0. Summary
- Task : NMT에서의 Open-vocabulary problem
- Approach : Byte pair encoding 기법을 이용한 Subword units
- Results : rare & OOV에서 성능 좋다.
- review 전 나의 의문!
- Fast text의 subword (a bag of character n-grams)랑은 다른 개념인가?
- NN과 unsupervised가 다른건가..?
paper: https://aclanthology.org/P16-1162.pdf
code: paper안에 있음
1. Introduction
Background
-
open-vocabulary problem :
NMT에서는 Rare word가 항상 문제이다. 모델들은 주로 3만-5만 단어 정도의 vocab으로 한정되어 있는데, translation 같은 경우에는 vocab에는 없는 단어를 입력 또는 생성해야 하는 경우도 발생할 수 있다. -
Word level mechanisms :
word formation process가 agglutination이나 compounding으로 진행되는 특정 언어들 같은 경우는 translation을 할때 전체를 하나로 보는 것이 아니라(fixed-length vector) segment해서 word 단위로 봐야한다(variable-length representation).
agglutination (교착어): 어근에 접사가 결합 (ex. 한국어: 잡 +히다)
compounding (합성어): 어근끼리 결합해 새로운 단어 생성 (ex. 솜+사탕)
Example
독일어에 Abwasserbehandlungsanlange (= sewage water treatment plant, 하수처리장) 라는 단어가 있는데, 이 단어는 Abwasser|behandlungs|anlange 이런 식으로 끊어서 보는 것이 더 낫다고 함!
Limitation of Previous works
-
Dictionary Look-up (Jean et al., 2015)
기존 word-level NMT들은 OOV (out of vocab)문제를 해결하기 위해 dictionary look-up 방식을 사용했지만, 항상 source와 target언어 간에 1-1 매칭이 되는 게 아니라서 실제에 적용하기엔 무리가 있었다. -
Unseen words
기존 word-level 모델들은 unseen words에 대해선 번역이나 생성을 하지 못했다. Jean et al.(2015)에서는 처리가 안되는 애들은 그대로 copy해서 target text에 가져다 놓는 방식을 사용했는데, 형태학적(morphological)으로 안맞거나, 번역이 필요한 경우가 종종 있었다.
Our Goal
- To model open-vocabulary translation in the NMT network itself, without requiring a back-off model for rare words.
- To make translation process simpler.
Our Approach
- subword units
Result
- rare word를 번역하는데 large-vocab 모델보다 성능이 좋았다.
- unseen vocab에 대해서도 productively generate했다.
- subword representation을 가지고 NN모델이 compounding & transliteration을 학습할 수 있는 것을 확인했다.
Contribution
- Subword units를 통해 rare word를 encoding하여 Open-vocaburay NMT 가능케함. 본 연구에서 제안한 architecture는 large-vocab이나 back-off dictionaries쓴 모델보다 성능이 좋고, simple하다.
- word segmentation을 위해 Byte paire encoding (BPE)을 적용했다. BPE는 고정된 vocab안에서도 다양한 길이의 character sequence를 만들어 냄으로써 open-vocabulary representation 가능케 했다.
2. Neural Machine Translation
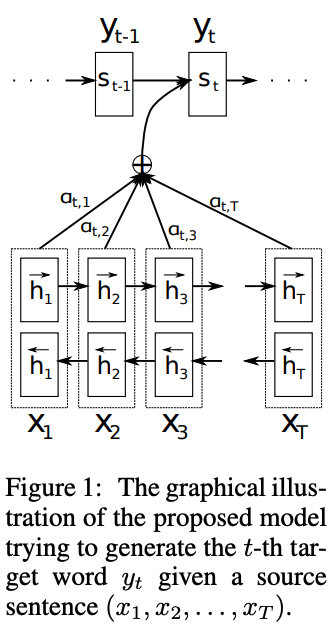
- Bahdanau et al. (2015)에서 제시한 NMT 모델 사용 (우리는 모델을 제안하는 논문이 아니다!)
- Encoder-Decoder 구조
- 다은 왈 : 나중에 Translation 시간에 깊게 다룹시다~
3. Subword Translation
Our hypothesis
- rare word를 적절하게 subword units로 segmentation한다면 충분히 NMT모델이 번역을 학습할 수 있으며, unseen words에 대해서도 produce할 수 있다.
본 연구에서 challenge하려는 Word categories
-
named entities : 언어가 바뀌어도 대명사 같은 경우는 그대로 copy되어야 하는 데 이때 transcription, transliteration이 필요하다. 특히 사용하는 알파벳이 다르다면 더더욱!
- transliteration : 들리는 소리 기반으로 mapping 하는 것 (ex. Trump -> 트럼프)
Barack Obama (English; German)
Барак Обама (Russian)
バラク・オバマ (ba-ra-ku o-ba-ma) (Japanese) -
cognates(동계어) and loanwords(외래어) : 같은 기원을 갖지만 언어별로 표현하는 방식이 달라서 character-level translation이 필요함. (ex. 프랑스어-독일어)
claustrophobia (English)
Klaustrophobie (German)
Клаустрофобия (Klaustrofobiâ) (Russian) -
morphologically complex words: 한 단어 안에 다양한 형태소를 갖고 있어서 형태소별로 번역이 가능할 수 있음; compounding, affixation (접사), inflection (굴절어))
- inflection (굴절어) : 문장 속에서 문법적 기능에 따라서 단어의 형태가 달라짐 (ex. 스페인어: 친구 amigo (남자), amiga (여자))
solar system (English)
Sonnensystem (Sonne + System) (German)
Naprendszer (Nap + Rendszer) (Hungarian) -
본 연구에서 사용하는 training data (german)에서 100개의 rare token을 분석한 결과, smaller units로 조작을 하면 대부분은 영어로 번역이 가능하다는 것을 확인함.
- 56 compounds
- 21 names
- 6 loanwords
- 5 affixatioin
- 1 number
- 1 computer language identifier
-
Task specific Subword units
- phone-level - speech recognition
- use syllabels - subword language models
- multilingual segmentation - multilingual segmentation task
=> inapplicable at test time
3.1. Related Work
- 이제까지 unseen data를 translation하기 위한 노력들
- Copying
- Character-based translation
- The segementation of morphologically complex words
- limitation of word-based approaches
- 여러 기술들을 NMT에 적용하고 있지만 word-based approach에서 크게 발전된 건 없다. (fixed length)
- Attention mechanism
- fix-length에 대한 word들 attention 사용해서 representation 뽑은게 있었는데, 우리와 같은 variable-length representation에 도움될 것 같다! 매 스텝마다 서로다른 subword units에 attention 줄 수 있지 않을까? (그럼 아까 처음 독일어처럼 합성어 같은 거는 attention 정보 이용해서 한 단어라는 거 알 수 있지 않겠냐!)
- NMT Vs. phrase-based method
- NMT는 vocab사이즈를 최소화하여 시간과 공간의 효율을 극대화 시키고, back-off model없이 translation이 가능하다. (phrase 기반은 통으로 vocab이 필요한듯! (과거 행태인ㄱㅏ?))
- 기존 : vocab & text size trade off를 조절하는 간단한 방법은 rare word에 대해서만 subword units를 사용해서 unsegmented words 리스트를 만드는 것이다. (전부 다에 대해 subword만들면 vocab너무 많아지고, 시간도 오래걸릴테니까 rare단어에 대해서만 적용하면 효과적일 듯 하다!)
- 우리 Byte pair encoding (BPE) 제안!
- NMT는 vocab사이즈를 최소화하여 시간과 공간의 효율을 극대화 시키고, back-off model없이 translation이 가능하다. (phrase 기반은 통으로 vocab이 필요한듯! (과거 행태인ㄱㅏ?))
3.2. Byte Pair Encoding (BPE)
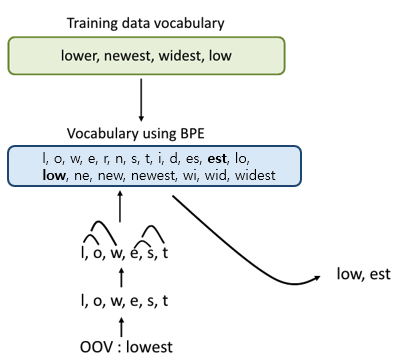 -
- - BPE(1994) 전통적 data compression 기술로, 자주 등장하는 byte pair를 하나의 sequence (unused byte)로 변경하는 것이다.
- 여기서는 BPE 기술에서 착안하여 byte가 아니라 character pair를 merge한다.
- Huffman encoding 같은 기존 compression 알고리즘과 다른 점은 BPE의 subword는 여전히 의미를 가질 수 있다는 것이다(interpretable).
- ex. lower => low,er
- Two methods of applying BPE
- BPE: source/target vocab에 대해 encoding 각자 학습
- joint BPE : source/target vocab 합쳐서 하나의 encoding 학습
BPE in NLP Implementation

import re, collections
def get_stats(vocab):
"""
token별로 pair만들어서 등장 횟수 count
"""
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
"""
best pair를 다시 merge해서 new vocab 만들기
#정규표현식
# re.escape() : 문자열의 특수문자 이스케이프 처리 "w i" -> "w\\ i"
# re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
- 뜻 : 앞에 공백 아닌 문자가 안와야하고 (=공백), 뒤에도 공백으로 이루어진 bigram
- \S: 공백X 문자
- ?<!: 앞에 포함 X
- ?! : 뒤에 포함 X
- ex. if bigram = "w i":
" w i d est" (있음)
" w idest" (없음)
# re.sub(정규 표현식, 치환 문자, 대상 문자열)
- 정규 표현식 : r'(?<!\S)' + "w\\ i" + r'(?!\S)'
- 치환 문자 : "wi"
- 대상 문자열 : "w i dest"
- 결과 :"wi dest"
"""
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w </w>' : 5,
'l o w e r </w>' : 2,
'n e w e s t </w>':6,
'w i d e s t </w>':3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(f"###### [epoch {i}] ######")
print(f"# pairs by frequency: {pairs.items()}")
print(f"# Best pair: {best}")
print(f"# New vocab: {vocab}\n")Implementation result

4. Evaluation
-
Emprirical Questions
- EQ 1 : Can we improve the translation of rare and unseen words in neural machine translation by representing them via subword units?
- EQ 2 : Which segmentation into subword units per- forms best in terms of vocabulary size, text size, and translation quality?
-
Dataset
- Training set : shared translation task of WMT 2015
- English -> German : 4.2m sentence pairs, 100m tokens
- English -> Russian : 2.6m sentence pairs, 50m tokens
- Development set: newstest2013
- Test set : newstest2014, newstest2015
- Training set : shared translation task of WMT 2015
-
Evaluation Metrics
- BLEU : precision bias
- CHR F3 (≒ n-gram F_3) : recall bias
- unigram F_1 (for eval the translation of rare words)
4.1. Subword Statistics
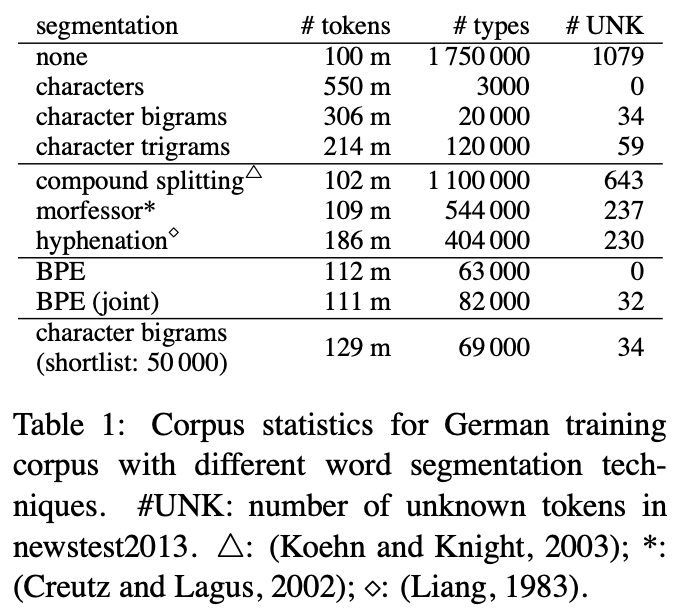
- 평가 항목 : 독일어 데이터 segmentation
- 평가 기준 : 적은 token으로 많은 vocab을 커버하는가 (sequence length: tokens, vocab size: types)
- 평가 결과 :
- BPE 모델은 UNK가 안생김.
- joint BPE에 UNK가 있는 이유는 UNK 단어들이 영어에만 있는 단어이기 때문이다.
4.2. Translation Experiments
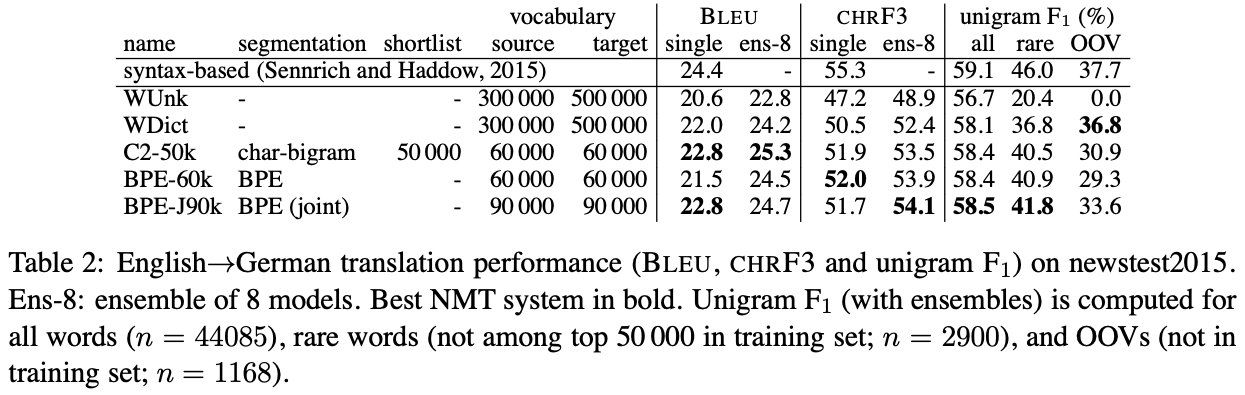
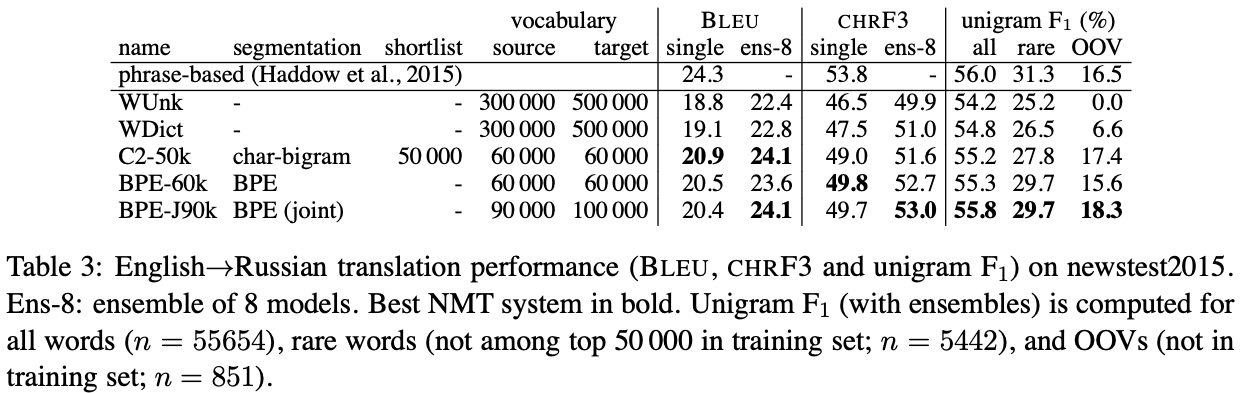
- 평가 항목 : English -> German translation (Tab 3), English-> Russian (Tab 3)
- 평가 기준 : rare, oov 잘 translation 했는가?
- 평가 결과 :
- * 맨 위에 써있는 syntax-based 모델은 non-neural model임
- Back-off dictionary의 효과 (Word level model)
- WDict, WUnk (w/o back-off dict)
- back-off dict 있는 게 rare & unseen data에서 unigram f1 score 더 높음.
- but, back-off dict은 transliterating name들 커버치지 못했음.
- Subword model
- rare: baseline (WDict)보다 다 잘맞춤.
- OOV: 같은 알파벳을 쓰는 En->GE에서는 baseline이 커버를 잘하는데, 다른 알파벳을 쓰는 En->RU 에서는 subword 모델의 성능이 더 나았음.
- joint BPE가 그냥 BPE보다 나았음.
- Translation Performance
- 베이스라인보다 성능이 좋았으나 차이가 크지 않다.
- rare 단어들이 문장의 핵심 정보인 경우가 많아서 rare & unseen에 강경한 subword 모델의 performance가 더 높았어야 한다고 생각한다. 하지만, UNK 단어들은 전체 단어의 9-11퍼센트 밖에 차지하지 않기 때문에 BLEU와 CHRF3이 이를 과소평가해서 translation quality가 기대만큼 높게 나오지 않았다.
- 베이스라인보다 성능이 좋았으나 차이가 크지 않다.
5. Analysis
5.1. Unigram Accuracy
- result 결과와 같은 말이라서 skip
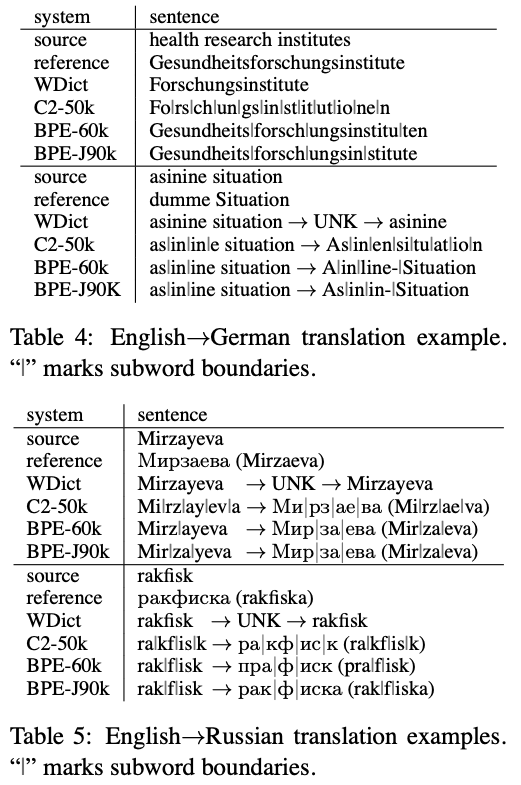
5.2. Manual Analysis
- result 결과와 같은 말이라서 skip
6. Conclusion
-
Summary
- Task : NMT에서의 Open-vocabulary problem
- Approach : Byte pair encoding 기법을 이용한 Subword units
- Results : rare & OOV에서 성능 좋다.
- review 전 나의 의문!
- Fast text의 subword (a bag of character n-grams)랑은 다른 개념인가?
- BPE는 NN에서만 쓸 수 있나?
- review 후 나의 해답!
- fast text의 subword는 의미론을 생각하지 않고 그냥 character를 fixed-length로 segmentation한다(ex. happy -> ha, ap, pp, py). BPE는 subword도 interpretable하다!
- 쓰기 나름! tokenize 방식일 뿐이니까 word2vec같은 Unsupervised방식 차용해서 훈련해서 pretrained vector만들어 놔도 되고, NN에서 쓰면 pretrained도 만들 수 있고, 고정된 vocab으로 fine-tuning해도 되고!
-
BPE 다음 연구는 뭐가 있을까?
- GPT3 : BPE
- BERT : WordPiece
- SentencePiece: https://github.com/google/sentencepiece)
- WordPiece 와 SentencePiece의 다른 점은?
Reference
