📊 의사결정나무(Decision Tree)
📌 R 의사결정나무(Decision Tree)
- 모델 소개
[ 의사결정나무는 주어진 입력값들의 조합에 대한 의사결정규칙(rule)에 따라 출력값을 예측하는 모델]- 회귀와 분류 문제에 모두 사용 가능
- 종속 변수와 가장 연관성이 높은 변수의 순서대로 Gini 계수 또는 엔트로피가 낮아지는 방향으로 분할하는 분류기법ctree(formula=formula, data=train)
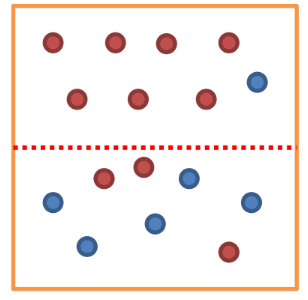
- 의사결정나무에서 순도와 불순도
- 순도 : 한 영역에서 2개 이상의 종속변수가 섞이지 않고 온전히 하나의 종속변수만 있는 비율의 척도
- 불순도 : 한 영역에서 2개 이상의 종속변수가 존재하는 비율의 척도
[ 순도와 불순도는 trade-off 관계 ]
위 그림에서 위 영역의 순도는 높고 불순도는 낮다. 아래 영역의 순도는 낮고 불순도는 높다.
- 문제점
- 높은 분산
- 트리 분할은 데이터에 크게 반응하여 작은 변화에도 크게 변화를 가져온다.
📊 랜덤포레스트 (Random Forest)
📌 R 랜덤포레스트 (Random Forest)
- 모델 소개
[ 여러 개의 Decision Tree를 앙상블 기법으로 묶어 사용하는 모델 ]- 정확성, 단순성, 유연성으로 인해 가장 많이 사용하는 모델이다.
randomForest(Species ~ ., data=train, importance=T, na.action=na.omit)

📌 R 배깅 (Boostrap Aggregation)
- 배깅 (Boostrap Aggregation)
- Boostrap : 복원추출을 사용한 표본 추출 방법
- Aggregation : 통합- 배깅 : 부트스트랩을 여러번 반복해서 여러 훈련세트를 만들고 각 훈련세트에 각각 다른 의사결정트리 모델을 적용하여 그 결과 값의 평균을 냄으로써, 분산을 줄인다.
📌 R 부스팅 (Boosting)
- 부스팅 (Boosting)
- 배깅과 같이 부트스트랩을 이용한 샘플을 반복적으로 뽑는다.
- 여기서 하나의 의사결정트리를 뽑을 때마다, 예측값과 실제값의 잔차를 확인
- 다음 의사결정트리를 뽑을 때는 이전의 잔차보다 작은 잔차를 갖도록 가중치/확률을 부여
📊 나이브 베이즈 분류 모델
📌 R Naive Bayes 분류 모델
- 모델 소개
조건부 확률을 사용하는 분류 모델naiveBayes(Species ~ ., data=train)
📊 서포트 벡터 머신 (SVM)
📌 R SVM 모델
- 모델 소개
분류를 위한 기준 선(결정 경계)을 정의하는 모델- 차원 확대 : 저차원 -> 고차원
- 결정 경계 : 선 -> 평면 -> 초평면(고차원 형태)
- 새로운 점을 만나면 기준 선을 기반으로 어떤 종속변수에 속하는지 분류함naiveBayes(Species ~ ., data=train)

📊 KNN (K Nearest Neighbors)
📌 R KNN 모델
- 모델 소개
K개의 가까운 이웃의 속성에 따라 분류하는 모델- 거리 측정 방법 : 유클리드 거리
naiveBayes(Species ~ ., data=train)
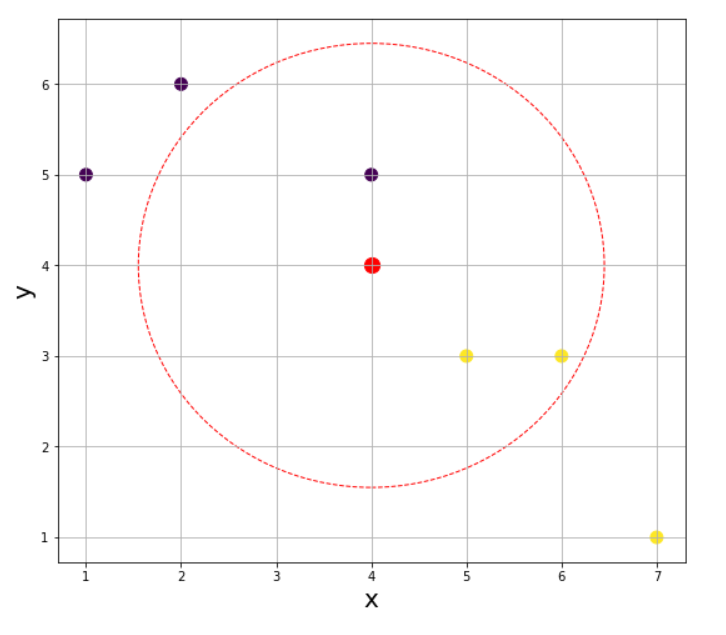
📌 R KNN - K 구하기
- K 값
일반적으로 3, 5, 7, .... 과 같이 홀수 값으로 k를 지정한다.

데이터 사이언티스트를 목표로 하는 개발자