실행계획
실행계획이란 DB 엔진이 쿼리를 실행하는데 결정한 가장 효율적인 출력물
쿼리 처리 과정
구문분석 -> 표준화 -> 최적화 -> 컴파일 -> 실행
실행계획은 최적화 단계에서 통계, 조각 정보 등을 바탕으로 만들어지고 이때 만들어지는 플랜을 재사용하기 위해 플랜을 캐시한다.
-> 예상 실행계획 / 실제 실행계획으로 분리됨
예상/실제실행계획
-
예상실행계획: 이전에 생성된 통계정보를 바탕으로 플랜 구성 -
실제실행계획: 현재 상태의 통계정보를 바탕으로 플랜 구성 -
새로운 실행계획을 생성하는 케이스
- 쿼리에서 참조하는 테이블이나 뷰가 변경된 경우 / 쿼리 실행 프로시저가 변경된 경우(ALTER)
sp_recompile명시적으로 호출- 실행계획에 사용하는 인덱스가 변경된 경우
- 실행계획에 사용되는 통계가 업데이트된 경우(ex.
UPDATE STATISTICS) - 쿼리에서 참조하는 테이블을 수정하는 다른 사용자가
INSERT / DELETE로 키를 많이 변경한 경우 - 트리거가 있는 테이블의 경우
inserted/deleted테이블 행수가 현저하게 증가하는 경우 WITH RECOMPILE옵션을 사용하여 저장 프로시저를 실행하는 경우- 계획에 있는 모든 캐시를 삭제한 경우 (ex.
DBCC FREEPROCCACHE)
실행계획 속성
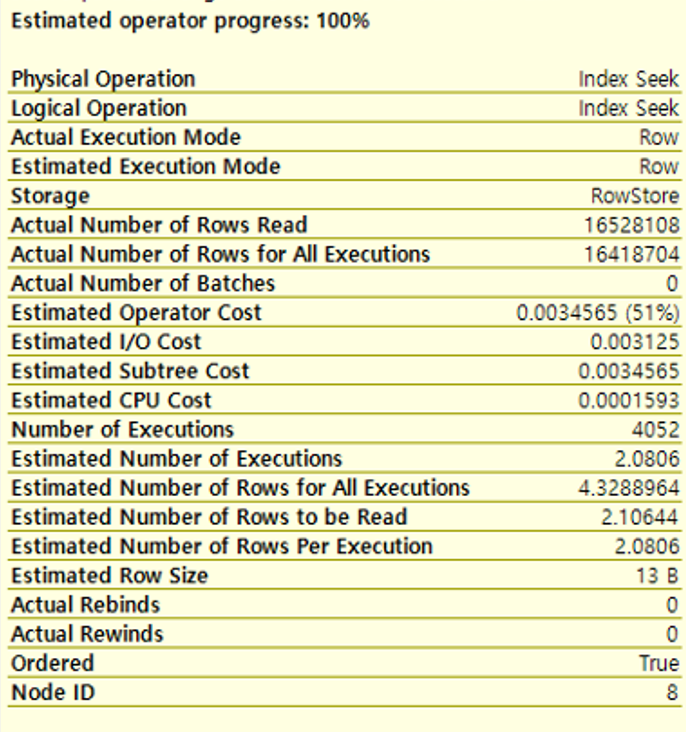
속성 설명 Physical Operation 논리 연산자의 지시에 따라 연산을 구현하는 연산자. ex) Clustered Index Scan Logical Operation 쿼리를 처리하는 데 사용되는 실제 대수 연산 ex) Right Anti Semi Join Storage 쿼리 최적화 프로그램이 쿼리에 의해 추출되는 결과를 저장하는 방법 Estimated I/O Cost 결과 집합의 입/출력 작업 비용 Estimated CPU Cost 작업을 처리하기 위해 CPU에서 발생하는 비용 Number of Executions 특정 쿼리나 저장 프로시저가 실행된 횟수. 쿼리 플랜캐시에 저장되며 성능 튜닝 및 문제 해결 목적으로 유용할 수 있음. Estimated Number of Rows Per Execution 연산자에 의해 반환될 것이라고 추정하는 행 수 Estimated Number of Rows to be Read 운영자가 읽을 것이라고 추정하는 행 수 Estimated Row Size 연산자의 각 행에 대한 저장 크기 Ordered 작업을 수행할 데이터 세트가 정렬된 상태인지 여부 Node ID 오퍼레이터가 호출된 순서대로 번호 자동할당됨. 우 -> 좌 / 상 -> 하
SQL Server 실행계획 연산자
테이블 스캔 (Table Scan)
연산자가 모든 전체 테이블 행을 스킨한다는 것을 의미
SQL Server 엔진은 WHERE 절을 추가하여 특정 레코드 집합을 가져오려고 하는데
인덱스가 없다면 TABLE SCAN을 함.
인덱스가 있는데도 테이블 스캔을 하는 경우는 아래 참고
- 인덱스가 유용하지 않은 경우(조건절에 없음)
- 테이블에 적은 수의 행이 포함된 경우
- 쿼리가 대부분의 행을 반환하는 경우
클러스터형 인덱스 스캔(Clusterd Index Scan)
모든 인덱스 행을 순회한다는 것을 의미
오래된 통계로 인해 비클러스터형 인덱스가 없거나 쿼리가 테이블의 행의 대부분을 반환하는 경우 SQL Server 엔진은 클러스터형 인덱스 스캔을 선택한다.
클러스터형 인덱스 검색(Clustered Index Seek)
모든 테이블 행을 순회하는 대신 적절한 클러스터형 인덱스를 찾고 이를 탐색하여 SQL Server 저장소 엔진에 선택한 행의 키 값을 기반으로 필요한 행을 검색한다.
비클러스터형 인덱스 검색(NonClustered Index Seek)
인덱스 키 값과 나머지 열에 대한 포인터만 저장해 데이터를 검색한다.
참조
-
Number of Executions를 시스템 캐시 테이블에서 조회하기
SELECT
deqs.execution_count
FROM
sys.dm_exec_query_stats deqs
CROSS APPLY
sys.dm_exec_sql_text(deqs.sql_handle) dst
WHERE
dst.text like '%[query text to search for]%';
새로운 기술을 테스트하고 적용해보는 걸 좋아하는 서버 개발자