76일차 시작....
[교육] R

📊 기술통계와 추론통계
📌 R 기술통계
- 기술 통계
- 수집한 데이터의 특성을 표현하고 요약하는 통계 기법
- 평균, 분산, 표준편차 등
- 데이터에 대해 수치적으로 요약정보를 표현하거나, 데이터 시각화한다.
↪ 즉, 자료의 특징을 파악하는 관점
📌 R 추론통계
- 추론 통계
- 샘플을 통해서 모집단의 모수(평균, 분산, 표준편차 등)를 추론하는 통계 기법
- 모집단의 모든 데이터를 조사할 수 없을 때, 유용하다.
📊 feature scaling
📌 R 표준화
- 표준화
- 데이터를 평균을 기준으로 읽을 때, 평균이 0이 아닌 다른 값을 갖고 있으면 평균을 0으로 만들고 표준편차를 1로 만든다.
- 표준정규분포의 속성을 갖도록 평균은 0, 표준편차는 1로 만드는 작업
- 평균과 표준편차
- 표준화 수식
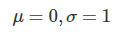

📌 R 정규화
- Min-Max Scaling
- 모든 데이터(피처, 독립변수) 값의 범주를 정확하게 [0, 1] 사이에 위치하도록 데이터를 변경하는 작업
- 최대값과 최소값을 사용하여 원래 데이터의 최소값을 0, 최대값을 1로 만드는 방법
- 정규화 수식
- (feature - 최소값) / (최대값 - 최소값)
📌 R 표준화와 정규화 차이점
- 차이점
- 표준화는 최소값, 최대값을 제한하지 않으므로 특정 데이터의 이상치(outlier) 값을 파악할 수 있다.
- 그러므로 표준화는 이상치 제거가 가능하다.
📌 R 변동계수
- 변동계수
- 평균이 크게 차이가 나는 두개 이상의 집단 사이의 상대적 동질성을 감안한 산포도 척도
- 간단하게, 평균이 크게 다른 두 개 이상의 집단의 동질성을 파악하기 위한 도구# 예) 3개의 샘플에 대해 2명의 관측자가 물 용량을 측정한 데이터가 있다. tom <- c(54, 50, 52) # 물 : L 단위 측정 james <- c(54017, 49980, 52003) # 물 : ml 단위 측정 mean(tom) # tom 평균 : 52 mean(james) # james 평균 : 52000 sd(tom) # tom 표준편차 : 2 sd(james) # james 표준편차 : 2018.502 sd(tom) / mean(tom) # 0.03846154 sd(james) / mean(james) # 0.03881734 # 변동계수를 사용함으로써 두개의 데이터 간의 동질성을 파악할 수 있다.
📊 두 확률변수 간의 패턴 찾기
📌 R 공분산
- 공분산이란?
- 두 개 이상의 독립변수 사이의 상관관계 방향(+ or -)을 파악하기 위한 척도
- 공분산 분포도
- 2개 이상의 feature(X, Y)에 대해 각 데이터들을 2차원 그래프에 찍는다.
- 그래프에 사분위수를 그린다.
- 각 데이터들의 사분위수에 의한 분포도를 확인할 수 있다.
- 특징
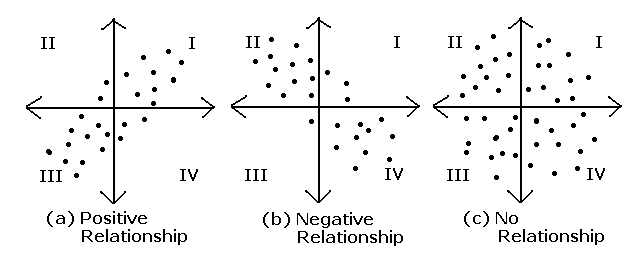
- 공분산이 양수(+)일 경우, 많은 데이터들이 1사분면과 3사분면에 분포함 [우상향 그래프]
- 공분산이 음수(-)일 경우, 많은 데이터들이 2사분면과 4사분면에 분포함 [우하향 그래프]- 공분산이 0일 경우, 관측값들이 4개의 면에 균일하게 분포함 [원형 그래프]
↪ 두 feature 간에 어떠한 선형관계가 없으며, 서로 완전 독립적이다.
- 공분산 그래프
- 공분산의 문제점
- 공분산은 단순한 상관관계의 방향만을 알려준다.
- 상관관계의 크기(세기)는 알 수 없다.
→ 상관계수로 해결
📌 R 상관계수
- 상관계수
- 두 개 이상의 feature(X, Y)가 상관 관계를 갖는지를 방향성, 크기를 나타내는 척도
- 공분산을 표준화한 것
- 상관계수 표
- 0.2~0.25 이상의 상관계수를 가져야 의미있는 인사이트를 도출할 수 있음

📊 최소제곱법을 통한 최적의 기울기 구하기
📌 R 모델 y=wx+b의 기울기, 절편 구하기
- 기울기(w) 구하기
Σ(x - mean_x)(y - mean_y) / Σ(x - mean_x)^2
- 절편(b) 구하기
mean(y) - 기울기 * mean(x)
📌 R 최소제곱법을 이용해 최적의 값 찾기
* 잔차 : 예측값 - 실제값
* 비용함수 = Σ(예측값 - 실제값)^2
* 최소제곱법
- 비용함수(cost)가 가장 작아지는 지점의 기울기(a)와 절편(b)을 얻어 내는 방법
- 기울기(a)를 구하기 위해서는 미분을 해야 한다.
[ 용어 정리 ]
비용함수 == cost == 손실함수 == loss
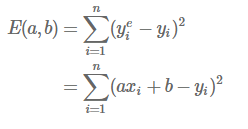
📊 선형회귀모델 평가
📌 R 평가 - 모델 요약 통계량 분석
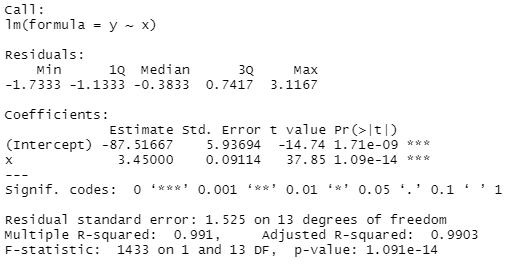
- p-value
- 모델이 유의미한 결과를 도출하는지 알려주는 척도
- 유의수준 0.05 이하일 때, 모델이 유의미한 결과를 도출한다고 판단할 수 있다.
- R-squared
- 결정 계수
- 독립변수가 종속변수 분산을 얼마나 잘 설명(결정)하는지 나타내는 척도
- 결정 계수가 높으면 독립변수가 종속변수 분산을 잘 설명하는 모델이다.[ 참고 ]
- 단순선형회귀 분석 : Multidual R-squared 척도 사용
- 다중선형회귀 분석 : Adjusted R-squared 척도 사용
- 너무 낮거나 너무 높은 모델은 실무에서 사용하기에 문제가 있는 모델이다.
- Standard Error
- 표준 오차
- 독립변수의 분포도(산포도)를 나타냄
- 값이 낮을수록 밀도가 높음
- 차이가 작으면 독립 변수에서 이상치를 갖는 변수가 많지 않다는 의미
📌 R 평가 - 모델 적절성 분석
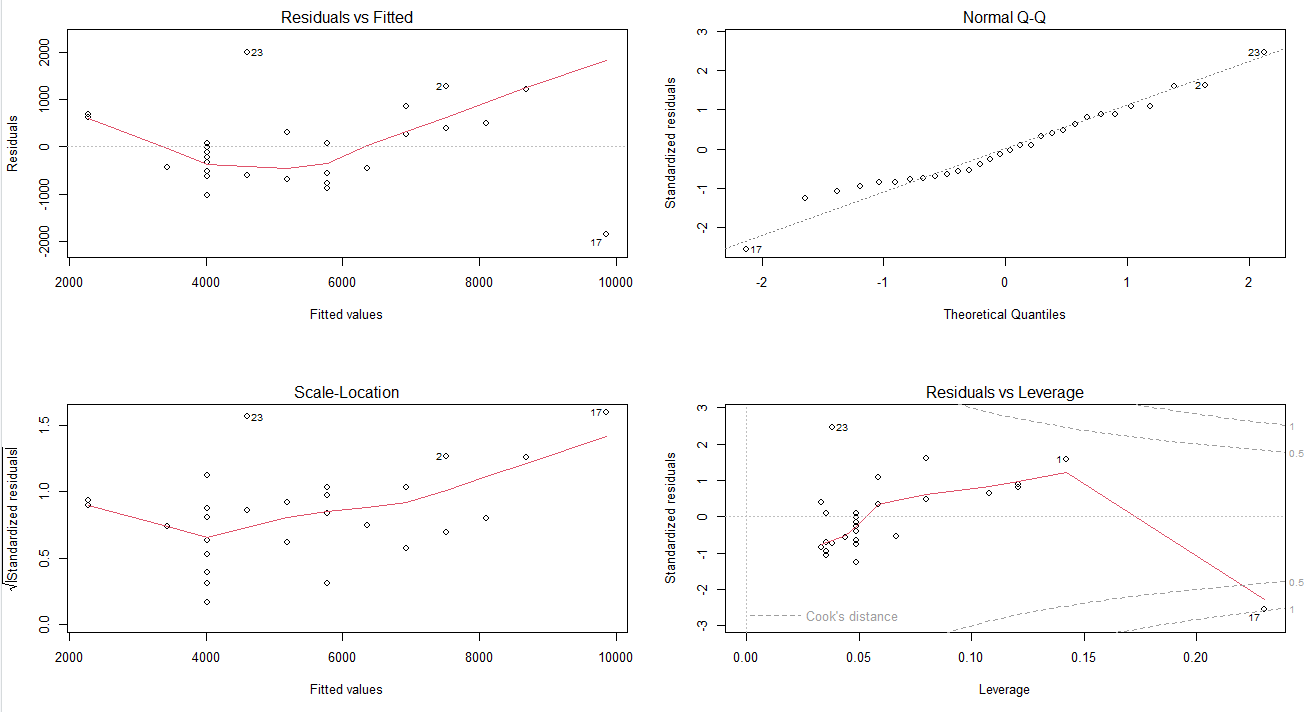
1) 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다.
-> 정규분포를 그릴 수 있기 때문에 일차방정식 선에 잘 따라가야한다.2) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다. (ex. 친족 데이터는 서로 관련되어 있다.)
3) 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 일정한 패턴을 가지면 좋지 않다.
4) 등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다.
5) 다중공선성 : 독립변수들과 종속변수y 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다.
