
📊 다중선형회귀 절차
📌 R 상관관계 분석
- 상관계수
- 상관계수가 0.2 이상일 때 , 상관관계가 존재하므로 해당 상관계수를 갖는 확률변수를 사용
📌 R 인과관계 분석
- 인과관계 분석은 분석가의 판단에 맡긴다.
📌 R 다중선형회귀 모델
- 모델 생성
- 독립변수 : 2개 이상
- 종속변수 : 1개lr <- lm(formula=레이블 ~ 칼럼1+칼럼2+...., data=데이터세트)
📌 R 모델 요약 통계량 평가
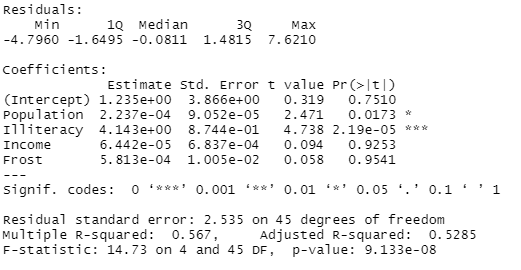
- 개별 칼럼 p-value 분석
- 유의수준 0.05 이상인 값을 갖는 개별 칼럼은 제거해야할 대상이다.
- R-squared
- 너무 낮아도, 너무 높아도 실무에서 사용하기 어려운 모델이다.
📌 R 모델 적절성 평가1
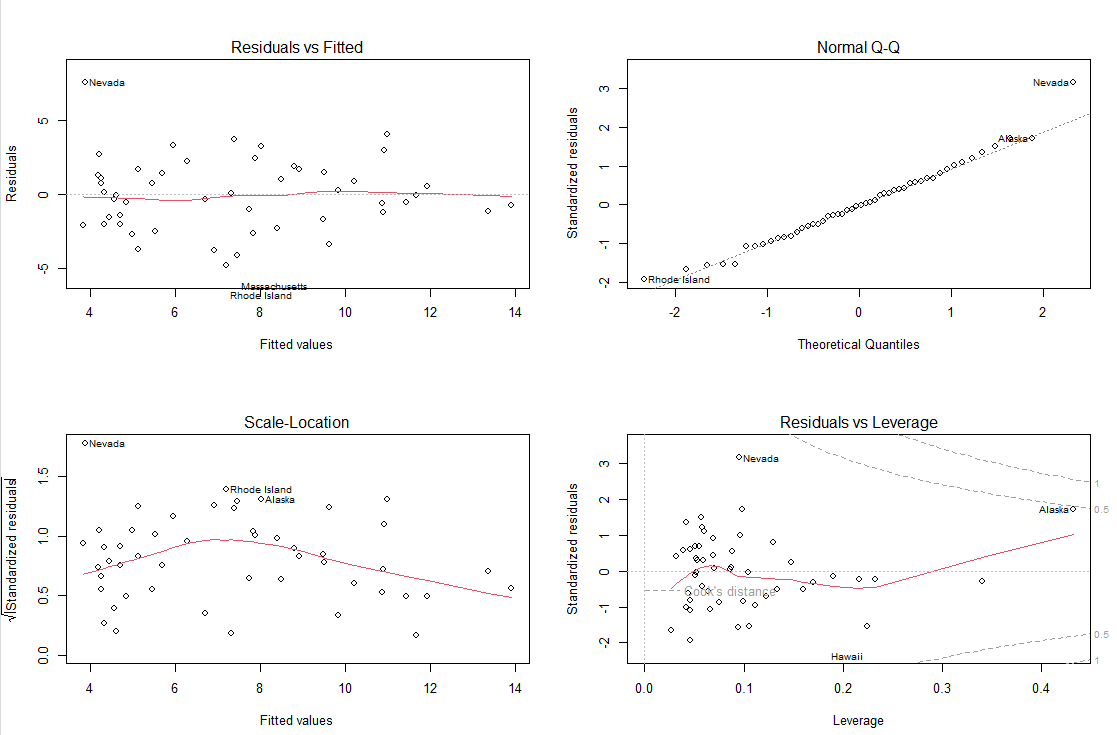
1. 선형성
- 평균이 0인 분산을 그리는 점선에 수렴하는 선을 그리는 것이 선형성이 높은 모델
2. 정규성
- 1차 방정식 선에 독립변수들이 수렴하도록 하는 것이 정규분포를 그리는 것이므로 정규성이 높은 모델이다.
3. 등분산성
- 일정 패턴을 그리지 않는 것
- 방정식의 차원이 낮을수록 그래프의 패턴은 단순해짐. 즉, 패턴이 명확해지므로 등분산성은 낮은 모델이다.
4. 이상치 그래프
- Leverage가 길수록 이상치에 가까운 독립변수라는 의미이다.
📌 R 모델 적절성 평가2
- 필요 라이브러리 설치
install.packages("car") library(car)
- 정규성 검정
- p-value가 0.05보다 클수록 정규성이 만족한다.
- 만족하지 않으면 이상치가 많다는 의미shapiro.test(residuals(다중선형회귀모델))
- 독립성 검정
- D-W Statistic 통계치를 확인
- 0 ~ 4사이의 값을 갖는다.
- 2에 가까울수록 자기상관관계가 없다. (= 독립성 만족)durbinWatsonTest(다중선형회귀모델)
- 선형성 검정
- 개별 칼럼의 p-value를 확인한다.
- p-value가 0.05보다 크면 선형성을 만족한다.boxTidwell(레이블 ~ 칼럼1+칼럼2+...., data=데이터세트)
- 등분산성 검정
- p-value를 확인한다.
- p-value가 0.05보다 크면 등분산성을 만족한다.ncvTest(다중선형회귀모델)
- 다중공선성 검정
- 출력되는 개별 칼럼의 값들이 10을 넘으면 다중공선성을 만족하지 않는다._vif(다중선형회귀모델)

데이터 사이언티스트를 목표로 하는 개발자