인덱스란
- 데이터 파일에대한 접근 경로(Access Path)라고 불림
- <필드값, 레코드에 대한 주소> 로 구성된 엔트리를 저장한 파일
- 실제 데이터보다 크기가 훨씬 작기 때문에 인덱스 파일은 데이터 파일보다 훨씬 적은 디스크 블록을 차지함
- 인덱스에 대한 이진탐색으로 데이터 파일의 해당 레코드에 대한 주소를 얻을 수 있음.
추가적인 쓰기작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조. 책의 색인과 비슷한 개념이라고 생각하면 된다.
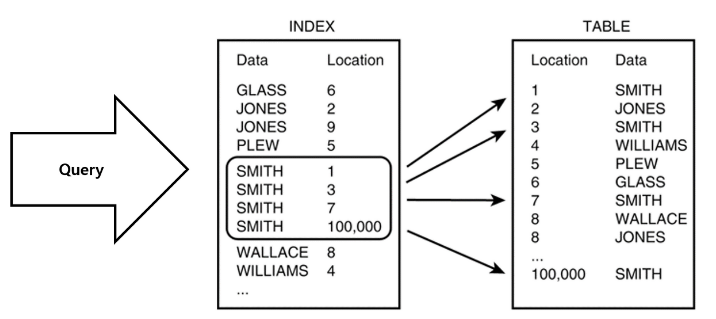
인덱스는 {Data(Key): Location(Value)} 형태의 자료구조이다.
인덱스가 가지고 있는 키로 먼저 데이터를 찾고 Key의 Value인 테이블 내 데이터 실제 위치를 받아와서 데이터를 조회한다.
장단점
- 장점
- 테이블 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
- 단점
- 인덱스를 관리하기 위해 DB의 약 10% 에 해당하는 저장공간이 필요하다.
- 인덱스를 관리하기 위한 추가 작업 리소스
- 수정/삽입/삭제가 빈번한 속성에 인덱스를 걸면 인덱스의 크기가 비대해져서 오히려 성능이 저하될 수 있음.
- INSERT: 새로운 데이터에 대한 인덱스를 추가함
- DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 수행함.
- UPDATE: 수정하고자 하는 데이터에 기존의 인덱스를 사용하지 않음 처리하고 새로운 인덱스를 추가
-> UPDATE, DELTE 연산은 해당 인덱스를 삭제하지 않고 사용하지 않음 처리함으로써 완전히 삭제하지 않기 때문에 사이즈가 점점 커짐
인덱스를 사용하면 좋은 경우
- CRUD가 빈번하지 않은 테이블
- 카디널리티가 높은 테이블(데이터 중복도가 낮은 테이블)
- JOING, WHERE, ORDER BY 연산이 자주 발생하는 테이블
인덱스 종류
단일 단계 인덱스
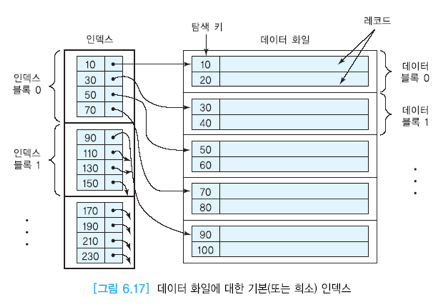
기본 인덱스
- 순서 파일에 대해 정의할 수 있는 인덱스
- 데이터 파일은 탐색 Key 값 순으로 정렬되어 있어야 함
- 데이터 파일의 각 블록에 대해 하나의 엔트리를 가지며
Block Anchor라 불리는 각 블록 첫 번째 레코드에 대한 필드 값을 엔트리로 가짐. - 일부 키 값만 엔트리로 갖고 있는
희소인덱스에 해당
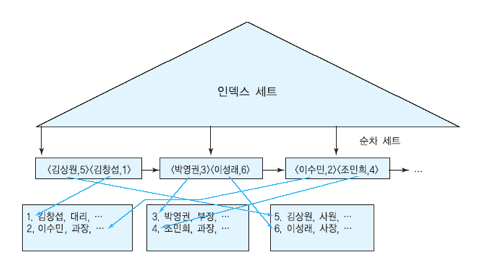
클러스터링 인덱스
- 순서 파일에 대해 정의할 수 있는 인덱스
- 데이터 파일은 각 레코드에 대해
구별된 값을 갖지 않는 필드(Non-Key Field)에 따라 정렬됨 - 인덱스 엔트리에는 그 필드 값을 가진 레코드들이 저장된 첫 번째 블록에 대한 주소를 갖고 있음.
희소인덱스
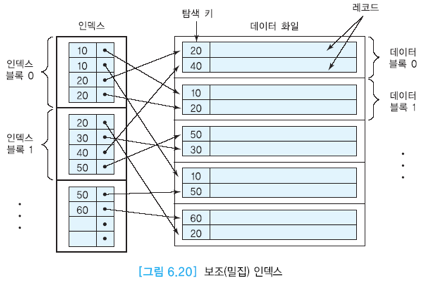
보조인덱스
- 정렬되지 않는 파일에 대해 정의할 수 있는 인덱스
- 후보키나 모든 레코드에 대해 유일값을 갖는 필드 or 중복된 값을 갖지 않는 필드에 대해 만들 수 있음
- 두 개의 필드로 구성된 순서 파일(1. 데이터 타입, 2. 블록포인터 or 레코드포인터)
- 같은 파일에 인덱스 여러 개 존재 가능
- 모든 데이터 파일의 레코드에 대한 엔트리를 가지므로
밀집 인덱스
다단계 인덱스
인덱스 자체가 크다면 인덱스를 탐색하는 시간도 오래걸림
단일단계인덱스를 디스크 상 하나의 순서 파일로 간주하고 단일 단계 인덱스에 대해 다시 인덱스를 정의
가장 상위 인덱스에 모든 인덱스 엔트리들이 한 블록에 들어갈 수 있을 떄까지 반복함
참고

새로운 기술을 테스트하고 적용해보는 걸 좋아하는 서버 개발자