📌 R 데이터프레임
- 데이터프레임
- 행(row) :
- 열(column) : 차원, 변수
📌 R 통계
- 통계 용어
- 모집단(population) : 전체 데이터를 의미
- 모수(parameter) : 모 평균, 모 표준편차, 모 분산 등 모집단의 통계적 특성치를 의미
- 표본집단(sample) : 모집단 중에서 일부를 무작위 추출한 데이터를 의미
↪ 표본 측정 후, 모집단의 특성을 파악함
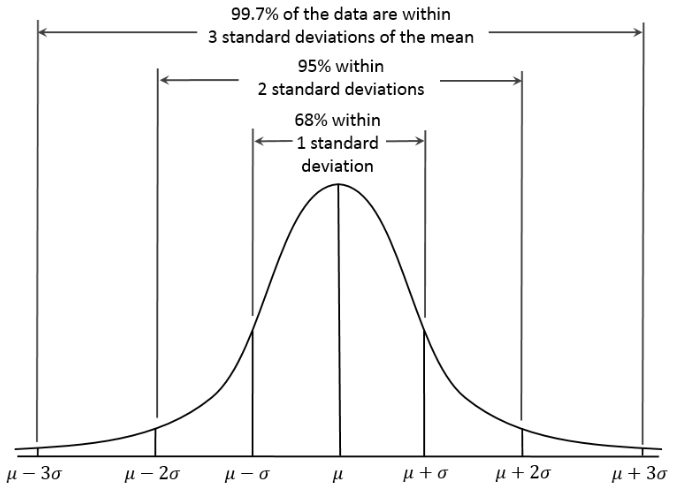
- 정규 분포
- 평균을 기준으로 좌우 대칭이 되는 분포 그래프
- 종 모양을 그리는 그래프
- 중심극한정리 : 표본분포에서 평균값에 데이터들이 모이는 현상을 의미
- 왜도 : 분포가 정규분포에 비해 얼마나 왜곡 되었는지 나타내는 척도
- 첨도 : 분포의 뾰족한 정도를 나타내는 척도
📌 R 연산자
- 산술
+, -, *, /, %%, ^, **
- 관계
==, !=, >, >=, <, <=
- 논리
&, |, !, xor()
📌 R 제어문1
- if 함수
if(x + y >= 10) { cat('결과는 ', x+y) } else { cat('10을 넘지 않습니다.') a = 10 }
- ifelse 함수 (= 3항 연산자)
ifelse(x >= 5, 'a1', 'a2')
- switch 함수
switch('age', id='hong', age=22) a <- 1 switch(a, mean(1:10), sd(1:10)) a <- 2 switch(a, mean(1:10), sd(1:10))
- which 함수
- 조건에 부합하는 값이 몇번째 인덱스에 있는지 반환name <- c('kor', 'eng', 'mat', 'kor') which(name == 'kor')
📌 R 제어문2
- for 함수
su <- 1:10 for(n in su) { print(n) }
- while 함수
i <- 0 while(i < 10) { i = i + 1 print(i) }
- repeat 함수
cnt <- 1 repeat { print(cnt) cnt = cnt + 1 if(cnt > 10) break }
📌 R 함수
- 내장 함수
- seq(시작값, 종료값, by=증가값) : 숫자형의 sequence를 생성
- rnorm(개수, mean=평균값, sd=표준편차값) : 난수를 생성
- sample(백터값, 추출개수) : 모집단에서 특정 개수만큼의 표본을 추출
- min(백터값) : 최솟값
- max(백터값) : 촤댓값
- range(백터값) : 범위
- mean(백터값) : 평균
- median(백터값) : 중앙값
- var(백터값) : 분산
- sqrt(var(백터값)) or sd(백터값) : 표준편차
- sd(백터값) / mean(백터값) : 변동 계수
- quantile(백터값) : 4분위 수
- sum(백터값) : 합계
- 사용자 정의 함수
func1 <- function(arg) { print(arg) return(arg + 10) } func1(10)
📌 R 스크래핑
- 라이브러리 설치
install.packages('httr') library(httr) install.packages('XML') library(XML) install.packages('rjson') library(rjson)
- 웹 스크래핑
1. url 준비
2. htmlParse(rawToChar(GET(url)$전체태그))
3. xpathSApply(source, "//태그명[@class='클래스값']", xmlValue)
4. gsub('[\r\n\t]', "", text) : 정규표현식으로 개행문자 제거
- XML 스크래핑
1. url 준비
2. GET(url)
3. xmlTreeParse(r, useInternal=T)
4. xmlRoot(doc)
5. xmlSApply(rootNode, xmlValue)
6. xpathSApply(rootNode, "//LBRRY_NAME", xmlValue)
- JSON 스크래핑
1. url 준비
2. fromJSON(file=url)
3. data.frame(doc)
📌 R 시각화 (그래프)
- 시각화 종류
- 이산변수 : 막대, 점, 원형 등
- 연속변수 : 박스, 히스토그램 등
- 막대 그래프
- barplot(숫자데이터, xlab=x이름, ylib=y이름, col=색깔, main=제목)
- par(mfrow=c(1,2)) : 하나의 출력 공간에 2열을 사용할 수 있다.
- 점 차트
- dotchart(숫자데이터, color=색깔, lcolor=라인 색깔)
- 원 그래프
- pie(숫자데이터, labels=레이블명, lty=라인 종류)
- boxplot
- boxplot(숫자데이터, range=범위)
- histogram
- hist(숫자데이터, breaks=사이 거리)
- plot
- plot(x=x데이터, y=y데이터)
📌 R 데이터전처리
- 결측치(Missing Value) 제거
- na.omit(column의 row 데이터)
- 데이터프레임$칼럼명[is.na(데이터프레임$칼럼명)] <- 0
- 극단치(outliner) 제거
- data <- subset(데이터프레임, 데이터프레임$칼럼명 == ?) : 특정 조건을 만족하는 데이터만 치환
📌 R DB 연동
- 라이브러리 설치
# RJDBC api를 사용 install.packages('rJava') install.packages('DBI') install.packages('RJDBC') library(rJava) library(DBI) library(RJDBC)
- 원격 DB 연동
drv <- JDBC(driverClass="org.mariadb.jdbc.Driver", classPath="C:/work/mariadb-java-client-2.6.2.jar") conn <- dbConnect(drv=drv, "jdbc:mysql://127.0.0.1:3306/test", "root", "123") dbListTables(conn) # 레코드 조회 query <- "SELECT * FROM sangdata" result <- dbGetQuery(conn, query) result # 레코드 추가 iquery <- "INSERT INTO sangdata VALUES(30, '핸드크림', 34, 15000)" dbSendUpdate(conn, iquery) # 레코드 수정 query <- "UPDATE sangdata SET sang='맛있는 립밤' WHERE code=31" dbSendUpdate(conn, query) # 레코드 삭제 dbSendUpdate(conn, "DELETE FROM sangdata WHERE code=29")

데이터 사이언티스트를 목표로 하는 개발자