이전에는 어떻게 보면 input, output만 만들어서 사용했다.
이제는 심층 신경망을 만들어 보자.
데이터 준비
import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0 # 픽셀 값 0~1로 정규화
train_scaled = train_scaled.reshape(-1, 28*28) # 1차원 배열로 변경
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)심층 신경망 추가
모델의 대략적인 구조는 아래와 같다.
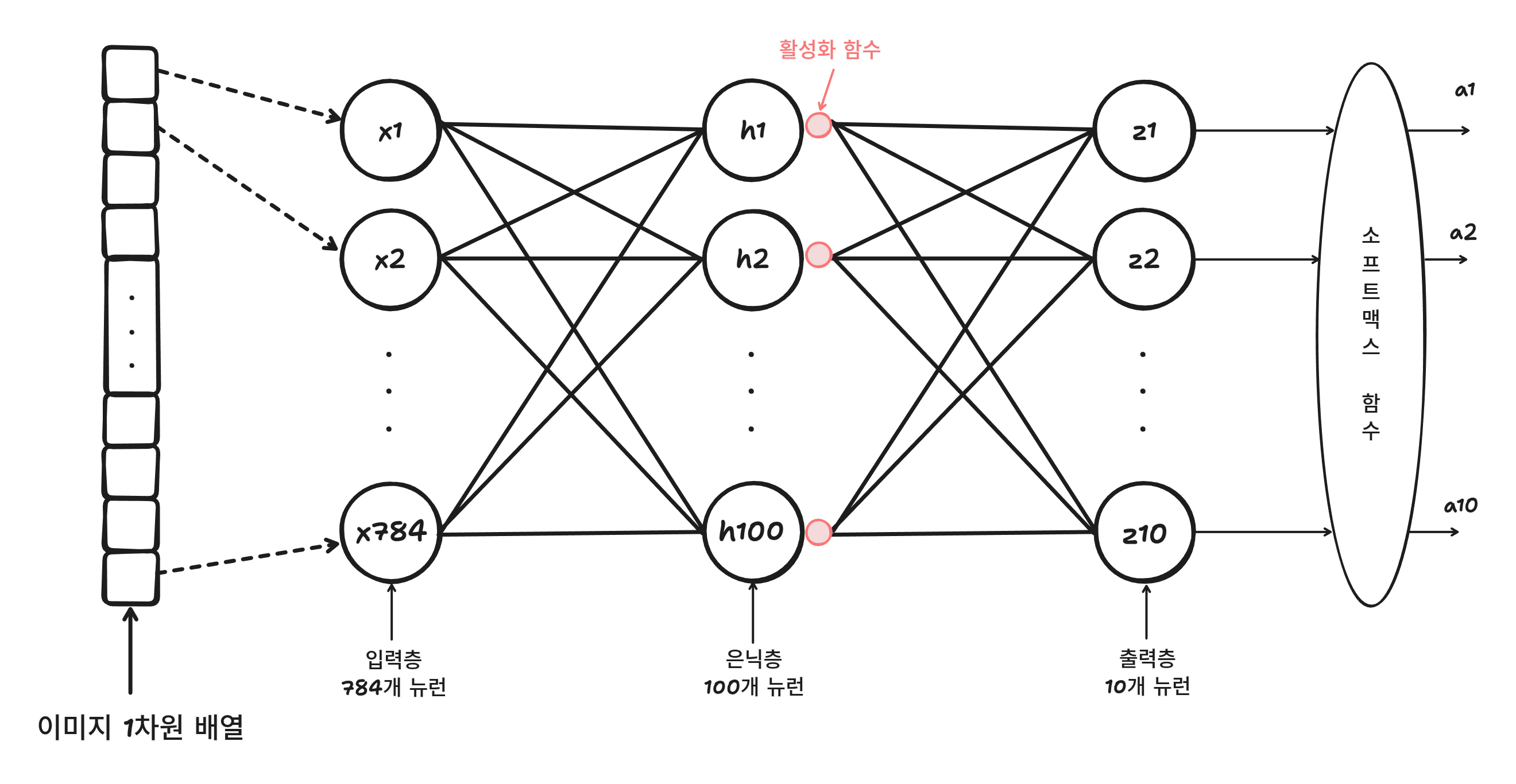
입력층과 출력층 사이에 있는 모든 층을 은닉층이라고 한다.
ReLU, softmax, sigmoid도 활성화 함수다.
보통 이진 분류에서는 sigmoid, 다중 분류에서는 softmax를 사용한다.
이에반해 은닉층에서 사용하는 활성화 함수는 비교적 자유롭다.
은닉층에 활성화 함수?
단순하게 계산하게되면 이전 뉴런에서 계산한 것을 그대로 다음 뉴런에서 계산한다면 단순히 합치는 것이다.
여기서 보면 b가 아무런 의미가 없게 된다.
이런식으로 활성화 함수를 사용하면 조금씩 비선형적으로 비틀게되어 나름의 역할을 할 수 있게 되는 것이다.
sigmoid
많이 사용하는 함수인 sigmoid 함수를 보자.
출력값 z를 0~1 사이로 압축한다.
심층 신경망 만들기
inputs = keras.layers.Input(shape=(784,)) # 입력층
dense1 = keras.layers.Dense(100, activation='sigmoid') # 은닉층
dense2 = keras.layers.Dense(10, activation='softmax') # 출력층
model = keras.Sequential([inputs, dense1, dense2])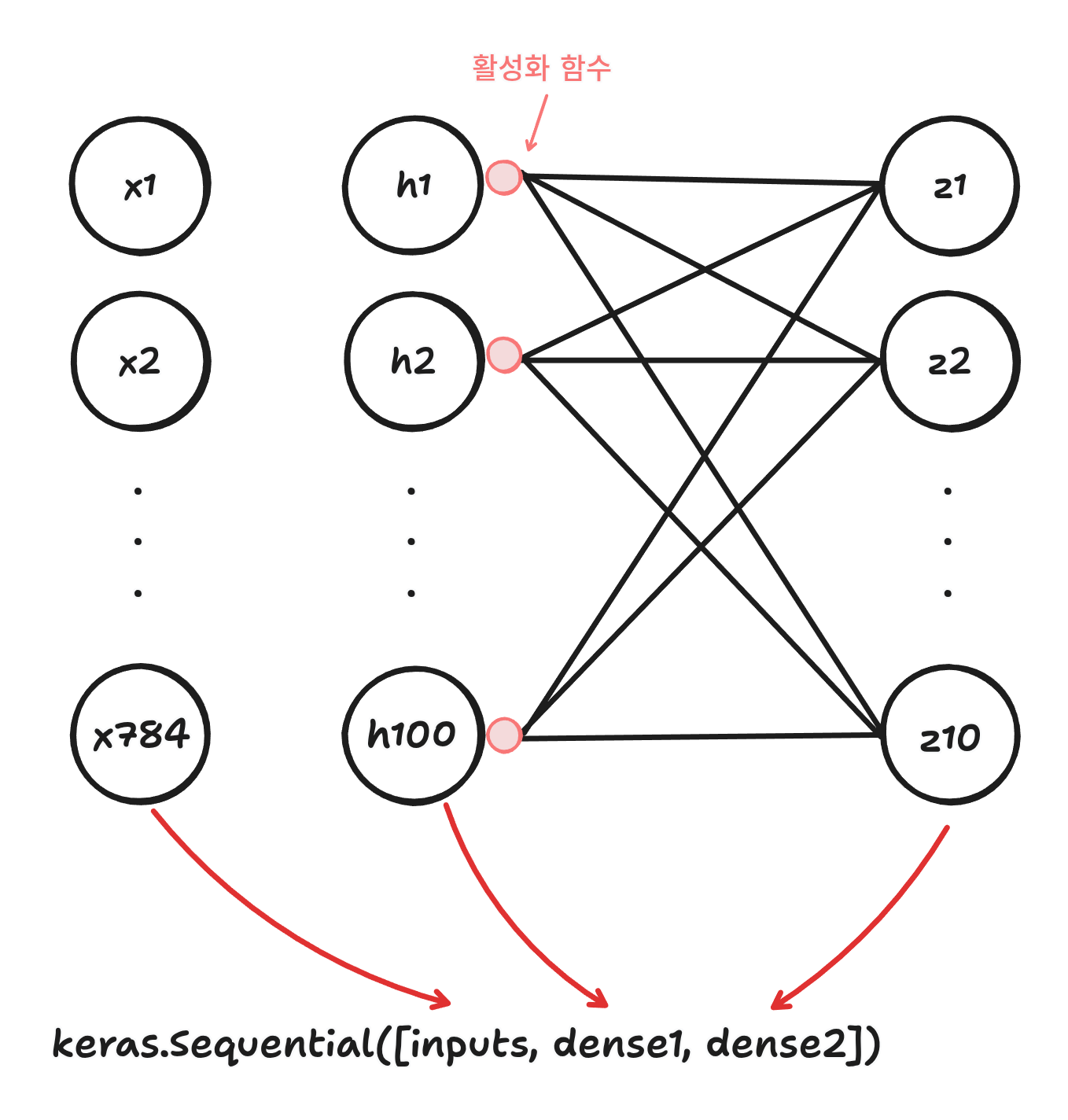
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________모델 이름, 클래스, 출력 크기, 모델 파라미터 개수가 출력된다.
출력 크기를 보면 (None, 100)으로 첫 번째 차원은 샘플의 개수를 나타낸다.
샘플 개수가 정의되어있지 않기 때문에 None이 출력된다.
fit()을 하면 미니 배치 경사하강법을 이용하여 수행한다.
케라스에서 기본 batch_size는 32다.
입력층 784개 x 은닉층 100개 + 절편 100개 = 78500개가 나온다.
두번쨰 층도 같은 방법으로 계산할 수 있다.
은닉층 100개 x 출력층 10개 + 절편 10개 = 1010개가 된다.
층 추가하기
방금은 input, dense1, dense2를 따로 만들어두고 Sequential에 넣었다.
하지만 이것을 따로 하지 않고 한 번에 할 수 있다.
model = keras.Sequential([
keras.layers.Input(shape=(784,)),
keras.layers.Dense(100, activation='sigmoid', name='hidden_layer'),
keras.layers.Dense(10, activation='softmax', name='output_layer')
], name="패션 MNIST 모델")Model: "패션 MNIST 모델"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden_layer (Dense) (None, 100) 78500
output_layer (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________name을 통해 층을 한눈에 알아볼 수 있다.
하지만 이렇게 하면 굉장히 길어진다.
이것을 해결하기 위해 add()를 사용한다.
model = keras.Sequential()
model.add(keras.layers.Input(shape=(784,)))
model.add(keras.layers.Dense(100, activation='sigmoid', name='hidden_layer'))
model.add(keras.layers.Dense(10, activation='softmax', name='output_layer'))Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
hidden_layer (Dense) (None, 100) 78500
output_layer (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________동일하게 잘 나온다.
훈련
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1/1500 [..............................] - ETA: 14:44 - loss: 2.4865 - accuracy: 0.06252025-08-13 20:41:21.348243: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fc7e63518d0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2025-08-13 20:41:21.348259: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): NVIDIA GeForce RTX 3060, Compute Capability 8.6
2025-08-13 20:41:21.352752: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:269] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
2025-08-13 20:41:21.365875: I tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:442] Loaded cuDNN version 8700
2025-08-13 20:41:21.402675: I ./tensorflow/compiler/jit/device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1500/1500 [==============================] - 3s 2ms/step - loss: 0.5667 - accuracy: 0.8073
Epoch 2/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.4106 - accuracy: 0.8521
Epoch 3/5
1500/1500 [==============================] - 2s 2ms/step - loss: 0.3764 - accuracy: 0.8632
Epoch 4/5
1500/1500 [==============================] - 2s 2ms/step - loss: 0.3520 - accuracy: 0.8723
Epoch 5/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3352 - accuracy: 0.8788추가한 히든 레이어가 성능을 향상시켰다는 것을 알 수 있다.
ReLU 함수
초창기에는 sigmoid함수를 많이 사용했는데 위의 그림을 보면 왼쪽과 오른쪽 끝으로 갈수록 변화가 적기 때문에 출력을 떄문에 층이 많은 심층 신경망일수록 그 효과가 누족되어 학습을 어렵게 만든다.
이것을 해결하기 위해 나온 새로운 함수가 렐루(ReLU)함수다.
렐루 함수는 입력이 양수면 양수, 음수면 0을 출력한다.
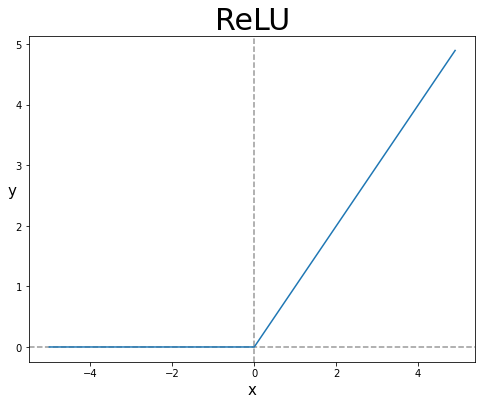
파이썬 함수로 치면 max(0, z)로 쓸 수 있다.
Flatten
앞서 데이터를 계속 1차원 배열로 바꾸고 넣었다.
하지만 굳이 미리 1차원으로 바꿔놓을 필요는 없다.
Flatten() 함수를 통해 배치차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼칠 수 있다.
이 함수를 은닉층에 추가하면 된다.
model = keras.Sequential()
model.add(keras.layers.Input(shape=(28,28)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation="sigmoid"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.summary()Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_4 (Dense) (None, 100) 78500
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 79510 (310.59 KB)
Trainable params: 79510 (310.59 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0 # 픽셀 값 0~1로 정규화
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.5675 - accuracy: 0.8050
Epoch 2/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.4104 - accuracy: 0.8514
Epoch 3/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3752 - accuracy: 0.8648
Epoch 4/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3529 - accuracy: 0.8711
Epoch 5/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3361 - accuracy: 0.8779이것도 똑같이 학습이 잘 된다.
이제 만든 모델로 검증세트에서 성능을 확인해 보면
model.evaluate(val_scaled, val_target)
# [0.34758538007736206, 0.874666690826416]86%의 정확도가 나왔다.
옵티마이저
앞서 하이퍼파라미터는 모델이 학습하지 않아 사람이 지정해줘야하는 파라미터라고 했다.
추가할 은닉층은 우리가 지정해 주어야 할 하이퍼파라미터다.
하이퍼파라미터에는 은닉층의 개수, 뉴런 개수, 활성화 함수, 층의 종류, 배치 사이즈, 에프크 등등이 있다.
케라스에서는 다양한 종류의 경사 하강법 알고리즘을 제공하는데 이것을 옵티마이저라고 한다.
compile에서 optimizer를 변경할 수 있다.
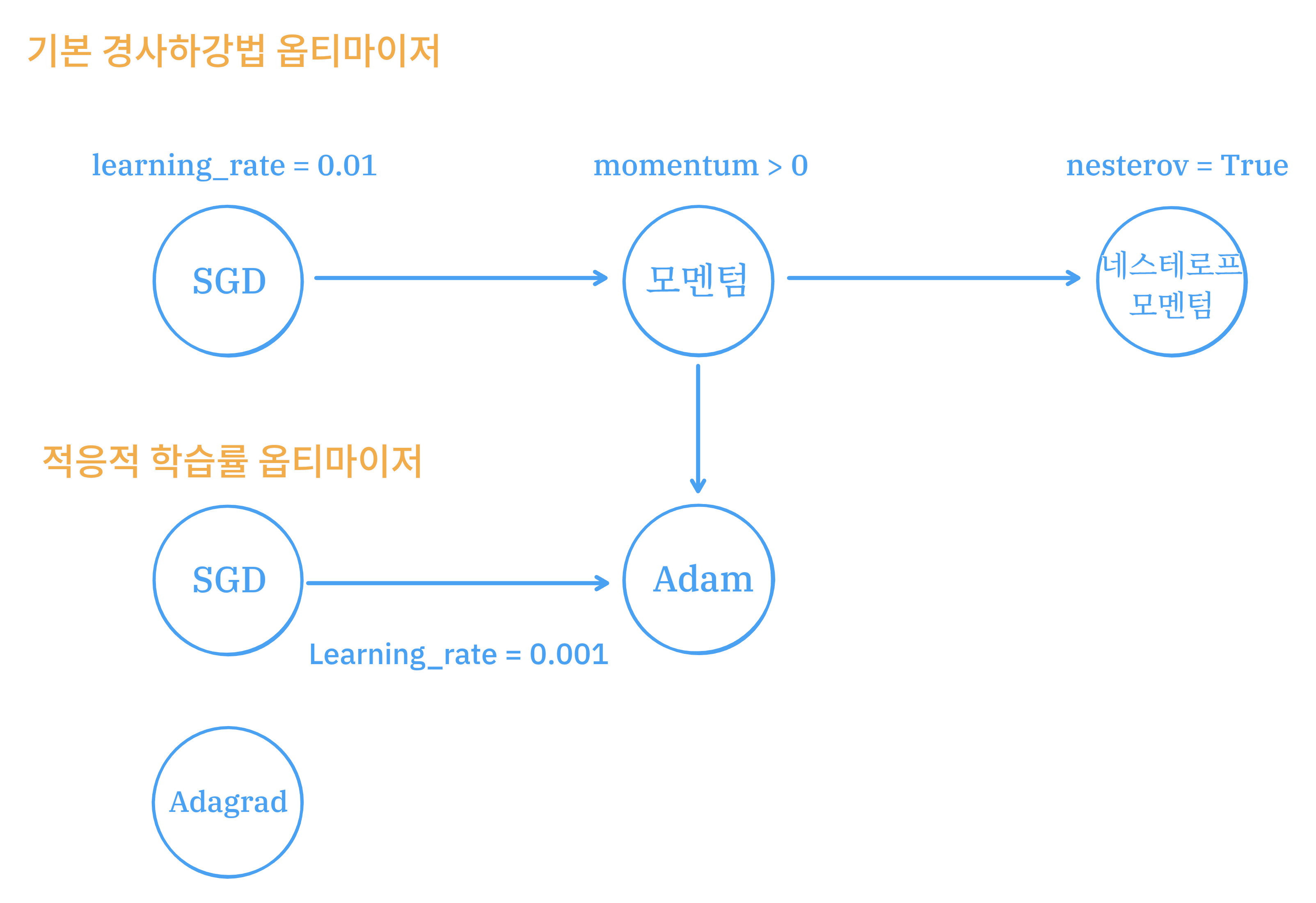
기본 경사 하강법 옵티마이저는 SGD 클래스에서 제공한다.
momentum 매개변수의 기본값은 0이다. 0보다 큰 값으로 지정하려면 모멘텀 최적화를 사용한다.
# nesterov를 True로 하면 네스테로프 모멘텀 최적화를 사용한다.
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)네스테로프 모멘텀은 모멘텀 최적화를 2번 반복한다.
모델이 최적점에 가까이 갈수록 학습률을 낮추는데 이러면 안정적으로 최적점에 수렴할 가능성이 높다. 이런 학습률을 적응적 학습률이라고 한다.
모멘텀: 기존 경사하강법은 현재의 기울기들의 평균으로 가중치를 계산하지만 모멘텀은 이전의 기울기들을 고려하여 가중치를 결정한다.
모멘텀의 기본 값은 1(지난 10개의 기울기를 고려하겠다.)이다.
rmsprop은 이전의 기울기는 조금만, 현재의 기울기의 가충치를 많기 가져가는 것이다.
그리고 이런 2개의 옵티마이저의 장점을 합한것이 Adam이다.
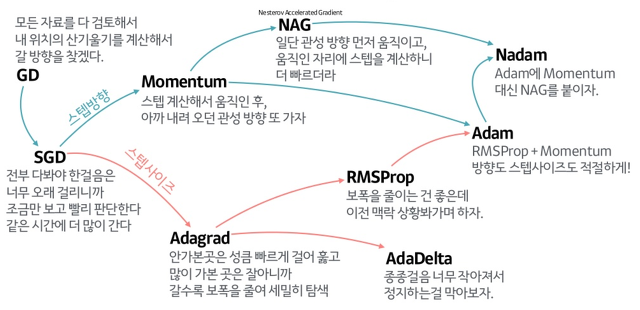
출저: https://light-tree.tistory.com/141
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(train_scaled, train_target, epochs=5)
Epoch 1/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.5812 - accuracy: 0.8050
Epoch 2/5
1500/1500 [==============================] - 2s 2ms/step - loss: 0.4108 - accuracy: 0.8528
Epoch 3/5
1500/1500 [==============================] - 2s 2ms/step - loss: 0.3711 - accuracy: 0.8666
Epoch 4/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3463 - accuracy: 0.8750
Epoch 5/5
1500/1500 [==============================] - 2s 1ms/step - loss: 0.3276 - accuracy: 0.8815이전에 sgd를 사용했을 때 보다 더 좋아졌다.
