
📊 Keras
📌 Keras란?
- 정의
- 가장 핵심적인 데이터 구조는 "모델"이다.
- 시퀀스(Sequential) 모델을 이용해 레이어(Layer)를 쉽게 쌓을 수 있다.
- 시퀀스(Sequential)에 Dense(완전연결층) Layer를 쌓는 스택 구조를 사용한다.
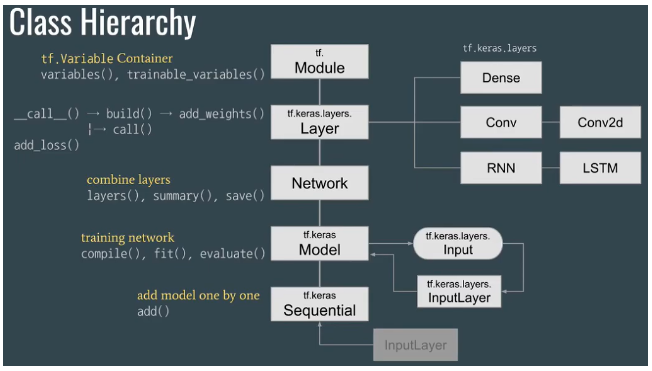
📌 Keras 내부 모듈 설명
- Sequential 클래스
- 모델을 구성할 때, 순수 Frame or 도화지 역할을 하는 클래스이다.
- Sequential 위에 여러 Layer를 쌓아 모델을 구축한다.
- Dense 클래스
- 완전 연결층
- Sequential 위에 쌓는 기본적인 층이며, 입력값에 대해 내부 노드와 완전연결(병렬 행렬곱)을 수행한다.
- 행렬곱 결과를 활성화 함수(Activation)에 넣어 처리 후, 출력한다.[ 은닉층과 출력층 차이 ]
- 은닉층 : Sequential 중간에 위치한 층이며, 활성화 함수로 ReLu를 일반적으로 사용한다.
- 출력층 : Sequential 마지막에 위치한 층이며, 출력되는 값은 1개이다. 즉, 내부 노드 개수가 1개로 지정되어야 한다. 활성화 함수는 분류에 경우 Sigmoid or Softmax를 사용한다.
📌 역전파 알고리즘이란?
- 역전파 알고리즘
1) 학습을 진행할 때, 은닉층의 출력값을 출력층의 입력값으로써 노드와 활성화함수를 거쳐 출력값으로 출력한다.
2) 여기서 출력값(예측값)과 실제값을 비교하여 cost를 확인한다.
→ cost함수, loss함수, 손실함수 지정3) 해당 cost를 기반으로 기울기(w)와 편향값(b)의 갱신이 필요한 경우, 역전파를 통해 입력층으로 다시 돌아가면서 학습을 반복하며 cost를 최소화해 나간다.
→ 최적화 함수(optimizer) 지정4) cost가 최소화 되었을 때의 기울기(w)와 편향값(b)를 선택하며 학습을 종료한다.
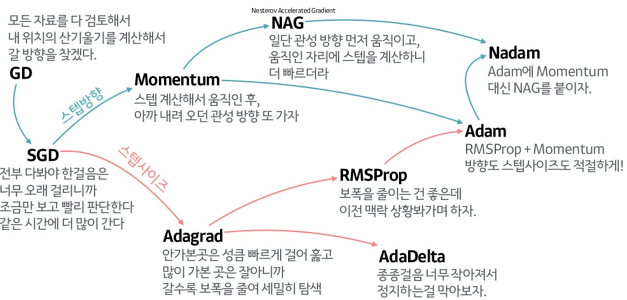
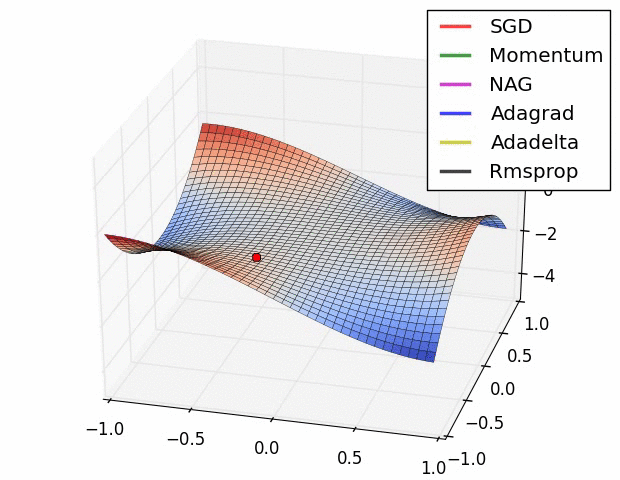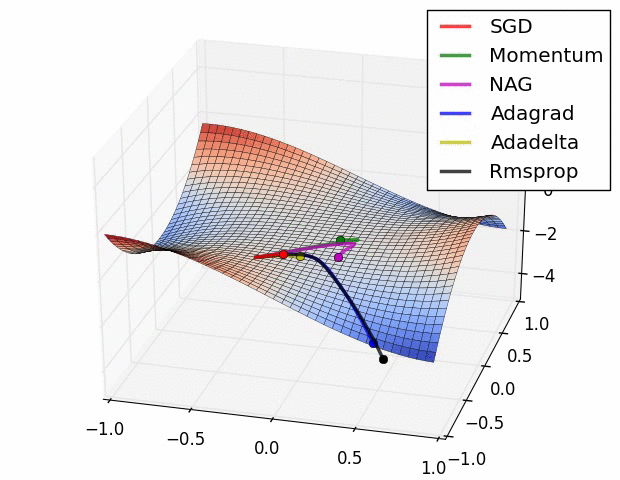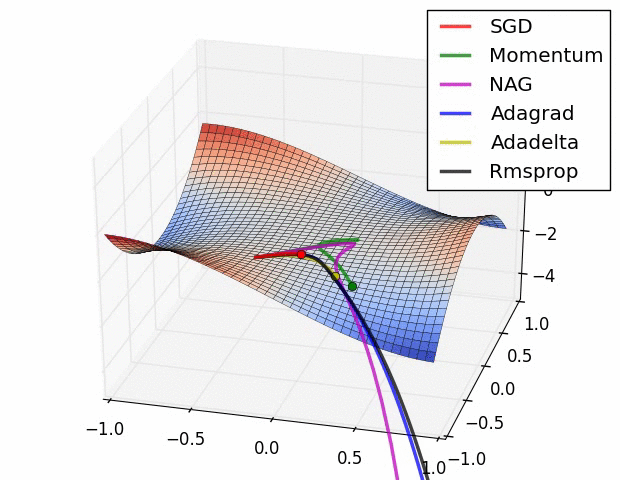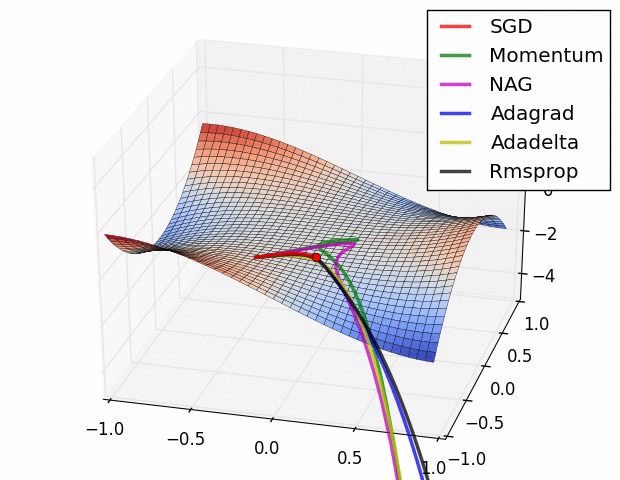
📌 최적화 함수란?
- 최적화 함수(optimizer)
- 모델의 cost를 최소화하는 최적의 기울기(w)와 편향값(b)을 구해가는 방식
- 종류
- GD(경사하강법) : FM으로 수행
- SGD(확률적 경사하강법) : 더 빠르게 수행
- RMSprop : 더 빠르게 하지만 이전 상황을 확인하고 빠르기를 조정해가며 최적화 수행
- Momentum : 기울기를 구해가는 방향을 계산해서 최적화 수행
- Adam : 방향(Momentum)과 속도(RMSprop)를 계산해가며 최적화 수행
📊 Keras MLOps 수행
📌 MLOps 수행
1. 라이브러리 Import
import numpy as np import tensorflow as tf # Sequential - 시퀀스 모델 from keras.models import Sequential # Dense - 완전 연결 층 # Activation - 활성화 함수 from keras.layers import Dense, Activation # 모델 읽기 from keras.models import load_model
2. 데이터 준비
x = np.array([[0,0], [0,1], [1,0], [1,1]]) print(x) # [[0 0] # [0 1] # [1 0] # [1 1]] y = np.array([0, 1, 1, 1])
3. Sequential 모델 구성
- 시퀀스 모델을 생성한 뒤 필요한 레이어를 추가하며 구성한다.
[ Dense 층 ]
설명
- Dense층은 데이터를 1차원으로 펼친다.
→ [ 입력층에서는 다차원의 데이터를 자동으로 차원축소하여 1차원으로 변경 가능하다. ][ 속성 설명 ]
- units 속성 : 나가는 개수(인공신경망 노드 개수)
- input_dim 속성 : 들어오는 개수(feature 개수)
[ 모델 구성 방법 1 ]
Sequential 모델을 분리하고 add() 메소드를 사용해 층을 추가한다.model = Sequential() model.add(Dense(units=1, input_dim=2)) model.add(Activation('sigmoid'))[ 모델 구성 방법 2 ]
Sequential 클래스 인자에 층을 추가하여 전달한다.model = Sequential([ Dense(units=1, input_dim=2), Activation('sigmoid') ])
4. 모델 학습 과정 설정
- compile() 함수를 사용
[ optimizer 속성 ]
정의 : 최적화 함수 - 학습 시 cost를 최소화시키는 방식을 지정- sgd(확률적 경사하강법) : 일반 경사하강법보다 적중률은 낮을 수 있으나 속도가 빠르며, 학습에 일부 데이터만 참여하게 한다.
[ loss 속성 ]
정의 : 마지막 출력값(예측값)과 실제값을 비교할 때, cost를 측정하는 방법을 지정한다.- binary_crossentropy : 이항 분류일 때 사용하는 손실함수
[ metrics 속성 ]
정의 : 매 학습 횟수(epochs)마다 모델의 성능 평가 방식을 지정- accuracy : 분류 모델의 성능 평가 방식에 사용
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
5. 모델 학습
- fit() 함수를 사용
[ batch_size ]
- 학습데이터 하나 하나를 학습에 사용하는 것이 아닌, 학습데이터에서 특정 묶음을 학습에 적용한다.
- batch_size가 너무 크면, 학습속도가 느려짐
- batch_size가 너무 작으면, 모델의 편차가 심해짐[ epochs ]
- 역전파 알고리즘을 수행하기 위해 학습 횟수를 지정[ verbose ]
- 학습 과정을 출력할지 말지를 지정[ validation_split ]
- 학습 도중 train set에서 검증을 위한 validation set을 분리한다.model.fit( x, y, batch_size=1, epochs=500, verbose=1, validation_split=0.2 )
6. 모델 평가
- 준비된 시험셋으로 학습한 모델을 평가한다.
- evaluate() 함수를 사용loss_metrics = model.evaluate(x, y, batch_size=1, verbose=0) print('loss_metrics : ', loss_metrics) # loss_metrics : [0.25263798236846924, 1.0]
7. 모델 예측값 출력
- 임의의 입력으로 모델의 출력을 얻는다.
- predict() 함수를 사용한다.pred = model.predict(x) print('예측값 :\n', pred) # 예측값 : # [[0.51734793] # [0.6439444 ] # [0.54566586] # [0.6695786 ]] pred = (model.predict(x) > 0.5).astype('int32').flatten() print('예측값 : ', pred) # 예측값 : [0 1 1 1]
8. 모델 저장
model.save('tf5.hdf5') # -> hdf5 : 대용량 데이터일 때 사용
9. 모델 읽기
model = load_model('tf5.hdf5')
