📊 선형 회귀 vs 로지스틱 회귀
📌 R 선형 회귀
- Linear Regression
- 독립변수 : 연속형
- 종속변수 : 연속형
- 독립변수들과 종속변수 사이의 잔차를 최소화하는 선의 기울기를 찾는 것

📌 R 로지스틱 회귀
- Logistic Regression
- 독립변수 : 연속형
- 종속변수 : 범주형(딱 떨어지는 값) [ ex 0 or 1 ]
- 독립변수들의 값에 따라 특정 범주에 있는 종속변수로 매칭시키도록 기울기를 찾는 것[ 중요 ]
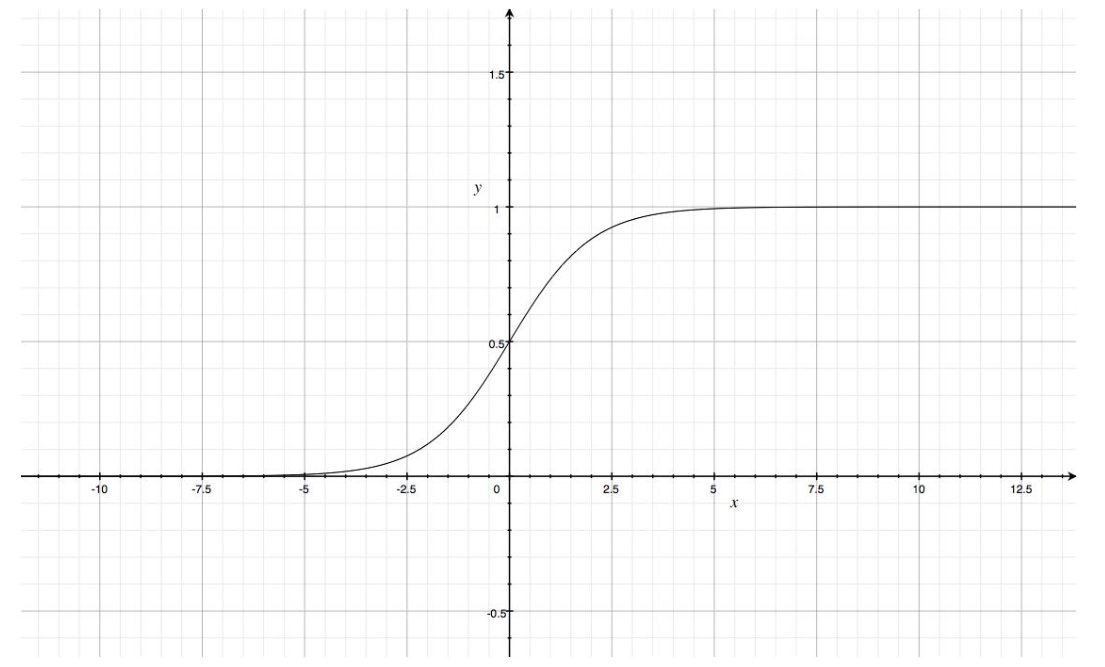
- 활성화 함수 : 시그모이드(Sigmoid) 함수를 사용
시그모이드 함수란?
- 모든 독립변수를 0 ~ 1 사이의 실수값 변경
- 정규화와 같은 역할을 하는 함수
- 시그모이드 함수를 사용하는 이유
- 모든 독립변수를 0 ~ 1 사이의 실수값을 갖도록 하며, 모델은 0.5를 기준 경계로 하여 경계보다 큰 값이면 종속변수 1로 분류, 작은 값이면 종속변수 0으로 분류한다.
📊 과대적합과 과소적합
📌 R 과대적합
- OverFitting
- 훈련데이터(train data)로 학습 시, 학습 Epoch를 너무 많이 주어 학습데이터에 대해서만 성능이 매우 높아지는 현상
- 과대적합 결과
- 검증데이터(validation data) 또는 테스트데이터(test data)로 검증 및 실사용할 시, 예측력이 매우 떨어질 수 있다.
- 발생 원인
- 훈련데이터에 대한 높은 Epoch 계수로 인한 분산 발생
📌 R 과소적합
- UnderFitting
- 훈련데이터(train data)로 학습 시, 학습 Epoch를 너무 적게 주어 모델의 편향이 너무 커진 상태 (성능 저하)
- 과소적합 결과
- 훈련, 검증, 테스트 데이터에 대해 모델 성능이 떨어질 수 있다.
- 발생 원인
- 훈련데이터에 대한 낮은 Epoch 계수로 인한 편향 발생
📌 R 분산과 편향
- 분산
- 확률변수의 작은 변동에도 과하게 반응하는 것
- 편향
- 확률변수의 큰 변동에도 둔한 반응을 하는 것
📊 분류 모델 평가 지표
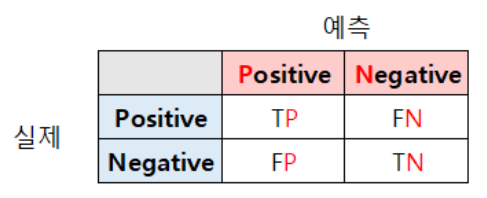
📌 R 혼동 행렬(Confusion Matrix)
- ⭐ 혼동 행렬
- TP : 참 긍정
- FP : 거짓 긍정
- FN : 거짓 부정
- TN : 참 부정
📌 R 혼동 행렬을 이용한 평가 지표
- 정밀도(Precision)
정밀도 = (TP) / (TP + FP) = (참 긍정) / (예측 긍정)
- 모델이 긍정이라고 예측한 것 중에서 실제 긍정인 비율
- 재현율(Recall)
재현율 = (TP) / (TP + FN) = (참 긍정) / (실제 긍정)
- 실제 값이 긍정인 것 중에서 모델이 예측한 긍정이 참인 비율
- ⭐ 정확율(Accuracy)
정확율 = (TP + TN) / (TP + FN + FP + TN) = (모델이 맞춘 개수) / (전체 개수)
- 전체 개수 중에서 모델이 예측한 결과가 참인 비율
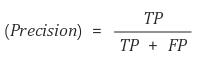
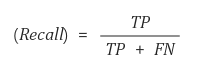
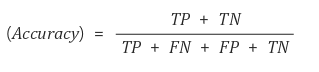
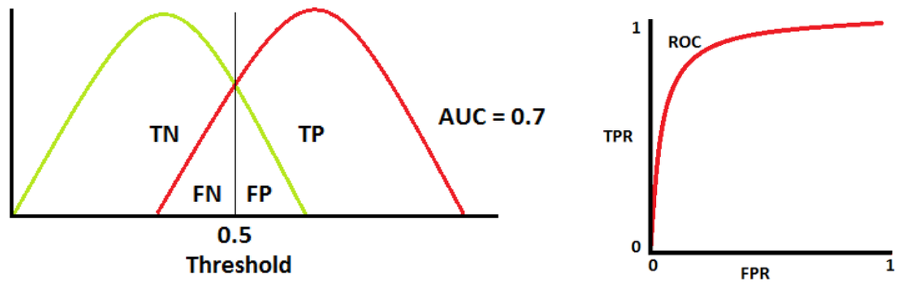
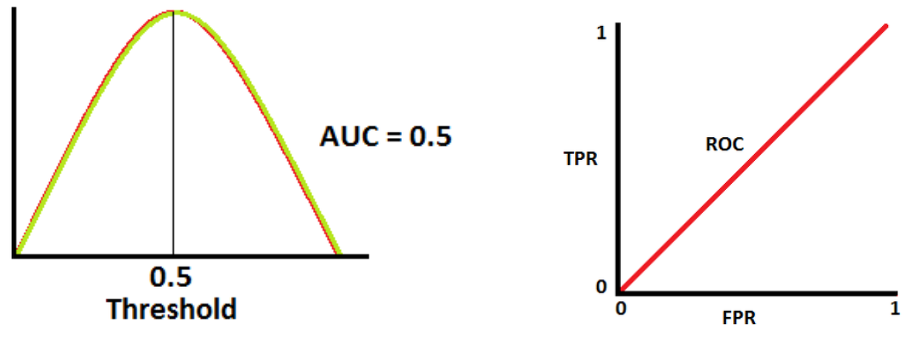
📌 R ROC Curve와 AUC 면적
- ⭐ ROC 곡선
여러 임계값들을 기준으로 Fallout 대비 Recall의 변화율을 그래프화 한 것
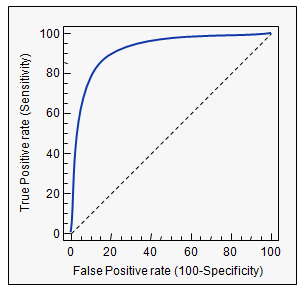
- ⭐ AUC 면적
AUC (Area Under the ROC Curve)는 ROC Curve의 밑면적을 의미한다.
즉, 성능 평가에 있아서 수치적인 기준이 될 수 있는 값으로, 면적이 1에 가까울수록
그래프가 좌상단에 근접하게 되므로 좋은 모델이라고 할 수 있다.
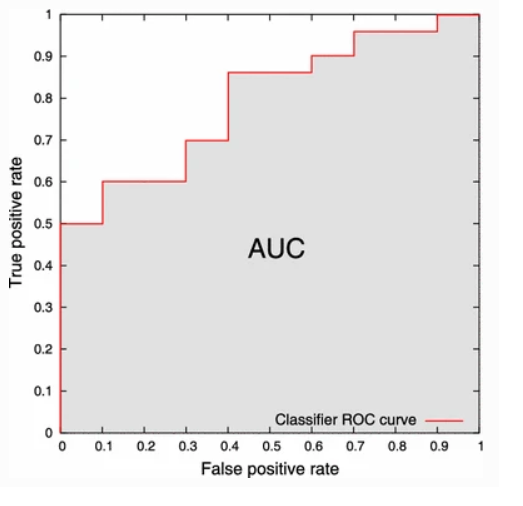
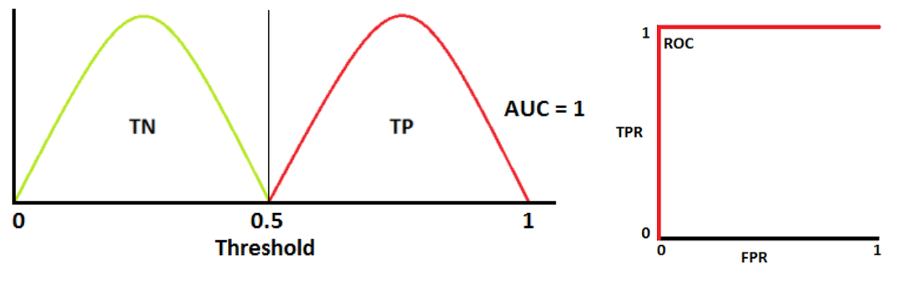
📌 AUC 면적 측정 방법
- AUC = 1
- 양성 클래스와 음성 클래스를 완벽하게 구별할 수 있음
- AUC = 0.7
- 양성 클래스와 음성 클래스를 구별할 수 있는 확률은 70%
- AUC = 0.5
- 양성 클래스와 음성 클래스를 구분할 수 있는 능력이 없음
📊 로지스틱 회귀 분류 절차
📌 1. 데이터셋 준비
웹에 존재하는 데이터 또는 데이터 크롤링을 통해 얻은 데이터를 준비
DataFrame 형태로 준비하는 것이 이후 전치리 및 모델 학습 시, 유용하다.
📌 2. 데이터 전처리
1) 데이터 차원 확인
2) 데이터 결측값 확인 -> 존재하면 제거 or 임의의 값으로 변경
3) 레이블 범위 확인 -> 문자형일 때, 원-핫 인코딩으로 더미변수로 변환
📌 3. 학습, 테스트 데이터 분리
과적합 방지 목적
일반적으로 학습7:테스트3 비율로 분리
📌 4. 로지스틱 회귀 분류 모델 작성
glm() : 일반화시킨 Linear Regression 모델
family 속성 : binomial 키워드로 이항분포를 따르게끔 모델 튜닝model <- glm(RainTomorrow ~ ., data=train, family='binomial')
📌 5. 로지스틱 회귀 분류 모델 작성
glm() : 일반화시킨 Linear Regression 모델
family 속성 : binomial 키워드로 이항분포를 따르게끔 모델 튜닝model <- glm(RainTomorrow ~ ., data=train, family='binomial')
📌 6. 모델 검증
이전에 분리한 테스트 데이터로 모델 검증 수행
pred <- predict(model, newdata=test, type='response') result_pred <- ifelse(pred > 0.5, 1, 0)
📌 7. 검증 기반 모델 평가
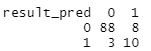
혼동 행렬의 정확도(accuracy)를 이용한 모델 평가
t <- table(result_pred, test$RainTomorrow)[ 정확도 평가 ]
# 정확도 (t[1,1] + t[2,2]) / nrow(test) # 89% 가량의 정확도를 보인다.
📌 8. ROC 곡선과 AUC를 이용한 평가
- 사용 패키지 설치
install.packages("ROCR") library(ROCR)
- ROC 곡선 객체 생성
pr <- ROCR::prediction(예측값, 실제값)
- ROC 곡선 그래프 생성
prf <- performance(pr, measure='tpr', x.measure='fpr') plot(prf)
- AUC 면적 구하기
auc <- performance(pr, measure='auc') auc auc <- auc@y.values auc # 0.8711844 good 수준
📌 9. 예측
new_data <- train[c(1,3),] new_data <- edit(new_data) new_pred <- predict(model, newdata=new_data, type='response') ifelse(new_pred > 0.5, 1, 0)

데이터 사이언티스트를 목표로 하는 개발자