📍 나이브베이즈
- 나이브베이즈 분류 알고리즘은 데이터를 단순(나이브)하게 독립적인 사건으로 가정하고, 이 독립 사건들을 베이즈 이론에 대입시켜 가장 높은 확률의 레이블로 분류를 실행하는 알고리즘이다.
- 나이브베이즈는 feature끼리 서로 독립이라는 조건이 필요하다.
- 예시로 나이브 베이즈의 작동 방식을 살펴보면, 날씨 정보와 축구 경기 여부에 대한 데이터가 있다고 치자. 과거에 날씨에 따라 축구를 했는지 안했는지에 대한 데이터로 먼저 학습을 시키고, 그 모델을 기반으로 어떤 날씨가 주어졌을 때 축구를 할지 안 할지 판단하는 것이다.
📍 베이즈 이론
베이즈 정리는 나이브 베이즈 분류기의 근본이 되는 수학정리다.
두 사건 A,B에 대한 조건부 확률 간에 성립하는 확률관계로 수식은 다음과 같이 표현할 수 있다.
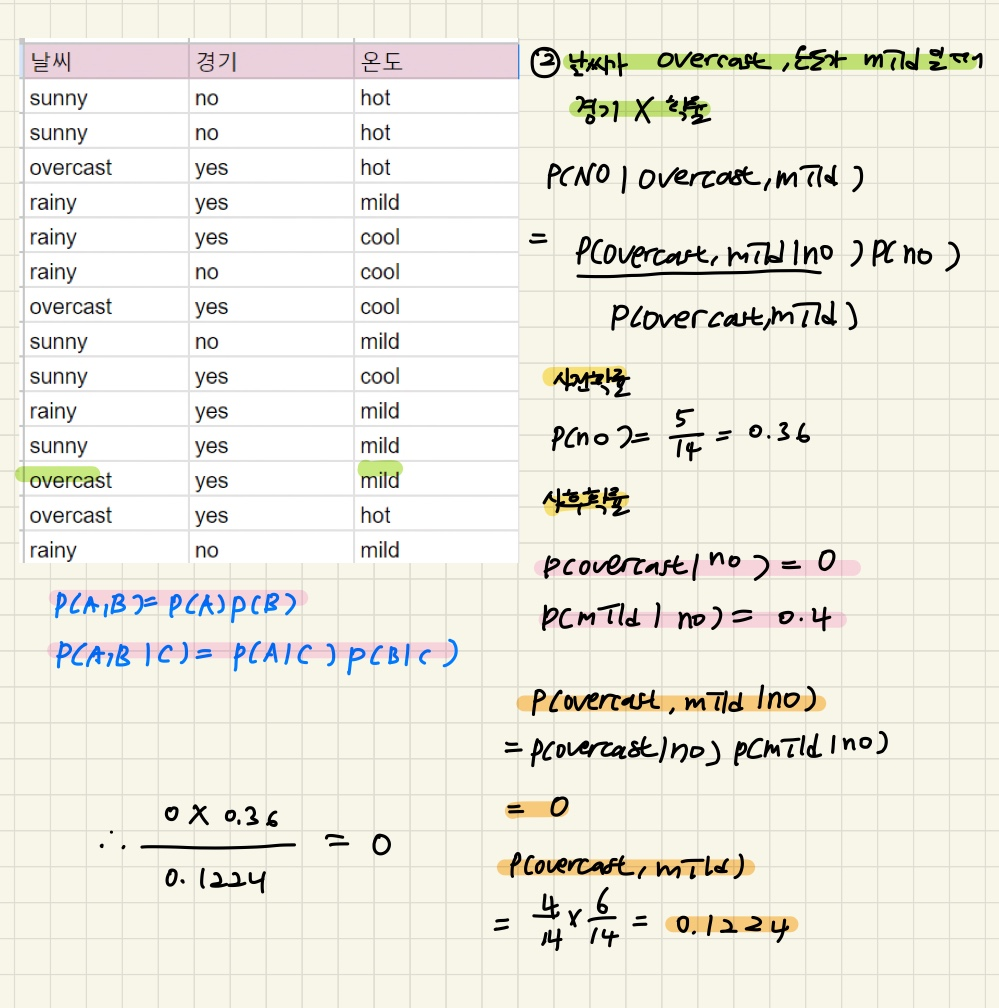
1) 사후확률 P(X|Y) : 사건 발생 후의 확률로, 발생한 사건(X)이 특정 확률분포(Y)에서 나왔을 확률,관측된 특징(X)이 특정 클래스(Y)에서 나왔을 확률
2) 사전확률 P(X) : 특정한 특징이나 사건에 무관하게 미리 알 수 있는 확률, 특징(X)가 관측되기 전부터 이미 정해져있던 클래스(Y)의 분포
3) 우도 , 가능도(likelihood) P(Y|X) : 사후확률과 반대로, 특정 확률분포 또는 클래스(Y)에서 특정 사건이나 특징(X)이 발생할 확률. 기존에 있는 데이터의 각 클래스 별로 특정 특징에 대한 분포
이론만 봐서 잘 이해가 안되니 예시를 통해서 이해해보자.

위의 예시는 feature가 하나이지만, feature가 여러 개라면??
베이즈 이론을 공부했지만, 막상 데이터에 어떻게 적용하는지는 모를 수 있다. 도대체 어떻게 나이브 베이즈 알고리즘을 머신러닝에 적용할까?
👇 👇 👇 👇 👇 👇 👇
이 수식을 풀어서 말하자면, 어떤 데이터가 있을 때 그에 해당하는 레이블은 기존 데이터의 특징 및 레이블의 확률을 사용해 구할 수 있다는 것 !
✔ 다항분포 나이브 베이즈 분류 (이산)
데이터의 특징이 출현 횟수로 표현됐을 때 사용한다.
ex1) 주사위를 10번 던졌을 때 1이 1번, 2가 2번, 3이 3번, 4가 4번 나왔을 때 (1,2,3,4,0,0)과 같이 나올 때
ex2) 영화 감상평이 긍정/ 부정 리뷰로 나뉠 때
✔ 베르누이 나이브 베이즈 분류 (이산)
데이터의 출현 여부에 따라 1 또는 0으로 구분됐을 때 베루누이 나이브 베이즈 모델을 사용한다.
ex) 스팸 메일 분류
❓ 만약 데이터의 특징들이 이산적이지 않고, 연속적일 경우에는 ?
가우시안 나이브베이즈 분류를 사용하는 것을 추천!
✔ 가우시안 나이브베이즈 분류 (연속)
특징들의 값들이 정규분포 되어 있다는 가정하에 조건부 확률을 계산해, 연속적인 성질이 있는 특징이 있는 데이터를 분류하는데 적합하다.
각각 사이킷런에서 GaussianNB: 정규분포 나이브베이즈 / BernoulliNB: 베르누이분포 나이브베이즈 / MultinomialNB: 다항분포 나이브베이즈 모형 클래스를 제공한다.
📍 스무딩
학습 데이터에 없던 데이터가 출현해도 빈도수에 +1 을 해서 확률이 0이 되는 현상을 방지하는 것이다.
ex) 나이브 베이즈 기반 스팸 메일 필터를 했을 때, 학습 데이터에 없던 단어가 나타나면 확률이 0이 되어서 스팸 분류가 어려워진다. 0이라는 수는 곱하기, 나누기에서 무력화를 시켜버린다. 이런 문제를 극복하기 위해서 스무딩을 사용한다.
✔ 나이브 베이즈 장단점
장점
1) 간단하고, 정확하다.
2) 계산 속도가 빠르다.
단점
1) feature 간의 독립성이 있어야한다!
💻 나이브 베이즈 실습 (가우시안)
붓꽃 분류
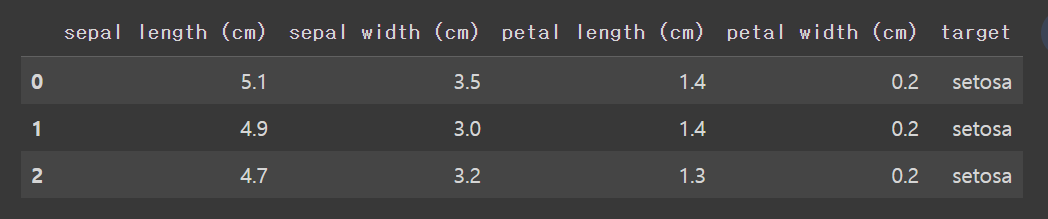
왼쪽에서 오른쪽으로 변수 설명
👉 꽃밤침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비, target = setosa, versicolor, virginica
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
from sklearn.metrics import accuracy_score
data = load_iris()
df = pd.DataFrame(data.data, columns = data.feature_names)
df['target'] = data.target
df.target = df.target.map({0:'setosa',1:'versicolor',2:'virginica'})
df.head(3)
#붓꽃 종류에 따라 데이터프레임을 나눔
setosa_df = df[df.target =='setosa']
versicolor_df = df[df.target =='versicolor']
virginica_df = df[df.target == 'virginica']
ax = setosa_df['sepal length (cm)'].plot(kind='hist')
setosa_df['sepal length (cm)'].plot(kind='kde',ax=ax,
secondary_y = True,
title = 'setosa sepal length',
figsize = (6,4))
ax = versicolor_df['sepal length (cm)'].plot(kind='hist')
#kde = 커널 밀도 추정 (히스토그램 같은 분포를 부드럽게 곡선화 시켜서 그려주는 것)
versicolor_df['sepal length (cm)'].plot(kind='kde',ax=ax,
secondary_y = True,
title = 'vericolor sepal length',
figsize = (6,4))
ax = virginica_df['sepal length (cm)'].plot(kind='hist')
virginica_df['sepal length (cm)'].plot(kind='kde',ax=ax,
secondary_y = True,
title = 'virginica sepal length',
figsize = (6,4))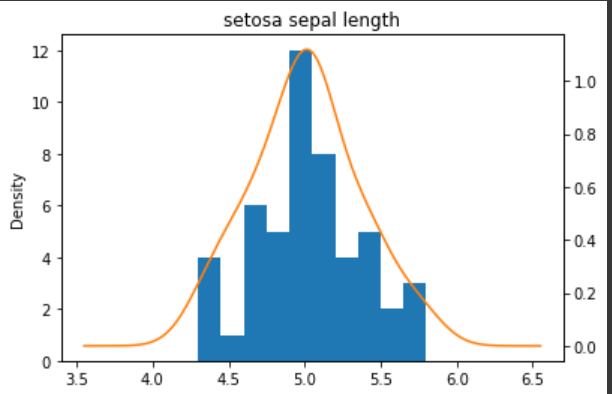
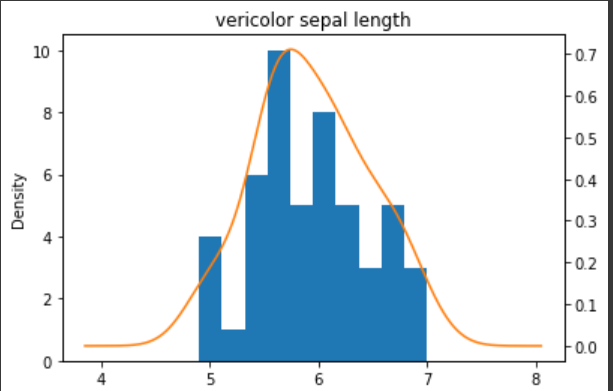
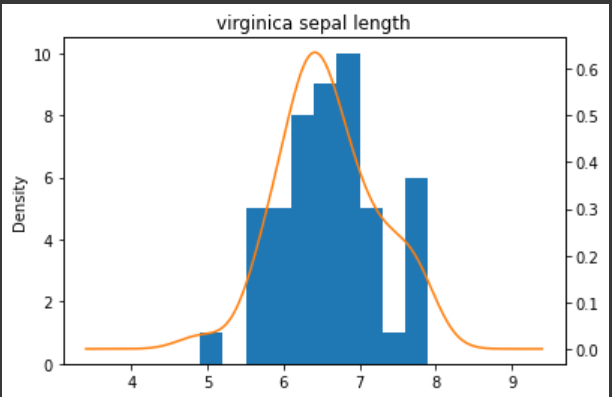
가우시안 나이브 베이즈 분류에 맞게 정규분포(가우시안 분포)를 따르는 것을 볼 수 있다.
X_train, X_test, y_train,y_test = train_test_split(data.data, data.target, test_size = 0.25)
model = GaussianNB()
model.fit(X_train,y_train)
pred = model.predict(X_test)
print(metrics.classification_report(y_test,pred))
print('정확도:' , accuracy_score(y_test,pred))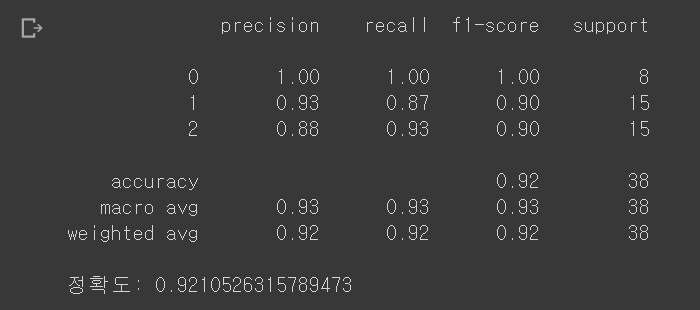
💻 나이브 베이즈 실습 (베르누이)
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score
email_list = [
{'title': 'lotto only today', 'spam':True},
{'title':'cheapest flight deal','spam':True},
{'title':'limited time offer only today only today','spam':True},
{'title':'today meeting schedule','spam':False},
{'title':'your fight schedule attached','spam':False},
{'title':'your credit card statement','spam':False}
]
df = pd.DataFrame(email_list)
df['target'] = df['spam'].map({True:1,False:0})
df_x = df['title']
df_y = df['target']
cv = CountVectorizer(binary=True) #binary = True 특정단어가 출현하면 1, 하지 않으면 0
x_traincv = cv.fit_transform(df_x)
#이메일 제목 벡터 인코딩 확인
encoded_input = x_traincv.toarray()
encoded_input 총 17개 단어 발견!
총 17개 단어 발견!
bnb = BernoulliNB()
y_train = df_y.astype('int')
bnb.fit(x_traincv,y_train)
test_email_list = [
{'title': 'free lotto offer', 'spam':True},
{'title':'hey travel free flight deal','spam':True},
{'title':'limited time free game offer','spam':True},
{'title':'today meeting about today','spam':False},
{'title':'your credit card attached','spam':False},
{'title':'free credit card offer only','spam':False}]
test_df = pd.DataFrame(test_email_list)
test_df['target']= test_df['spam'].map({True:1,False:0})
test_x = test_df['title']
test_y = test_df['target']
x_testcv = cv.transform(test_x)
pred = bnb.predict(x_testcv)
accuracy_score(test_y,pred)
