2021 부스트캠프 Day 19.
[Day 19] NLP
Transformer
RNN
- 멀리 있는 정보들에 대해서는 정보 손실이 발생한다.
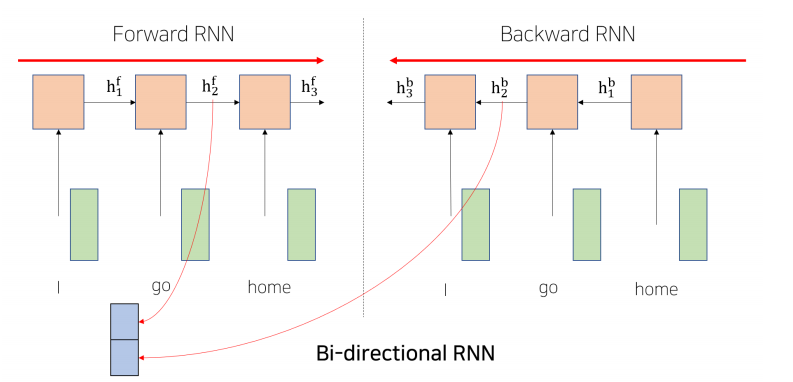
Bi-Directional RNNs
Transformer : Long-Term Dependency
- 앞의 강의에서 깊게 다루었던 내용들이라 간단하게 메모했다.
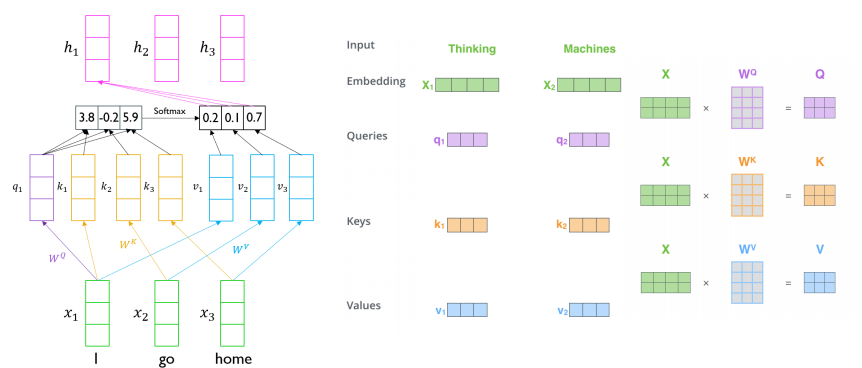
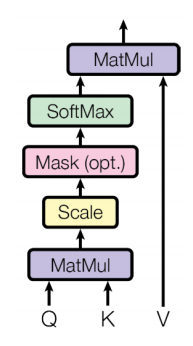
Scaled Dot-Product Attention
-
Inputs : a query and a set of key-value(,) pairs to an output
-
Ountput is weighted sum of values
-
Weight of each value is computed by an inner product of query and corresponding key
-
Queries and keys have same dimensionality k, and dimensionality of value is v
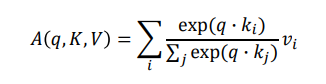
-
When we have multiple quries , we can stack them in a matrix
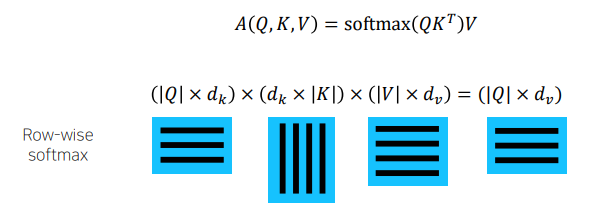
-
Problem
- 내적에 참여하는 q, k의 dimension에 따라 분산이 좌지우지될수 있고, 확률이 극단적으로 나올 수 있는 softmax의 확률분포의 패턴이 발생
- As k gets large, the variance of k increases
- Some values inside the softmax get large
- The softmax gets very peaked
- Hence, its gradient gets smaller
-
Solution
- Scaled by the length of query / key vectors
- 분산을 일정하게 유지시켜주어 학습을 안정화 시키게 된다.
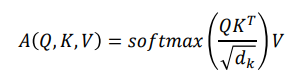
-
Result
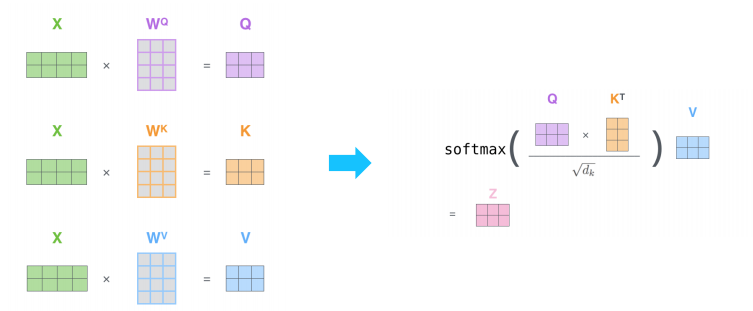
Multi-Head Attention
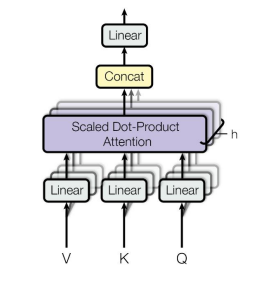
- The input word vectors are the queries, keys and values
- In other words, the word vectors themselves select each other
Problem of single attention
- 동일한 sequence가 주어졌을 때에도, 특정한 query word에 대해서 서로 다른 기준으로 여러 측면에서의 정보를 뽑아와야 될 수도 있다. 가령, 여러 문장으로 이루어져 있기는 하지만 어떤 하나의 sequences로 볼수있는 문장이 주어졌을 때, i라는 주체가 장소의 변화, 행동의 특징 등과 같은 다른 측면의 정보를 뽑아와야 될 수 있다.
- Only one way for words to interact with one another
Solution
- Multi-head attention maps 𝑄,𝐾, 𝑉 into the ℎ number of lower-dimensional spaces via 𝑊 matrices
- Then apply attention, then concatenate outputs and pipe through linear layer
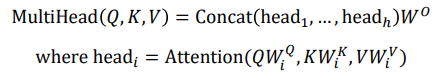
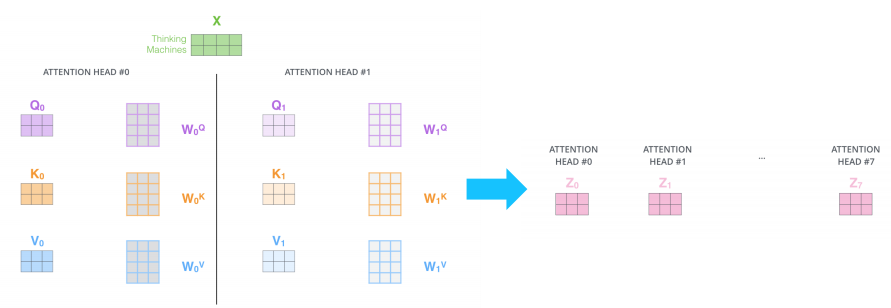
Example
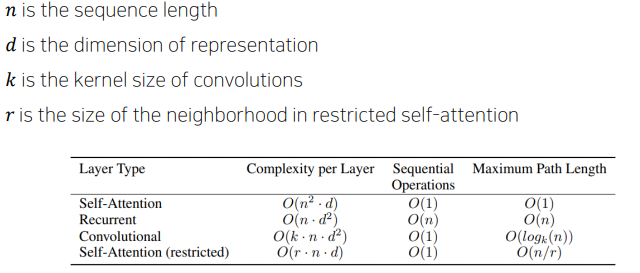
Attention 모델의 계산량이나 메모리 요구량 측면에서의 여러 모델과의 비교
- Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types
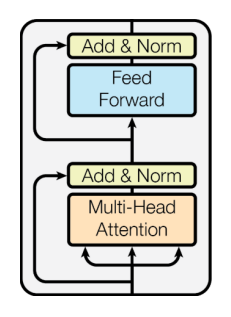
Block-Based Model
-
Each block has two sub-layers
- Multi-head attention
- Two-layer feed-forward NN (with ReLU)
-
Each of these two step also has
- Residual connection and layer normalization : 𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥 + 𝑠𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
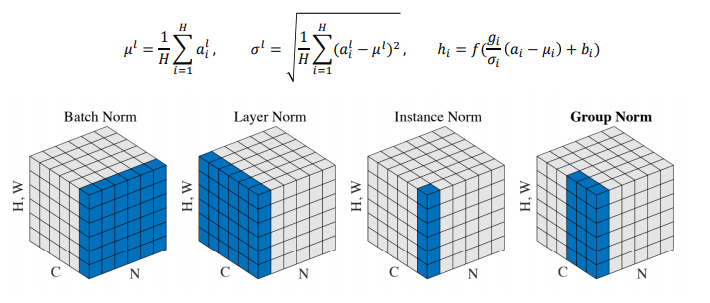
Layer Normalization
-
Normalization은 일반적으로 어떤 주어진 다수의 샘플들에 대해서 평균을 0 분산을 1로 만들어준 후, 우리가 원하는 평균과 분산을 주입할 수 있도록 하는 선형변환으로 이루어진다.
-
Layer normalization consists of two steps:
- Normalization of each word vectors to have mean of zero and variance of one.
- Affine transformation of each sequence vector with learnable parameters.
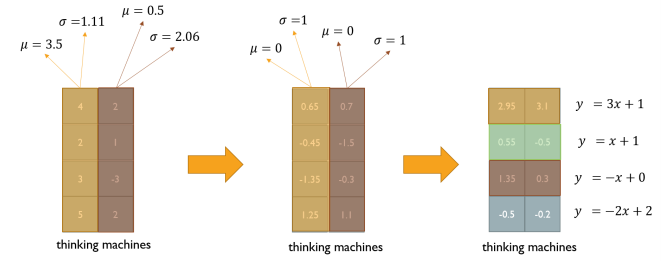
Positional Encoding
-
transfomer는 recurrence도 아니고 convolution도 아니기 때문에, 단어의sequence를 이용하기 위해서는 단어의 position에 대한 정보를 추가해줄 필요가 있다.
-
각 순서를 특정지을 수 있는 어떤 unique한 상수 벡터를 각 순서에 해당하는 input vector에 더해주는 방법.
-
Use sinusoidal functions of different frequencies
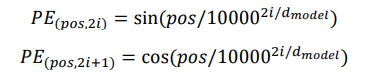
-
Easily learn to attend by relative position, since for any fixed offset 𝑘,
𝑃𝐸(𝑝𝑜𝑠+𝑘) can be represented as linear function of 𝑃𝐸(𝑝𝑜𝑠)
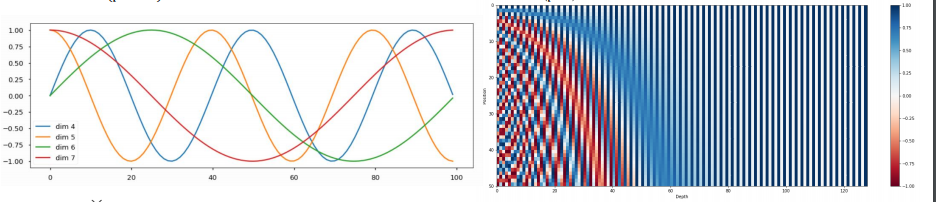
-
비록 같은 column이라고 할지라도 pos가 다르다면 다른 값을 가지게 된다. 즉, pos마다 다른 pos와 구분되는 positional encoding 값을 얻게 된다.
-
논문에서는 학습된 positional embedding 대신 sinusoidal version을 선택했습니다. 만약 학습된 positional embedding을 사용할 경우 training보다 더 긴 sequence가 inference시에 입력으로 들어온다면 문제가 되지만 sinusoidal의 경우 constant하기 때문에 문제가 되지 않습니다. 그냥 좀 더 많은 값을 계산하기만 하면 된다.
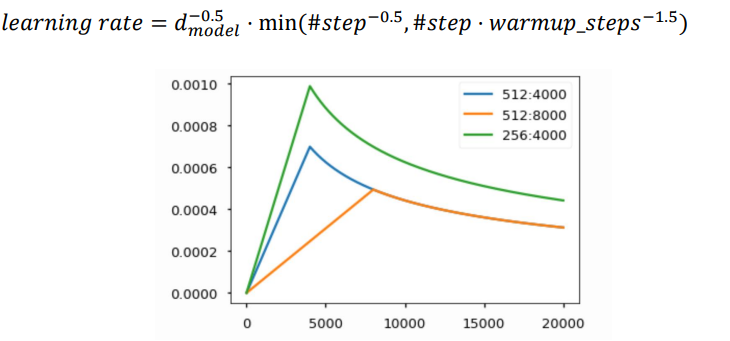
Warm-up Learning Rate Scheduler
Decoder
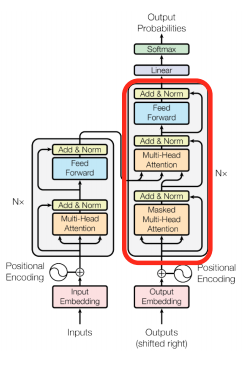
-
Two sub-layer changes in decoder
-
Masked decoder self-attention on previously generated output
-
Encoder-Decoder attention, where queries come from previous decoder layer and keys and values come from output of encoder
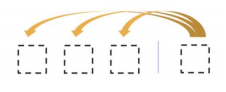
Masked Self-Attention
-
디코딩 과정 중에, 다음 단어를 예측하는 과정에서 주어진 sequence에 대해서 self-attention을 통해 encoding을 하는 과정에서 정보의 접근 여부와 관련이된다.
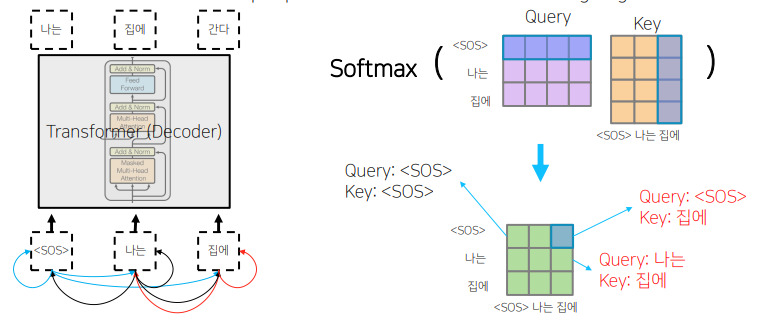
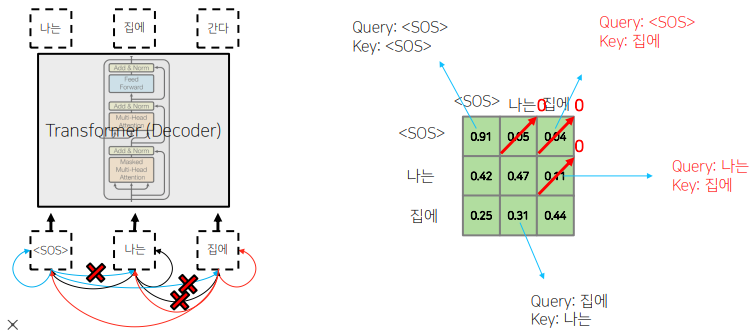
-
<SOS>를 query로 했을 때,<sos>를 key로 했을 때,나는을 key로 했을 때 어느정도의 유사도로 볼지에 대한 정보를 담고있다. -
각 단어가 나머지 모든 단어들에 대해서 정보를 다 접근을 허용하게 되면 안된다.
-
Those words not yet generated cannot be accessed during the inference time
-
Renormalization of softmax output prevents the model from accessing ungenerated words
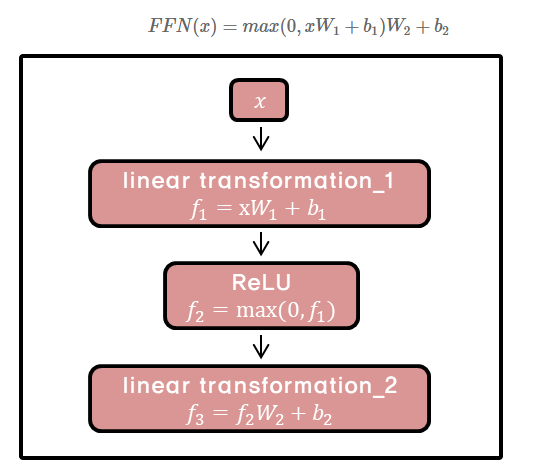
Feed-Forward Networks
강의내용에서는 FFN에 대한 설명이 이루어지지 않아, 따로 찾아보았다.
- encoder와 decoder의 각각의 layer는 아래와 같은 fully connected feed-forward network를 가진다.
-
개별 단어마다 적용되기에 position-wise라고 한다.
-
FFN은 2 linear transformation과 1 ReLU 로 이루어져 있다.