
📊 CNN 알고리즘
📌 CNN이란?
- 정의
- 원본 이미지의 리소스를 줄이기 위해 이미지를 축소하여 특징만 추출하는 알고리즘
- Dense층에서 이미지를 분류하기 위해 이미지 리소스를 최소화하기 위해 이미지를 축소하는 작업
- 방법
- Filter : 이미지에서 축소할 N x N 행렬로 합성곱 축소하기 위한 행렬값
- stride : 이미지에서 Filter를 몇 칸을 움직일지 지정
- padding : 이미지에서 Filter를 이용해 합성곱 축소를 하는데, padding을 적용하면 원본 크기에서 더이상 축소되지 않는다.
- pooling : 전체 합성곱 층으로 구성하면 이미지는 축소하지만 크기가 기하급수적으로 커진다. 이를 방지하기 위해 합성곱 층 중간 중간마다 이미지의 크기를 줄이고, 특징을 강조시킬 수 있는 작업이다.
📊 CNN 네트워크 실습
📌 CNN 네트워크 실습
1. 라이브러리 Import
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.models import Model from keras.layers import Input, Conv2D, MaxPool2D, Dropout, Flatten, Dense from keras.callbacks import EarlyStopping
2. 데이터 준비
(x_train, y_train), (x_test, y_test) = mnist.load_data() print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) # (60000, 28, 28) (10000, 28, 28) (60000,) (10000,)
3. 데이터 차원 확장
- CNN은 채널을 사용하기 때문에 3차원 데이터를 4차원으로 변경[ 4차원 데이터 ]
- (총데이터개수, 행, 열, channel값)x_train = x_train.reshape((60000, 28, 28, 1)) # 흑백은 channel이 1개 x_test = x_test.reshape((10000, 28, 28, 1)) print(x_train.shape, x_test.shape) # (60000, 28, 28, 1) (10000, 28, 28, 1)
4. feature 정규화
x_train = x_train / 255.0 x_test = x_test / 255.0
5. CNN 구축
inputs = Input(shape=(28, 28, 1)) # CNN 층 # - filters 속성 : 필터 개수 # - kernel_size 속성 : 커널 행, 열을 지정 # - strides 속성 : 이동 보폭을 지정 # - padding 속성 : 겉에 채울 값을 지정 conv1 = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), padding='valid', activation='relu')(inputs) # Pooling 층 # - 컨볼루션 층을 거친 데이터의 특징을 더 잘 뽑기 위한 층 pool1 = MaxPool2D(pool_size=(2,2))(conv1) drop1 = Dropout(rate=0.2) conv2 = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='valid', activation='relu')(pool1) pool2 = MaxPool2D(pool_size=(2,2))(conv2) drop1 = Dropout(rate=0.2) # Flatten 층 # - 2차원을 1차원으로 차원 축소하여 Dense 층에서 사용가능하게끔 만든다. flatten = Flatten()(pool2) # 완전 연결 층 net1 = Dense(units=64, activation='relu')(flatten) net2 = Dense(units=32, activation='relu')(net1) outputs = Dense(units=10, activation='softmax')(net2) model = Model(inputs, outputs)
5. 모델 학습 최적화 설정
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
6. 모델 학습
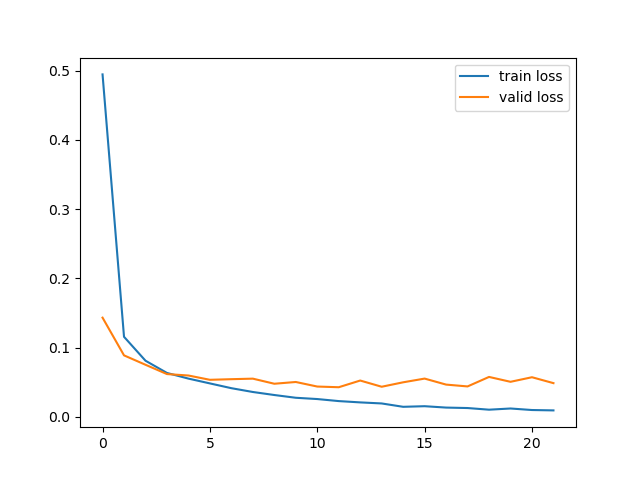
es = EarlyStopping( monitor='val_loss', patience=10 ) history = model.fit( x=x_train, y=y_train, batch_size=256, epochs=100, validation_split=0.2, callbacks=[es], verbose=0 ) plt.plot(history.history['loss'], label='train loss') plt.plot(history.history['val_loss'], label='valid loss') plt.legend() plt.show()
7. 모델 검증
loss, acc = model.evaluate( x=x_test, y=y_test, batch_size=256, verbose=0 ) print('loss : ', loss) print('acc : ', acc) # loss : 0.05373070016503334 # acc : 0.9872999787330627
8. 모델 예측값, 실제값 비교
y_pred = model.predict(x_test) y_pred = np.argmax(y_pred) print(y_pred) print('예측값 : ', y_pred[:2]) print('실제값 : ', y_test[:2])

데이터 사이언티스트를 목표로 하는 개발자