
📊 방법1 - Sequential API
📌 Sequential API
- 정의
- Layer의 Node를 순서대로 쌓아 올린 완전 연결층 구성 방법이다.
- 모델 구성이 매우 단순하거나 융통성 없이 구성 가능한 환경에서 사용한다.
📌 Sequential API 실습
1. 라이브러리 Import
import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Activation from keras.optimizers import Adam import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import r2_score
2. 데이터 준비
x_data = np.array([1,2,3,4,5], dtype=np.float32) y_data = np.array([10, 32, 55, 73, 90], dtype=np.float32)
3. 상관관계 분석
print('상관계수 : ', np.corrcoef(x_data, y_data)[0][1]) # 상관계수 : 0.9977920425012702 # -> 양의 방향으로 매우 강한 상관관계를 갖는다.
4. 인과관계 분석
# ols모델의 p-value가 0.05(유의수준) 안에 존재하면 유의한 관계를 갖는다고 판단
5. Sequential API를 사용해 모델 구축
model = Sequential() model.add(Dense(units=10, input_dim=1, activation='relu')) model.add(Dense(units=5, activation='relu')) model.add(Dense(units=1, activation='linear')) print(model.summary()) # Model: "sequential" # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # dense (Dense) (None, 10) 20 # # dense_1 (Dense) (None, 5) 55 # # dense_2 (Dense) (None, 1) 6 # # ================================================================= # Total params: 81 # Trainable params: 81 # Non-trainable params: 0
6. 모델 학습 최적화 설정
model.compile(optimizer=Adam(learning_rate=0.01), loss='mse', metrics=['mae'])
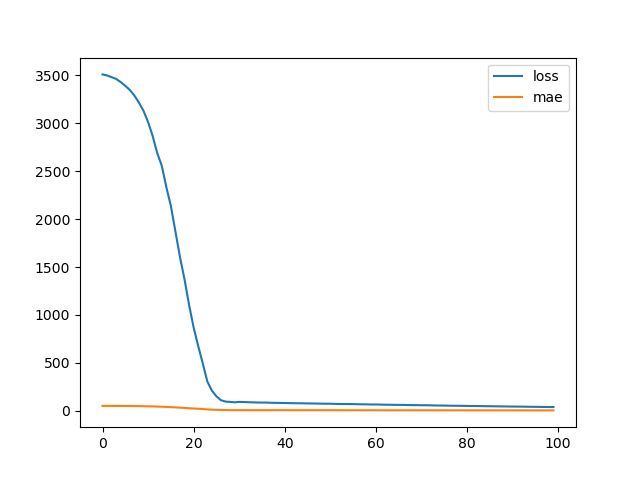
7. 모델 학습 및 히스토리(loss, mae) 시각화
history = model.fit(x_data, y_data, batch_size=1, epochs=100, verbose=0) plt.plot(history.history['loss'], label='loss') plt.plot(history.history['mae'], label='mae') plt.legend() plt.show()
8. 모델 평가
loss, mae = model.evaluate(x_data, y_data, batch_size=1, verbose=0) print('loss : ', loss) print('mae : ', mae) # loss : 15.66783618927002 # mae : 3.110996961593628
9. 모델 예측값
pred = model.predict(x_data) print('예측값 : ', pred.flatten()) print('실제값 : ', y_data) # 예측값 : [17.6935 35.537437 53.38138 71.22532 89.06926 ] # 실제값 : [10. 32. 55. 73. 90.]
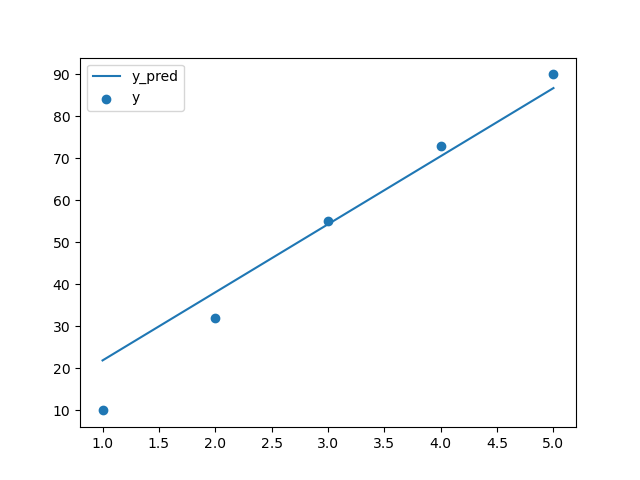
10. 회귀선 시각화
plt.plot(x_data, pred.flatten(), label='y_pred') plt.scatter(x_data, y_data, label='y') plt.legend() plt.show()
11. 회귀모델 성능 지표 - 성명력 확인
print('설명력 : ', r2_score(y_data, pred.flatten())) # 설명력 : 0.9806951403823494 # -> feature가 label의 분산을 98.0% 설명한다. # -> 높은 설명력 # -> 모델 정확성 만족
12. 실제 예측
new_data = [1.5, 2.3, 5.7] print('성적 예측값 : ', model.predict(new_data).flatten()) # 성적 예측값 : [ 26.615473 40.890617 101.56001 ]
📊 방법2 - Functional API
📌 Functional API
- 정의
- Sequential API 보다는 유연한 구조
- 입력 데이터로 여러 층을 공유하거나 다양한 종류의 입출력 가능 → 스킵연결 오토인코더
📌 Functional API 실습
1. 라이브러리 Import
from keras.models import Model from keras.layers import Input, Dense from keras.optimizers import Adam import numpy as np import matplotlib.pyplot as plt from sklearn.metrics import r2_score
2. 데이터 준비
x_data = np.array([1,2,3,4,5], dtype=np.float32) y_data = np.array([10, 32, 55, 73, 90], dtype=np.float32)
3. 상관관계 분석
print('상관계수 : ', np.corrcoef(x_data, y_data)[0][1]) # 상관계수 : 0.9977920425012702 # -> 양의 방향으로 매우 강한 상관관계를 갖는다.
4. 인과관계 분석
# ols모델의 p-value가 0.05(유의수준) 안에 존재하면 유의한 관계를 갖는다고 판단
5. Functional API를 사용해 모델 구축
inputs = Input(shape=(1,)) hidden1 = Dense(units=10, activation='relu')(inputs) hidden2 = Dense(units=5, activation='relu')(hidden1) outputs = Dense(units=1, activation='linear')(hidden2) # 이전 층을 다음 층 함수의 입력으로 사용하도록 변수에 할당 model = Model(inputs, outputs) # 모델 객체 인자값에는 입력층, 출력층의 객체만 지정한다. print(model.summary()) # Model: "model" # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # input_1 (InputLayer) [(None, 1)] 0 # # dense (Dense) (None, 10) 20 # # dense_1 (Dense) (None, 5) 55 # # dense_2 (Dense) (None, 1) 6 # # ================================================================= # Total params: 81 # Trainable params: 81 # Non-trainable params: 0
6. 모델 학습 최적화 설정
model.compile(optimizer=Adam(learning_rate=0.1), loss='mse', metrics=['mae'])
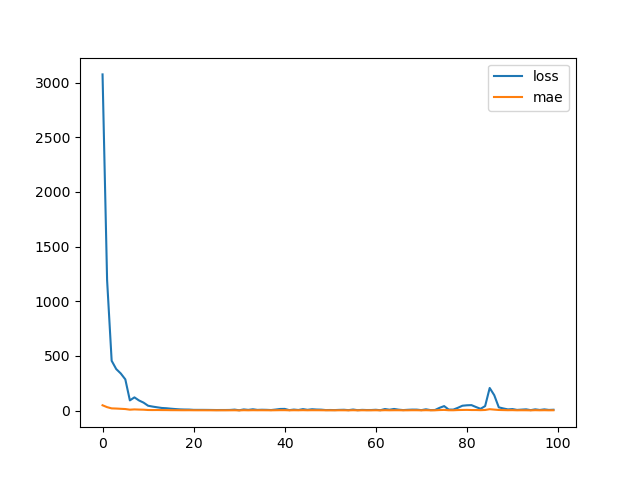
7. 모델 학습 및 히스토리(loss, mae) 시각화
history = model.fit(x_data, y_data, batch_size=1, epochs=100, verbose=0) plt.plot(history.history['loss'], label='loss') plt.plot(history.history['mae'], label='mae') plt.legend() plt.show()
8. 모델 평가
loss, mae = model.evaluate(x_data, y_data, batch_size=1, verbose=0) print('loss : ', loss) print('mae : ', mae) # loss : 4.061620235443115 # mae : 1.6898635625839233
9. 모델 예측값
pred = model.predict(x_data).flatten() print('예측값 : ', pred) print('실제값 : ', y_data) # 예측값 : [12.449326 32.571312 52.6933 72.815285 92.93726 ] # 실제값 : [10. 32. 55. 73. 90.]
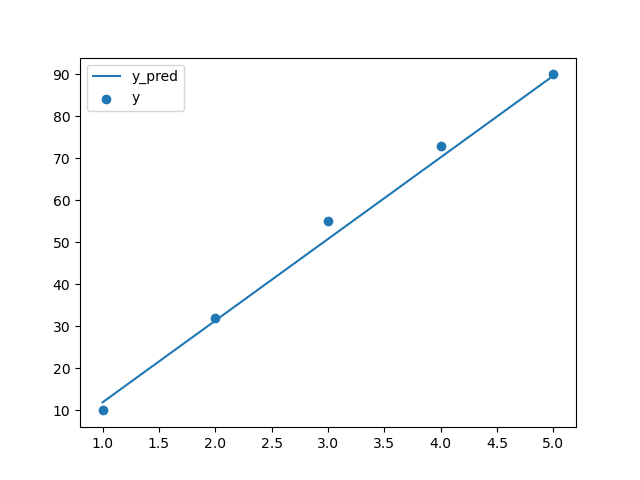
10. 회귀선 시각화
plt.plot(x_data, pred, label='y_pred') plt.scatter(x_data, y_data, label='y') plt.legend() plt.show()
11. 회귀모델 성능 지표 - 성명력 확인
print('설명력 : ', r2_score(y_data, pred)) # 설명력 : 0.994995539133084
📊 방법3 - Sub Classing
📌 Sub Classing
- 정의
- 동적인 구조가 필요한 경우 사용한다.
- 메소드를 통해 분석가의 생각을 프로그래밍할 수 있다.
- multi-input, multi-output model : 다중입출력 모델로써 데이터 흐름이 순차적이지 않은 경우에도 사용 가능하다.
📌 Sub Classing 실습
1. 라이브러리 Import
from keras.models import Model from keras.layers import Dense from keras.optimizers import Adam import numpy as np from sklearn.metrics import r2_score
2. 데이터 준비
x_data = np.array([[1], [2], [3], [4], [5]], dtype=np.float32) y_data = np.array([10, 32, 55, 73, 80], dtype=np.float32)
3. 상관관계 분석
print('상관계수 : ', np.corrcoef(x_data.flatten(), y_data)[0][1]) # 상관계수 : 0.9977920425012702 # -> 양의 방향으로 매우 강한 상관관계를 갖는다.
4. 인과관계 분석
# ols모델의 p-value가 0.05(유의수준) 안에 존재하면 유의한 관계를 갖는다고 판단
5. Sub Classing을 사용해 모델 구축
class MyModel(Model): def __init__(self): super(MyModel, self).__init__() # 생성자 내에서 필요한 layer를 생성한 후 call 메소드에서 수행하려는 연산을 적어줌 self.d1 = Dense(10, activation='relu') self.d2 = Dense(5, activation='relu') self.d3 = Dense(1, activation='linear') def call(self, x): inputs = self.d1(x) hidden = self.d2(inputs) return self.d3(hidden) model = MyModel()
6. 모델 학습 최적화 설정
model.compile(optimizer=Adam(learning_rate=0.1), loss='mse', metrics=['mae'])
7. 모델 학습 및 히스토리(loss, mae) 시각화
history = model.fit(x_data, y_data, batch_size=1, epochs=100, verbose=0) plt.plot(history.history['loss'], label='loss') plt.plot(history.history['mae'], label='mae') plt.legend() plt.show()
8. 모델 평가
loss, mae = model.evaluate(x_data, y_data, batch_size=1, verbose=0) print('loss : ', loss) print('mae : ', mae) # loss : 4.061620235443115 # mae : 1.6898635625839233
9. 모델 예측값
pred = model.predict(x_data).flatten() print('예측값 : ', pred) print('실제값 : ', y_data) # 예측값 : [12.449326 32.571312 52.6933 72.815285 92.93726 ] # 실제값 : [10. 32. 55. 73. 90.]
10. 회귀선 시각화
plt.plot(x_data, pred, label='y_pred') plt.scatter(x_data, y_data, label='y') plt.legend() plt.show()
11. 회귀모델 성능 지표 - 성명력 확인
print('설명력 : ', r2_score(y_data, pred)) # 설명력 : 0.994995539133084

데이터 사이언티스트를 목표로 하는 개발자