이번에는 고급 옵티마이저를 적용한다.
데이터 불러오기
import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)모델 생성
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Input(shape=(28,28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model모델 확인
model = model_fn()
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________학습
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=5, verbose=5)그래프
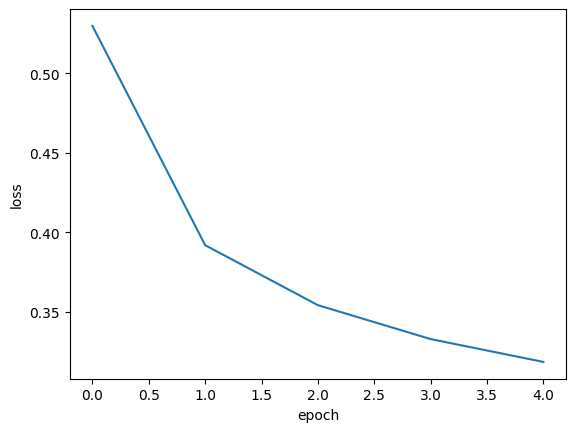
학습 할 때마다 loss가 줄어들고
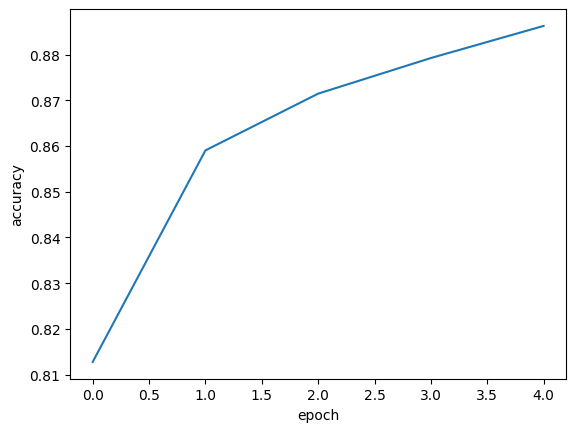
accuracy는 상승한다.
그렇다고 무턱대고 epoch를 늘리면
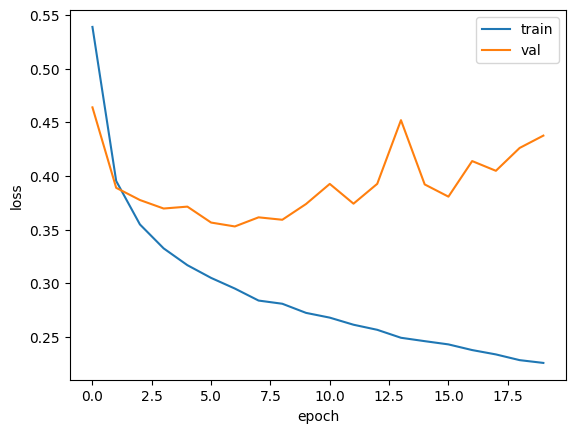
이렇게 과대적합이 일어나게 된다.
하지만 옵티마이저를 Adam으로 변경하면 적응적 학습률 때믄에 학습률의 크기를 조정하여
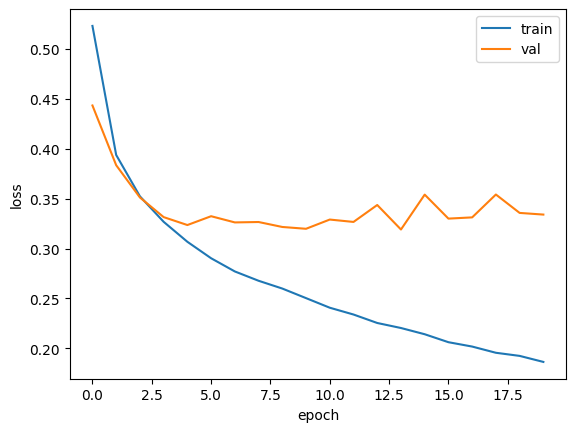
이전보다는 과대적합이 훨씬 줄게 된다.
드롭아웃
드롭아웃은 층에 있는 일부 뉴런을 랜덤하게 꺼서 과대적합을 맏는 방법입니다.
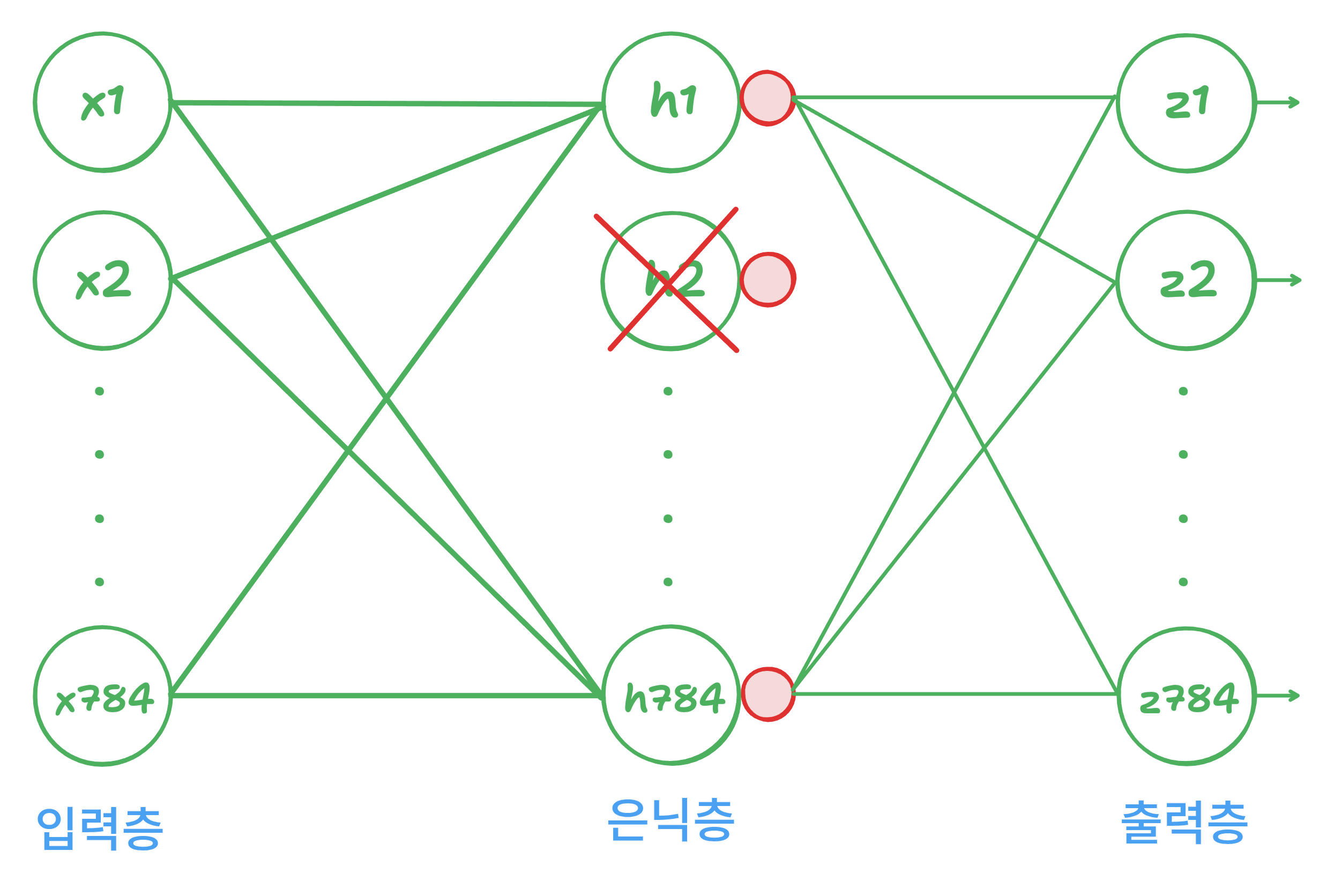
이런식으로 랜덤하게 드롭하게 된다.
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_9 (Flatten) (None, 784) 0
dense_18 (Dense) (None, 100) 78500
dropout (Dropout) (None, 100) 0
dense_19 (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________일부 뉴런의 출력을 0으로 만들지만 전체 출력 배열의 크기를 바꾸지는 않는다.
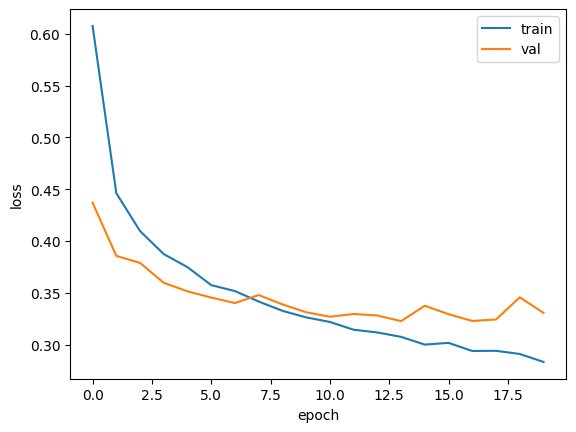
Dropout을 넣으니 훨씬 더 좋아졌다.
하지만 20번이나 훈련했기 때문에 과대적합이 일어났다.
모델 저장
# 모델의 구조와 파라미터를 함께 저장
model.save('model-whole.keras')
# 모델의 파라미터만 저장
model.save_weights('model.weights.h5')모델 불러오기
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model.weights.ht')가중치만 불러오는 경우에는 구조를 만들고 저장된 파라미터를 읽어서 사용한다.
콜백
훈련 과정 중간에 작업을 수행하는 것이다
예를 들어 save_best_only=True 가 있는데
이것은 원래 매 에포크마다 저장하는 모델을 가장 낮은 검증 손실을 만드는 모델을 저장하도록 하는 함수다.
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(
train_scaled,
train_target,
epochs=20,
verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb]
)early_stopping은 patience의 개수만큼 더 좋아지지 않으면 멈춘다.

코딩 공부하는 사람