2021 부스트캠프 Day 20.
[Day 20] NLP
Self-supervised Pre-training Models
Recent Trends
- Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applications as well as in other areas.
- Training deeply stacked Transformer models via a self-supervised learning framework has significantly advanced various NLP tasks through transfer learning, e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA…
- Other applications are fast adopting the self-attention and Transformer architecture as well as self-supervised learning approach, e.g., recommender systems, drug discovery, computer vision, …
- As for natural language generation, self-attention models still requires a greedy decoding of words one at a time.
GPT-1
- 기본적으로 다양한 Special token(
<S>,<E>)을 제안해서 simple한 task뿐만 아니라, 다양한 자연어 처리에서의 task를 처리할 수 있는 특징이 있다.
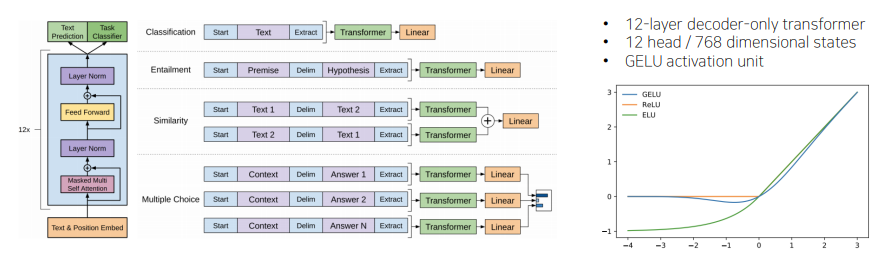
- 입력과 출력 sequence가 별도로 있는 것이 아니라, 순차적으로 생성을 하여 language modeling을 진행한다.
- Extract라는 token은 문장을 잘 이해하고 논리적으로 내포,모순 관계를 예측하는데에 필요한 정보를 query로 attention에 사용된다.
- 마지막 layer는 학습이 충분히 되어야 하지만, 이전의 layer에서는 learning rate을 상대적으로 작게 줌으로써 큰 변화가 이루어지지 않게 하여, pre-train model에는 큰 변화가 이루어지지 않도록 해준다.
Experimental Results
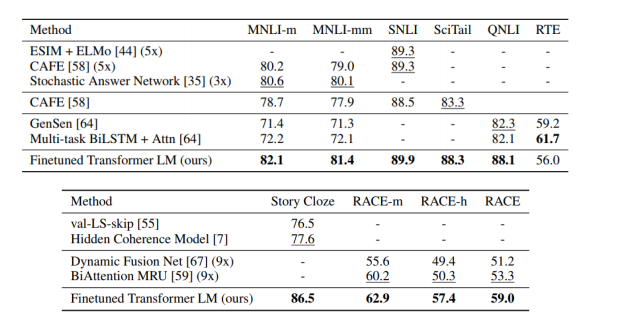
BERT
- 현재까지도 가장 널리 쓰이는 pre-train model이다.
- language modeling을 통해 학습이 되는 모델이다.
Masked Language Model
-
Motivation
- GPT모델의 경우 전 후 문맥을 보지 못하고 앞의 단어만을 보고 학습을 해야한다는 문제가 있다.
- Language models only use left context or right context, but language understanding is bi-directional
-
If we use bi-directional language model?
- Problem : Words can "see themselves"(cheating) in a bi-directional encoder
Pre-trining Tasks in BERT
-
Masked Language Model(MLM)
- Mask some percentage of the inpout tokens at random, and then predict those masked tokens.
- 15% of the words to predict
이 경우, mask로 치환하는 비율을 이것보다 더 많이 높이는 경우 주어진 문장에서 너무많은 단어를 mask로 치환한 경우 예측하여 학습하기에는 어려워지며, 너무 작게 설정하는 경우도 학습하기에 어렵게 된다.- 80% of the time, replace with
[MASK] - 10% of the time, replace with a random word
- 10% of the time, keep the sentence as same
- 80% of the time, replace with
-
Next Sentence Prediction(NSP)
- Predict whether Sentence B is an actual sencence that proceeds Sentence A, or a random sentence

- Predict whether Sentence B is an actual sencence that proceeds Sentence A, or a random sentence
-
Problem
- Mask token never seen during fine-tuning
-
Solution
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead :
- 80% of the time, replace with
[MASK]- went to the store -> went to the
[MASK]
- went to the store -> went to the
- 10% of the time, replace with a random word
- went to the store -> went to the running
- 10% of the time, keep the same sentence
- went to the store -> went to the store
- 100개의 단어중 15개가 mask가 되어야 할 경우, 80% 즉 12개만 Mask로 치환을 하고, 10% 즉 1.5개의 단어를 랜덤한 단어로 치환하며 10% 1.5개는 동일한 문장을 가지도록 한다.
- 80% of the time, replace with
- 15% of the words to predict, but don’t replace with [MASK] 100% of the time. Instead :
Next Sentence Prediction
-
masked language modeling을 통해 word별로 예측을 해야하는 task이외에 GPT에서도 있었던, 문장 level에서의 task에 대응하기 위한 pre-train 기법을 제안했으며 이 기법이 Next Sentence Prediction이다.
-
아래의 예를 들면, default로 bert model을 학습할 때, 주어진 하나의 글에서 두개의 문장을 뽑느다.
-
두 문장을 연속적으로 이어주고, 문장 사이에는 seperate token, 문장을 끝날때에도 seperate token을 준다.
-
동시에 다수의 문장 level에서의 예측 task를 수행하는 [CLS] token을 문장의 앞에 추가한다.
-
GPT에서 extract token이 문장 마지막에 등장하고, 이를 통해 다수 문장에서의 예측 task를 진행할 수 있는 것을 비슷하게 적용
-
입력데이터만으로 예측을 학습시키기 위해 연속적으로 주어진 문장이 인접한, 연속적으로 이 순서대로 나와야하는 문장인지, 전혀 연속적으로 나올 수 없는 문장인지를 예측하는 Next Sentence인지에 아닌지에 대한 binary classification task를 추가했다.
-
이 경우, 주어진 글에서 default로 2개의 문장을 뽑고, [mask]치환과 [CLS] token추가를 하여 transformer encoding을 하고, [mask] token을 예측하게 된다.
-
[CLS] token은 output layer를 하나더 주어 binary classification을 진행하고 ground truth는 실제 인접하는 text인지 아닌지를 확인한다.

BERT Summary
-
모델 구조 자체는 transformer에서 제안된 block을 그대로 사용했으며, 두가지 버전으로 학습된 모델을 제안했다.
- BERT BASE : L = 12 (Large), H = 768 (각 self-attention에서 encoding vector의 차원수), A = 12 (Attention Head의 숫자)
- BERT LARGE : L = 24 (Large), H = 1024 (각 self-attention에서 encoding vector의 차원수), A = 16 (Attention Head의 숫자)
-
Input Representation
- WordPiece Embeddings (30,000 WordPiece)
- Learned positional embedding
- [CLS] - Classification embedding
- Packed sentence embedding [SEP]
- Segment Embedding
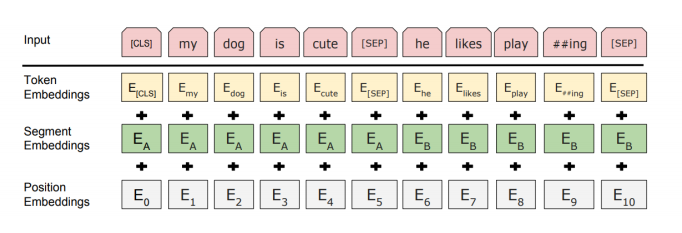
- sum of the token embeddings, the segmentation embeddings and the position embeddings
-
Pre-training Tasks
- Masked LM
- Next Sentence Prediction
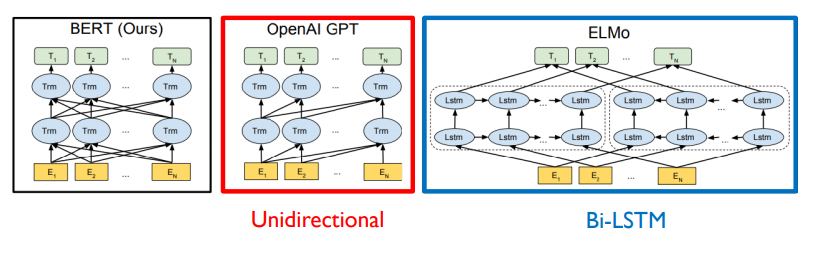
BERT and GPT
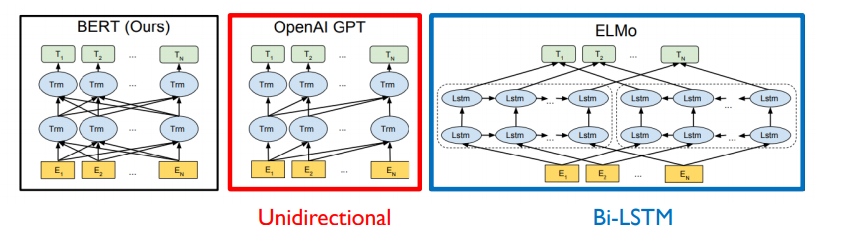
- GPT-2의 경우 주어진 sequence를 encoding할 때, 바로 다음 단어를 예측하는 task를 수행해야 하기 때문에, 특정한 time step에서 다음에 나타나는 단어를 접근을 허용하면 안된다.
- 마치 transformer에서 decoder에서 self-attention이 masked-self attention으로 사용이 됬었던 것 처럼.
- 각각의 특정한 time step에서는 자기 자신을 포함해서 왼쪽의 정보를 access하는 패턴을 볼 수 있다.
- GPT 모델 같은 경우, 기본적으로 쓰이는 sequence encoding을 하기 위한 attention block은 바로 transformer부분에서 decoder 부분에서 사용되던 masked self-attention이 사용된다.
- 그렇지만, BERT의 경우 masked로 치환된 token들을 주로 예측하게 되고 mask단어를 포함하여 전체에 주어진 모든 단어들을 다 접근이 허용이 가능하도록 함으로써 attention 패턴은 모두가 모두를 볼 수 있도록 하는 transformer에서 encoder에서 사용되던 self-attention module을 사용하게 된다.
Fine-tuning Process
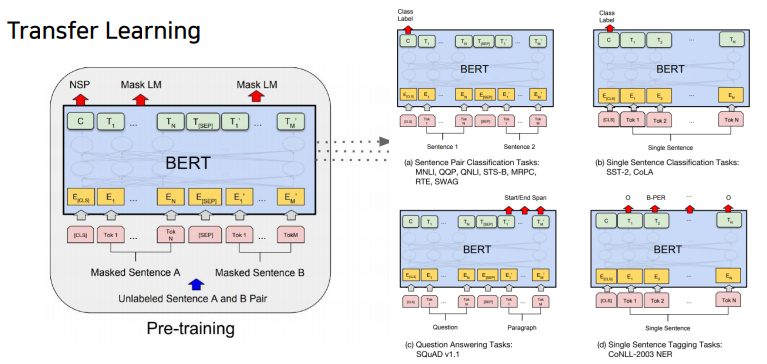
(a) Sentence Pair Classification Tasks :
두개 문장을 하나의 sequence로 그렇지만 seperate token으로 구별을 지은 후, bert를 통해 encoding을 하고 나서, 각각의 word들에 대한 encoding vector를 얻었다면 CLS token에 해당하는 encoding vector를 output layer의 입력으로 주어서 다 수 문장에 대한 예측 task를 수행할 수 있다.
MNLI, QQP, QNLU, STS-B, MRPC, RTE, SWAG
(b) Single Sentence Classification Tasks :
입력으로 줄 문장이 한번에 하나씩 밖에 없기에 문장을 하나만 주고, 첫 번째 [CLS] token encoding output을 최종 output layer에 넣어 classification을 수행하게 된다.
SST=2 CoLA
(c) Question Answering Tasks:
SQuAD v1.1
(d) Single Sentence Tagging Tasks:
각각의 CLS token을 포함해서 첫 번째, 두번째 단어에 대한 encoding vector를 동일한 어떤 공통의 output layer에 통과해서 최종 각 word별 classification이나 prediction을 수행하게 된다.
CoNLL-2003 NER
BERT vs GPT-1
-
Training-data size
- GPT is trained on BookCorpus(800M words)
- BERT is trained on the BookCorpus and Wikipedia (2,500M words)
-
Training special tokens during training
- BERT learns [SEP],[CLS], and sentence A/B embedding during pre-training
-
Batch size
- BERT – 128,000 words ; GPT – 32,000 words
-
Task-specific fine-tuning
- GPT uses the same learning rate of 5e-5 for all fine-tuning experiments; BERT chooses a task-specific fine-tuning learning rate.
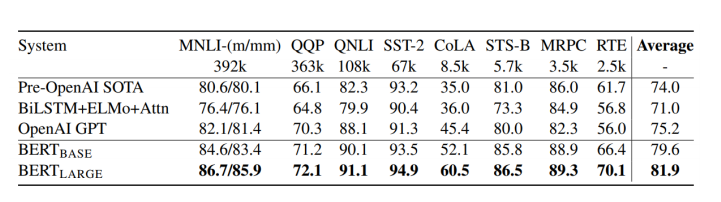
GLUE Benchmark Results
Maching Reading Comprehension(MRC), Question Answering
기계 독해에 기반한, 질문에서 필요한 정보 추출을 통해 응답을 해준다.

SQuAD 1.1

-
기본적으로 bert의 입력으로서 주어진 지문과 답을 필요로하는 질문을 두개의 서로 다른 문장인 것 처럼 seperate token을 통해 concat을 해서 하나의 sequence로 만들어서 bert를 통해 encoding을 진행한다.
-
각각의 지문상에서의 단어 별 word encoding vector가 나올 것이고 벡터들에서 정답에 해당할 법한 위치(지문 상에서 특정한 문구로 정답이 주어짐)를 기본적으로 예측하도록 모델 학습을 수행하게 된다.
-
구체적으로는 지문에서 답에 해당하는 문구가 시작하는 위치를 예측하기 위해 각 word별로 최종 encoding vector가 output으로 나왔을 때, 이를 공통된 output layer를 통해서 scalar값을 뽑도록 하여 결과값을 얻도록 한다.
-
각각 word가 2차원 vector로 최종 encoding vector로 나온 경우 각 word encoding vector에 적용해야되는 output layer는 단순히 2차원 vector를 단일한 차원의 혹은 scalar값으로 변경해주는 fully connect layer가 된다.
-
fully connected layer의 parameter가 randomailazation에서 부터 fine-tuning되는 대상에 해당하는 parameter가 된다.
-
scalar값을 각 word별로 얻은 후 에는 word상에서 여러 word들 중에 답에 해당하는 문구가 어느 단어에서 시작하는지를 먼저 예측.
-
끝나는 시점을 예측해야 하는데, 이 경우 starting position을 예측하도록 하는 output layer에 해당하는 FCN을 하나 두는 동시에 또 다른 FCN을 두번 째 version으로 만들고, 그것을 통과해서 각 word encoding vector가 scalar값이 나오도록하고 softmax를 통과하도록 한 후, endding word에 대한 position을 예측 하도록 진행한다.
SQuAD 2.0

On SWAG
주어진 문장이 있을 때, 다음에 나타날 법한 적절한 문장을 고르는 것.

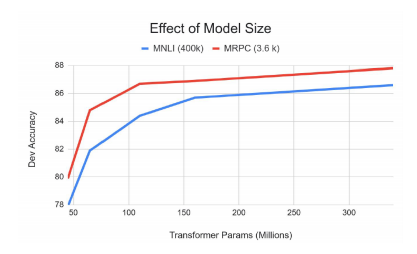
Ablation Stuey
- Big models help a lot
- Going from 110M to 340M params helps even on datasets with 3,600 labeled examples
- Improvements have not asymptoted
GPT-2
- Just a really big transformer LM
- Trained on 40GB of text
- Quite a bit of effort going into making sure the dataset is good quality
- Take webpages from reddit links with high karma
- Language model can perform down-stream tasks in zero-shot setting - without any parameter or architecture modification

Motivation (decaNLP)
- The Natural Language Decathlon : Multitask Learning as Question Answering
- 모든 종류의 자연어 task들이 질의응답으로 바뀔 수 있다는 점에서 motive를 얻었다.

Datasets
- A promising source of diverse and nearly unlimited text in web scrape such as common crawl
- They scraped all outbounds links from Reddit, a social media platform, WebText
- 45M links
- Scraped web pages which have been curated/filtered by humans
- Received at least 3 karma (up-vote)
- 45M links
- 8M removed Wikipedia documents
- Use dragnet and newspaper to extract content from links
- They scraped all outbounds links from Reddit, a social media platform, WebText
Preprocess
- Byte pair encoding (BPE)
- Minimal fragmentation of words across multiple vocab tokens
Model
- Modification
- Layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network
- Additional layer normalization was added after the final self-attention block.
- Scaled the weights of residual layer at initialization by a factor of / where is the number of residual layer
Question Answering
- Use conversation question answering datasets(CoQA)
- Achieved 55 F1 score, exceeding the performance 3 out of 4 baselines without labeled dataset
- Fine-tuned BERT achieved 89 F1 performance
Summarization
- CNN and Daily Mail Dataset
- Add text TL(Too long);DR(didn't read) : after the article and generate 100 tokens

- Add text TL(Too long);DR(didn't read) : after the article and generate 100 tokens
GPT-3
모델 구조에서의 특별한 개선이 아니라, 기존 GPT-2보다 더 많은 데이터, 더 많은 parameter, 더 큰 batch size를 적용한 것.
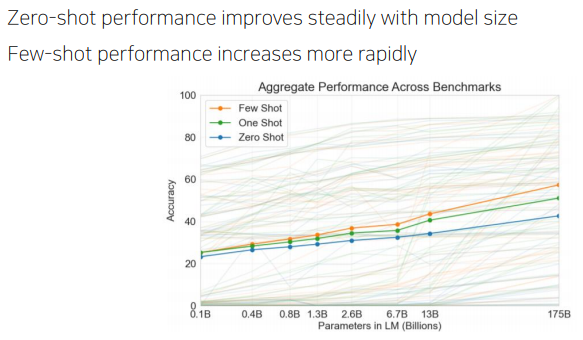
Language Models are Few-shot Learners

ALBERT : A Lite BERT
-
Is having better NLP models as easy as having larger models?
-
Obstacles
- Memory Limitation
- Training Speed
-
Solutions
- Factorized embedding Parameterization
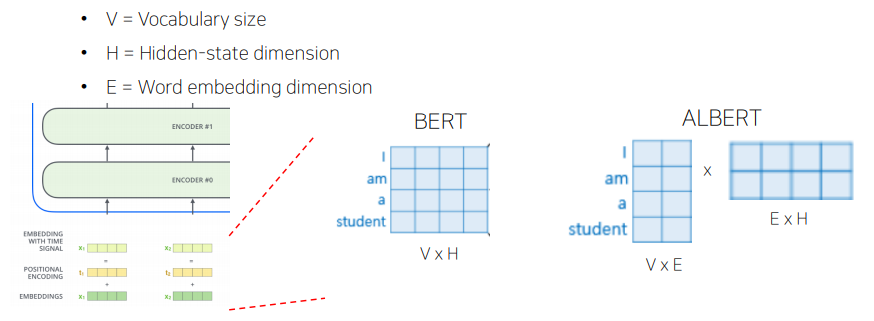
- 모델링 관점에서 보면, WordPiece embedding 은 context-independent한 representation인 반면 hidden-layer embedding의 경우 context-dependent한 representation이다. RoBERTa: A robustly optimized BERT pretraining approach. 에서의 context length에 관한 실험에서 볼 수 있듯이 BERT-like representation의 효과는 context-dependent한 representation을 학습하는데 있다. 따라서 WordPiece embedding size인 E와 hidden layer size인 H를 다르게 설정하는 것이 더 효과적인 모델 파라미터들의 활용일 수 있다.
- ALBERT에서는 factorization of embedding parameters를 사용한다. 이는 큰 embedding matrix를 작은 두개의 matrix로 나누는 방법으로 먼저 기존에 E dimension으로 바로 mapping 했던 것을 보다 작은 dimension인 E로 mapping한 후 E dimension의 vector를 다시 H dimension으로 보낸다. 이렇게 되면 기존에 V×H 였던 파라미터 수는 V×E+E×H으로 줄어들게 된다.
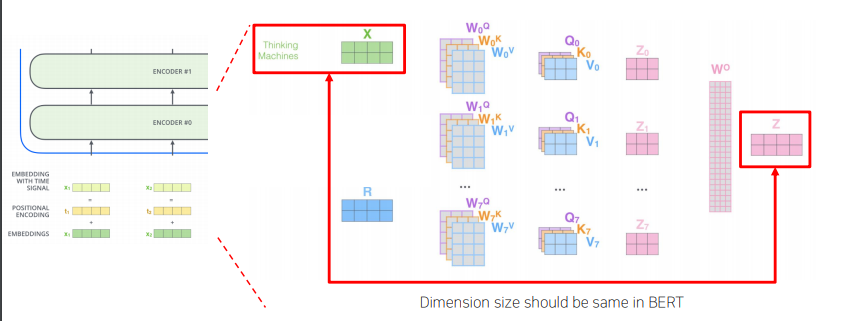
- Cross-layer Parameter Sharing
- 하나의 self-attention에서 학습해야 할 것들은 w, q, k, v이다. 이를 각각 선형변환해주는 layer가 적용된다. 또한 마지막의 concat후 선형변환을 해주는 w를 통해 선형변환하는 layer가 필요하다.
- 이렇게 하나의 self-attention에서 필요한 선형변환 layer를 multi-head가 될경우 여러개가 필요하게 되고, 이를 다양한 share layer로 바꾸어 성능을 비교해 보았고, 적용시켰다.
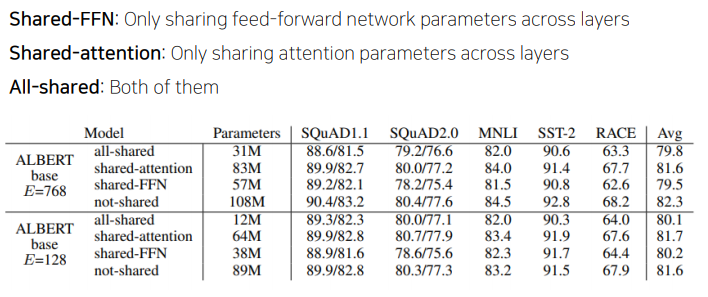
- (For Performance) Sentence Order Prediction
- Bert이후의 연구에서 NSP task가 실효성이 떨어지는 것을 알아냈고, 연속적인 두 문장을 가지고 와서 원래 있던 순서대로 concat을 하고 맞는 것이다고 학습을 하고, 순서를 바꿔서 concat을 해서 negative sample을 만들어주어 학습을 하였다.
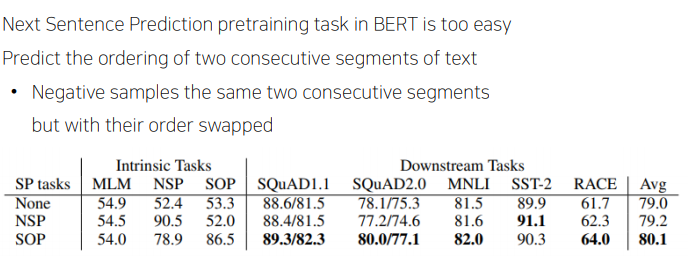
- Bert이후의 연구에서 NSP task가 실효성이 떨어지는 것을 알아냈고, 연속적인 두 문장을 가지고 와서 원래 있던 순서대로 concat을 하고 맞는 것이다고 학습을 하고, 순서를 바꿔서 concat을 해서 negative sample을 만들어주어 학습을 하였다.
- Factorized embedding Parameterization
-
GLUE Results
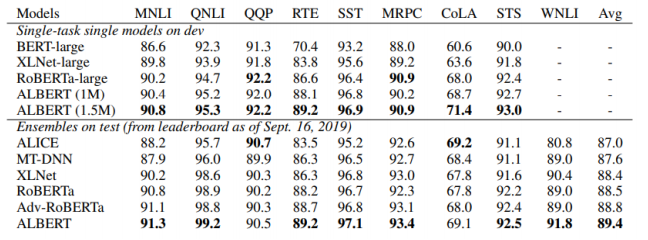
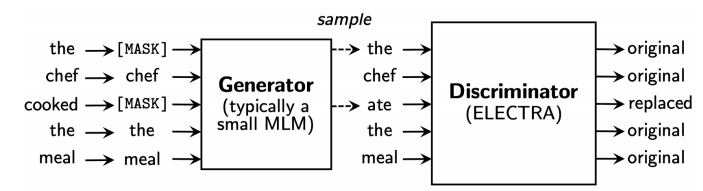
ELECTRA : Efficiently Learning an Encoder that Classifies Token Replacements Accurately
- Learn to distinguish real input tokens from plausible but synthetically generated replacements
- Pre-training text encoders as discriminators rather than generators
- Discriminator is the main networks for pre-training.
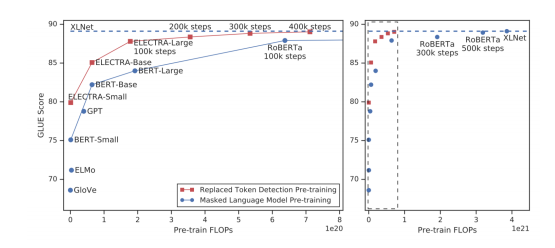
Replaced token detection pre-training vs masked language model pre-training
- Outperforms MLM-based methods such as BERT given the same model size, data, and compute
Light-weight Models
DistillBERT (NeurIPS 2019 Workshop )
- A triple loss, which is a distillation loss over the soft target probabilities of the teacher model leveraging the full teacher distribution
TinyBERT (Findings of EMNLP 2020)
- Two-stage learning framework, which performs Transformer distillation at both the pre-training and task-specific learning stages
Fusing Knowledge Graph into Language Model
ERNIE: Enhanced Language Representation with Informative Entities (ACL 2019)
- Informative entities in a knowledge graph enhance language representation
- Information fusion layer takes the concatenation of the token embedding and entity embedding
KagNET: Knowledge-Aware Graph Networks for Commonsense Reasoning (EMNLP 2019)
- A knowledge-aware reasoning framework for learning to answer commonsense questions
- For each pair of question and answer candidate, it retrieves a sub-graph from an external knowledge graph to capture relevant knowledge
References
• GPT-1
https://blog.openai.com/language-unsupervised/
• BERT : Pre-training of deep bidirectional transformers for language understanding, NAACL’19
https://arxiv.org/abs/1810.04805
• SQuAD: Stanford Question Answering Dataset
https://rajpurkar.github.io/SQuAD-explorer/
• SWAG: A Large-scale Adversarial Dataset for Grounded Commonsense Inference
https://leaderboard.allenai.org/swag/submissions/public
• How to Build OpenAI’s GPT-2: “ The AI That Was Too Dangerous to Release”
https://blog.floydhub.com/gpt2/
• GPT-2
https://openai.com/blog/better-language-models/
https://cdn.openai.com/better-languagemodels/language_models_are_unsupervised_multitask_learners.pdf
• Language Models are Few-shot Learners, NeurIPS’20
https://arxiv.org/abs/2005.14165
• Illustrated Transformer
http://jalammar.github.io/illustrated-transformer/
• ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ICLR’20
https://arxiv.org/abs/1909.11942
• ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators, ICLR’20
https://arxiv.org/abs/2003.10555
• DistillBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/abs/1910.01108
• TinyBERT: Distilling BERT for Natural Language Understanding, Findings of EMNLP’20
https://arxiv.org/abs/1909.10351
• ERNIE: Enhanced Language Representation with Informative Entities
https://arxiv.org/abs/1905.07129
• KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning
https://arxiv.org/abs/1909.02151
