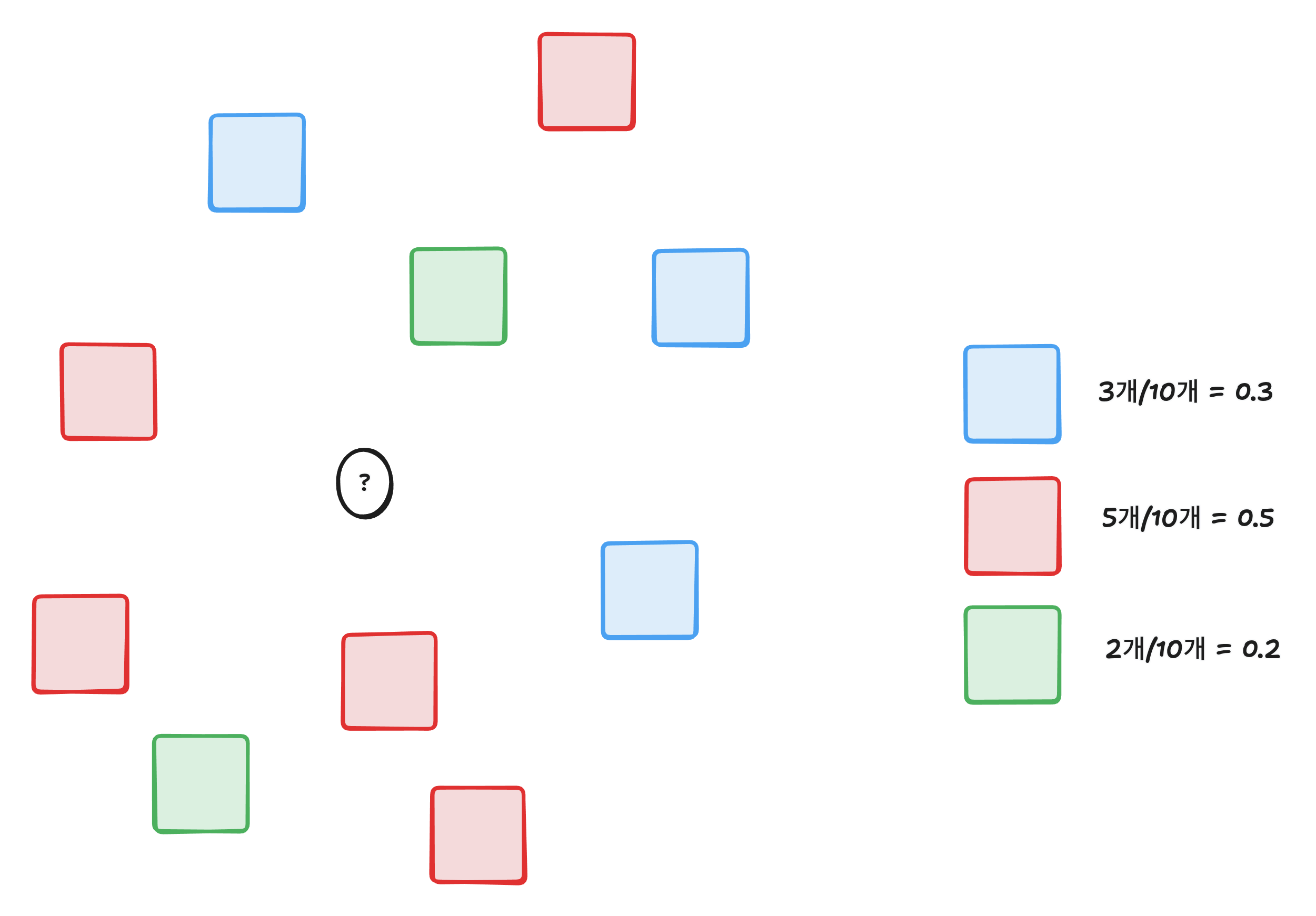
이런식으로 구할 수 있다.
데이터 준비
import pandas as pd
# 데이터 불러오기
fish = pd.read_csv('https://bit.ly/fish_csv_data')
display(fish.head())
# 생성 종류
print(fish['Species'].unique())
# ['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt']| Species | Weight | Length | Diagonal | Height | Width | |
|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 29.0 | 34.0 | 12.4440 | 5.1340 |
# 학습 데이터, 목표 데이터 분리
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']]
fish_target = fish['Species']데이터 전처리
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 분리
X_train, y_train, X_test, y_test = train_test_split(fish_input, fish_target, random_state=42)
# 표준화 전처리
ss = StandardScaler()
ss.fit(X_train)
X_train_scaled = ss.transform(X_train)
y_train_scaled = ss.transform(y_train)K-최근접 이웃
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(X_train_scaled, X_test)
print(kn.score(X_train_scaled, X_test))
print(kn.score(y_train_scaled, y_test))
# 0.8907563025210085
# 0.85타깃 데이터에 2개 이상의 클래스가 포함된 것을 다중 분류(multi-class classfication)이라고 한다.
사이킷런의 분류 모델은 predict_proba()를 통해 클래스별 확률값을 반환한다.
import numpy as np
proba = kn.predict_proba(y_train_scaled[:5])
np.round(proba, decimals=4)
array([[0. , 0. , 1. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. , 1. , 0. ],
[0. , 0. , 0. , 1. , 0. , 0. , 0. ],
[0. , 0. , 0.6667, 0. , 0.3333, 0. , 0. ],
[0. , 0. , 0.6667, 0. , 0.3333, 0. , 0. ]])여기서 각 배열은 데이터를 말하고 그 안의 원소들은 클래스별 확률을 말한다.
즉 1번째 데이터는 2번 클래스일 확률이 100%라는 것이다.
distances, indexes = kn.kneighbors(y_train_scaled[3:4])
print(X_test.iloc[indexes[0]])이거에 대한 결과값으로
Roach
Perch
Perch
이렇게 나왔는데
이 의미는 3개의 이웃이 저 3개라는 것이고 확률을 1/3, 2/3이 나온다.
로지스틱 회귀
로지스틱 회귀는 이름이 회귀지만 분류 모델이다.
수식으로 나태내면 아래와 같다.
여기서 a, b, c, d, e, f는 가중치고 f는 절편이다.
그리고 여기서 z의 값이 음수일 때 0 아니면 1이 되도록 하는 방법이 시그모이드 함수다.
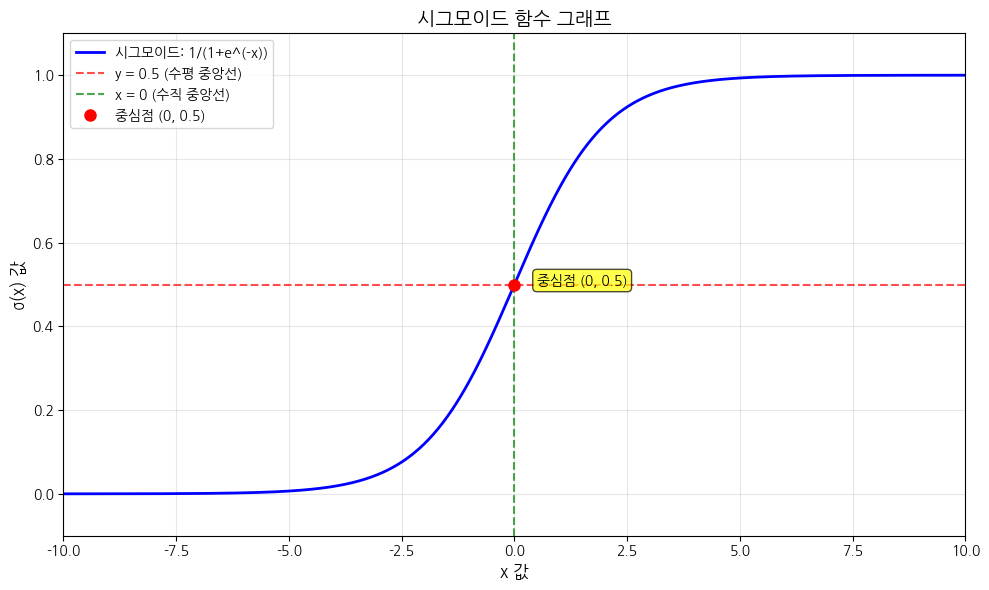
모든 값은 0 ~ 1 사이에 있기 때문에 확률로 계산할 수 있다.
값이 정확이 0.5인 경우에 사이킷런에서는 음성 클래스로 판단한다.
이진분류
이진분류는 말 그대로 0, 1로 분류하는 것을 말한다.
이것이 예인지, 아니오인지를 구별한다.
여기서는 도미(Bream), 빙어(Smelt)를 분류한다.
# 도미, 빙어 데이터만 추출
bream_smelt_indexes = (X_test == 'Bream') | (X_test == 'Smelt')
train_bream_smelt = X_train_scaled[bream_smelt_indexes]
test_bream_smelt = X_test[bream_smelt_indexes]
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, test_bream_smelt)
# 예측값
print(lr.predict(train_bream_smelt[:5]))
# 각 데이터 예측값 확률
print(lr.predict_proba(train_bream_smelt[:5]))
['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
[[0.99760007 0.00239993]
[0.02737325 0.97262675]
[0.99486386 0.00513614]
[0.98585047 0.01414953]
[0.99767419 0.00232581]]각 가중치를 보면 다음과 같은데
[[-0.40451732, -0.57582787, -0.66248158, -1.01329614, -0.73123131]]
[-2.16172774]이는 다음 방정식으로 사용할 수 있다.
로지스틱 휘귀에서 다중 분류
로지스틱 회귀에서 규제를 제어하는 매개변수는 C다.
aplha와는 반대로 수치가 작을수록 규제가 커진다.
lr = LogisticRegression(C=20, max_iter=1000)
# 학습
lr.fit(X_train_scaled, X_test)
# 훈련 데이터 정확도
print(lr.score(X_train_scaled, X_test))
# 테스트 데이터 정확도
print(lr.score(y_train_scaled, y_test))
# 테스트 데이터 예측
print(lr.predict(y_train_scaled[:5]))
# 테스트 데이터 각 클래스 확률
proba = lr.predict_proba(y_train_scaled[:5])
print(np.round(proba, decimals=3))
코딩 공부하는 사람