📍 K-NN (K-Nearest Neighbor)
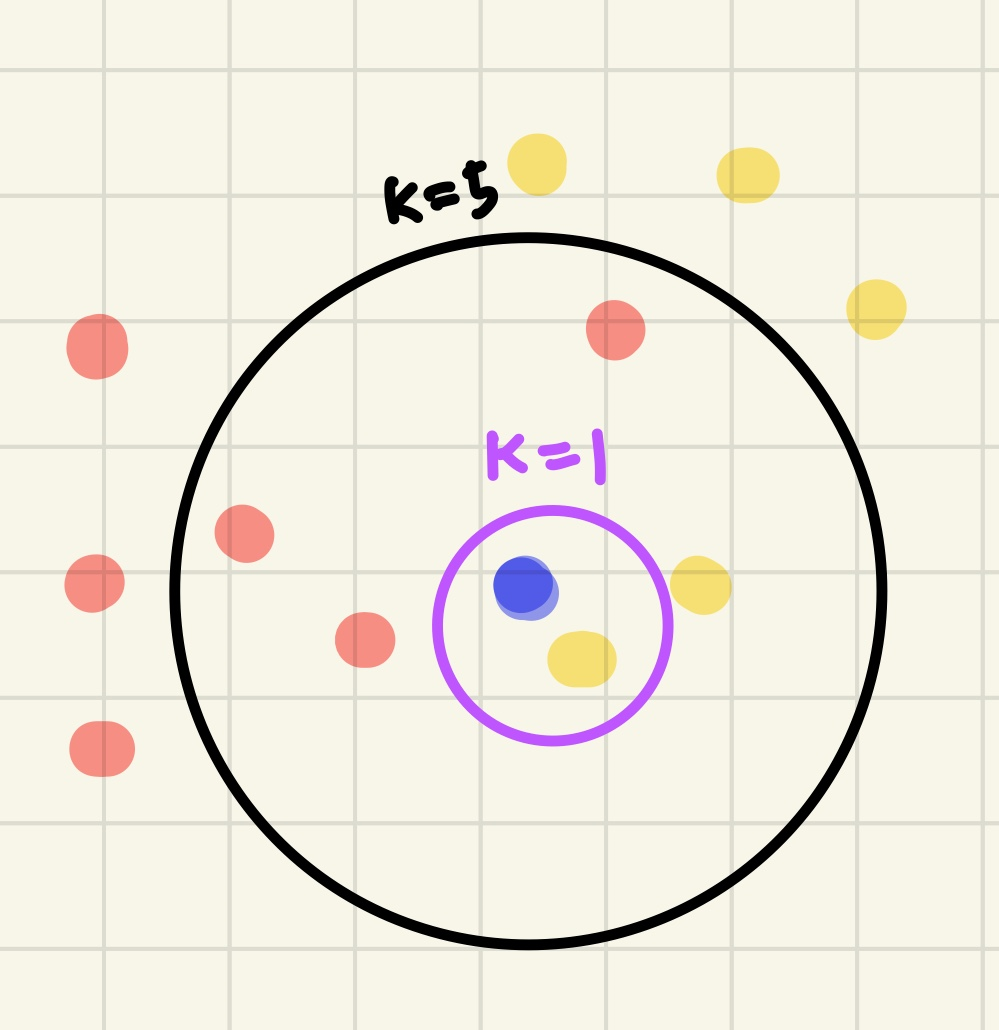
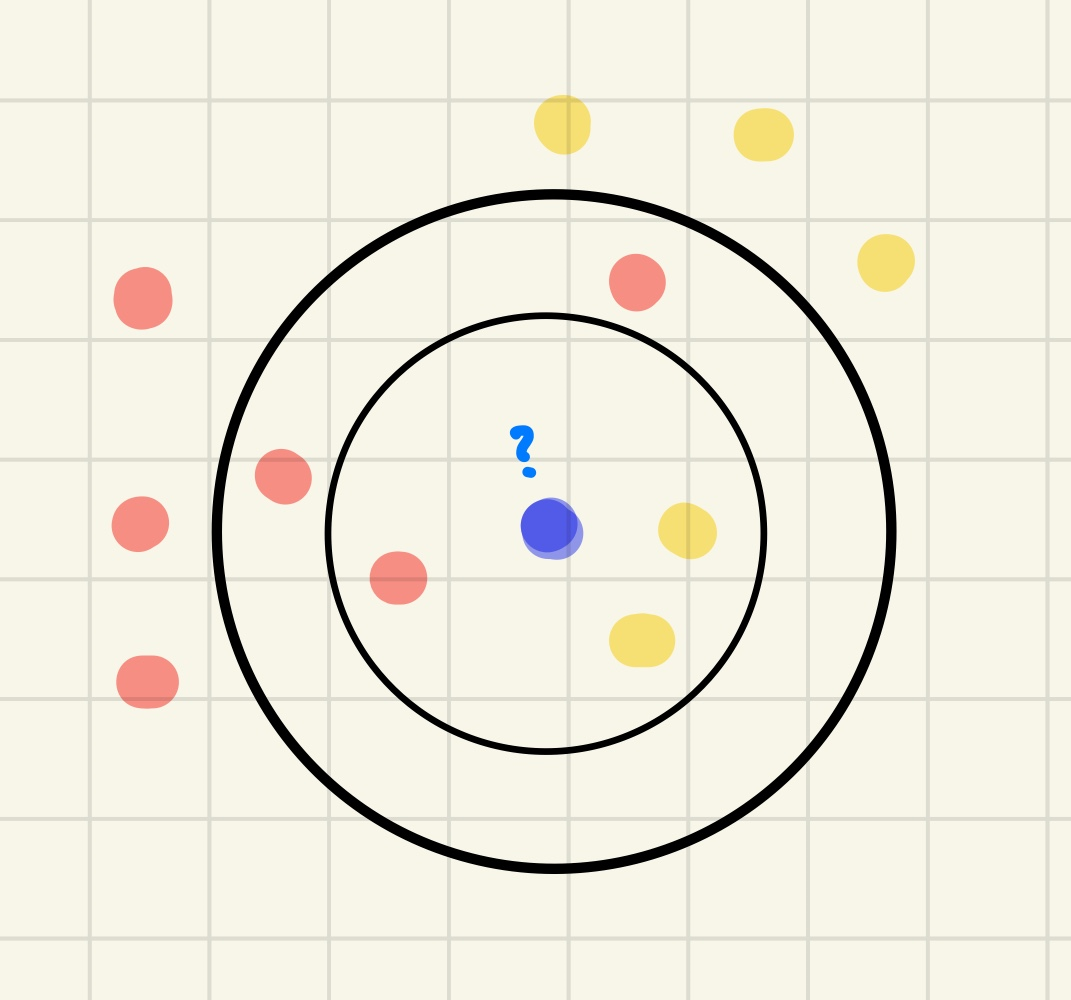
위의 그림과 같이 사용자가 지정한 K에 따라 검증표본인 파란색 동그라미가 분류되는 집단이 달라진다.
- 거리기반의 분류 알고리즘으로, 주변의 가장 가까운 k개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이다.
✔ 비지도 학습의 Clustering 역시 거리기반의 분류 알고리즘인데?
k-nn은 clustering과 달리 기존 관측값(y값)이 존재한다는 점이 차이점이다.
📍 특징
- 거리를 측정할 때 유클리드 거리와 맨해튼 거리를 사용한다.
✔ 유클리드 거리란?
피.타.고.라.스 떠올리면 된다!!
x(1,2) y(5,5) 두 점 사이의 거리는?
맨하튼 거리란?
x(1,2) y(5,5) 두 점 사이의 거리는?
- k의 값에 따라 데이터를 다르게 예측할 수 있다.
- k-nn과 같이 거리 기반의 모델인 경우, 모델 구현 시 '표준화'를 해야할 필요가 있음
- 다중분류는 여러 개의 가능한 레이블 중 하나로 분류한다. KNN은 이러한 다중 분류에도 성능이 우수하다.
- knn은 훈련이 따로 필요 없는 모델 !
- 새로운 데이터가 주어지면 그때서야 주변의 k개 데이터를 보고 새로운 데이터를 분류해준다. 따라서 사전 모델링이 필요 없다! 모델을 별도로 구축하지 않는다는 뜻으로 게으른 모델(lazy model)이라고 부른다.
📍 정규화 및 표준화
정규화가 필요한 이유?
예를들어, 평균이 10,000정도, 소수점이 특성(feature)인 것을 생각해보자. 똑같은 기준으로 고려해서 반영하면 당연히 평균이 10,000인 특성들이 압도적으로 반영되기 때문에 터무니 없는 결론이 나올 수 있다.
- 최소-최대 정규화 (Min-Max normalization)
쉽게 말해 최소값을 0, 최대값을 1로 하여, 모든 값들을 0-1 사이의 값으로 변환하는 방법이다.
- z-점수 표준화 (z-score standardiza
tion)
평균과 표준편차를 활용해 평균으로부터 얼마나 떨어져 있는지 Z-점수로 변환하는 방법이다.
(변수 X 범위를 평균의 위 또는 아래로 몇 표준 편차만큼 떨어져 있는지 관점으로 변수를 확대/축소하는 방식이다.)
최소-최대 정규화 VS Z-점수 표준화
1개월 간 매출액이라는 변수를 이용한다고 할 때, 훈련 데이터 셋의 최대값이 500만원인데, 예측할 미래의 데이터에는 500만원 이상인 값이 충분히 있을 수 있다. 그렇기 때문에 실무에서 보통 z-점수 표준화를 더 사용하기도 한다.
만약 1개월 간 구매일수라는 변수를 이용한다고 하면 최소(0일) 최대(30일)이 정해져 있기 때문에 이러한 경우에는 최소-최대 정규화를 사용해도 문제가 발생하지 않는다.
📍 장단점
장점
1) 비교적 단순한 알고리즘으로 구현하기 쉽다.
2) 훈련 데이터를 그대로 가지고 있기 때문에, 훈련 속도가 매우 빠르다.
단점
1) 모델을 생성하지 않기 때문에 특징과 클래스 간 관계를 이해하는 데 제한적이다.
(모델의 결과를 통해 해석하지 않고, 미리 변수와 클래스 간 관계를 파악해 이를 알고리즘에 적용해야 원하는 결과를 얻을 수 있기 때문)
📍 최적의 K
KNN에서의 관건은 최적의 K를 찾는 것이다.
❓ K가 너무 작으면? 과대적합!
(모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화가 어려움)
- K가 너무 작으면 분류 정확도가 아주 낮다. 근처의 점 하나에 민감하게 영향을 받기 때문에 과적합이 일어나게 된다.
❓ K가 너무 크면? 과소적합!
(모델이 너무 단순해서 데이터의 내재적인 구조를 학습하지 못할 때 발생)
- K가 너무 크면 분류기가 학습 세트의 세세한 부분에 충분히 주의를 기울이지 않았기 때문에 과소적합이 발생되게 된다.
- 만약 학습 세트의 점이 10개인데, K 역시 10개라면?
모든 점이 동일한 방식으로 분류되게 되고, 각 거리도 의미가 사라진다.
📌 Cross-Validation을 이용한 최적의 K 도출
knn에서는 교차검증을 통해서 오분류율이 낮은 k를 선정한다.
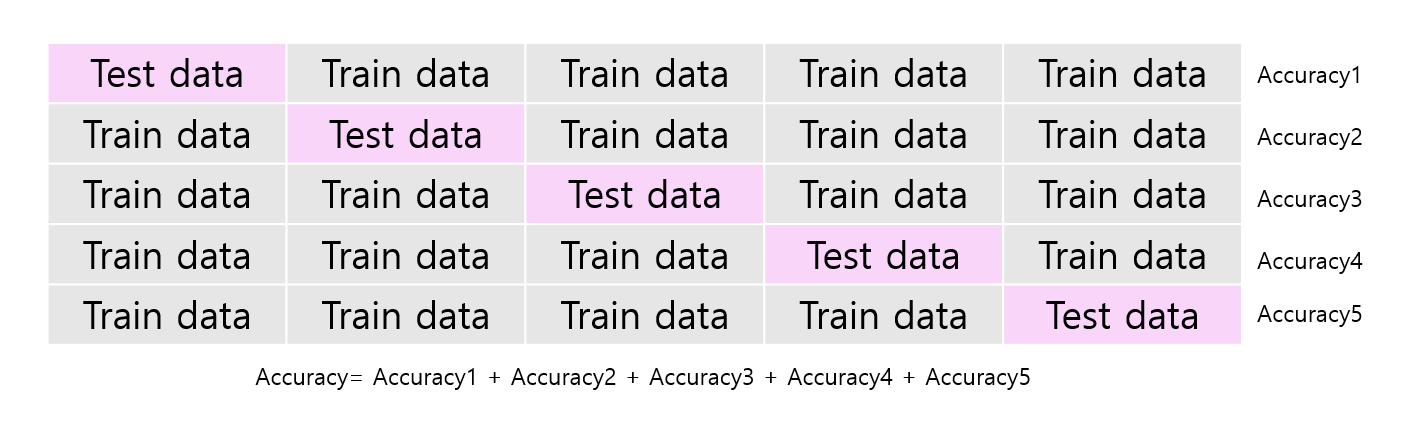
k-Fold 교차검증
- 전체 데이터셋을 k개의 fold로 나누어서 k번 다른 fold 1개를 test data로, 나머지 k-1개의 fold를 train data로 분할하는 과정을 반복함으로써 train 및 test data를 교차 변경하는 것이다.
- 모든 데이터를 train 및 test에 활용하게 되는 것이다.
k = 5 / train: test = 8:2
위의 비율로 전체 데이터셋이 train, test에 사용되도록 교차로 변경 된다.
💻 실습
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns = data.feature_names)
df['target'] = data.target
df.head(3)
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2,random_state=100)
model = KNeighborsClassifier(n_neighbors = 5, weights = 'distance') #가중치 함수
model.fit(X_train,y_train)n_neighbors = k (이웃의 수)
weights = 가중치 함수(default = 'uniform')
- 'uniform' : 균일 가중치로, 각 이웃의 모든 지점은 동일하게 가중치를 부여하는 것
- 'distance' : 거리역수로, 더 가까운 이웃이 멀리 있는 이웃보다 더 영향을 많이주는 것
from sklearn.metrics import roc_curve, auc
pred = model.predict(X_test)
#roc 곡선을 그리기 위해서 fpr, tpr을 구함
fpr, tpr, thresholds = roc_curve(y_test, pred)
AUC = auc(fpr,tpr)
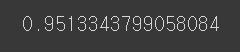
print(AUC)
#fpr = false positive rate 실제로 아닌데 맞다고 '잘못' 판단
#tpr = true positive rate 실제로 맞는데, 맞다고 판단
#threshold = 분류기준
ex) threshold = 1 , 1 을 기준으로 1 이상이면 예측(분류)헌다.