📍 서포트 벡터 머신 (SVM)
현재 이곳의 위치가 경남인가요? 경북인가요?라고 질문했을 때 남쪽이면 경남이라고 대답할 것이고, 북쪽이면 경북이라고 대답할 것이다. 이와 같이 내게 예측을 요구한 사람에게 이렇게 질문해서 위치를 예측하는 것! 여기서 경남인지, 경북인지 구분하는 것이 결정 경계선이라 하는 것이다.
기본적으로 서포트 벡터 머신은 분류, 회귀에 모두 사용할 수 있는 매우 강력한 모델이다. 그리고 여러 집단들을 가장 잘 구분할 수 있는 최적의 선을 찾는 것이 목표!
여기서 나오는 개념들을 더 구체적으로 알아보자 !
📍 서포트 벡터
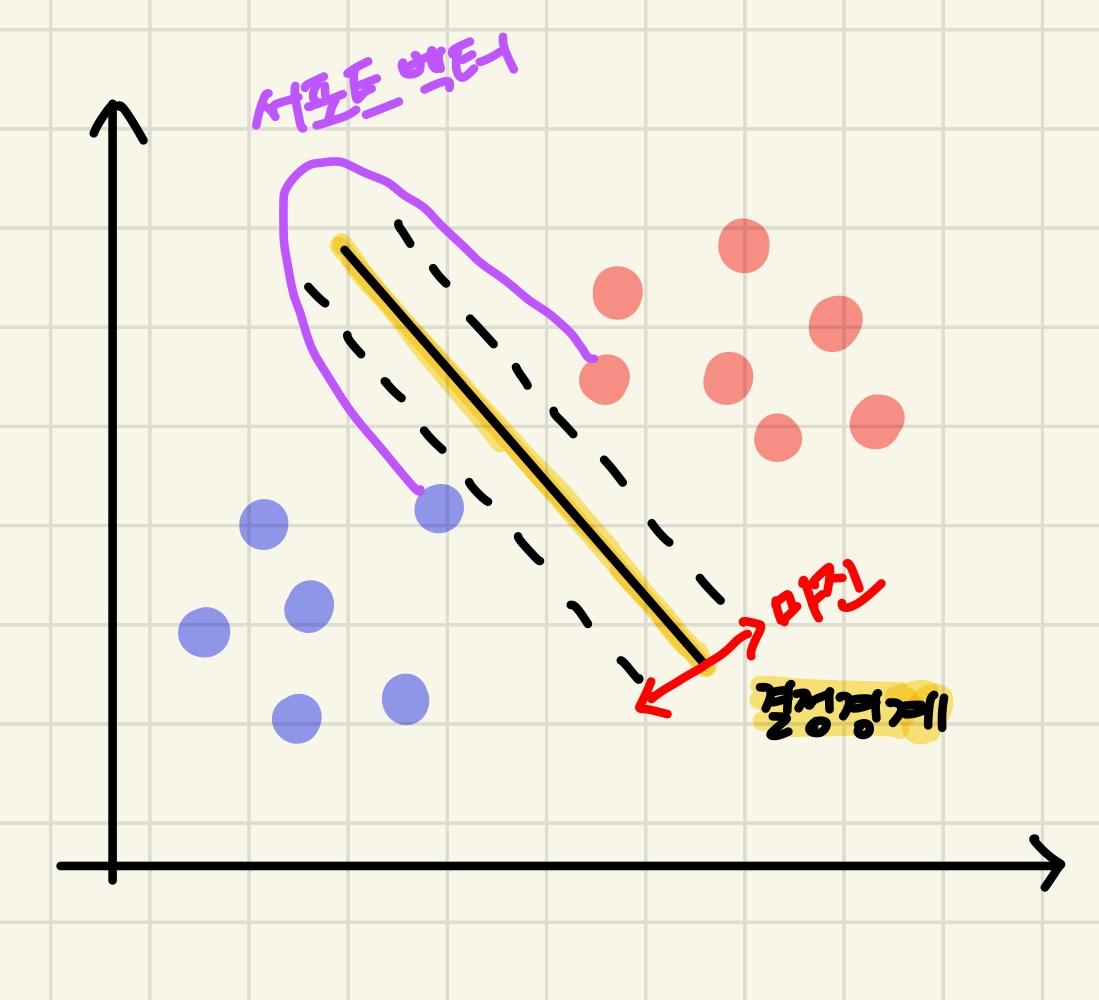
- 결정 경계선과 가장 가까이 맞닿은 데이터 포인트를 의미함
(=결정 경계를 만드는 데 영향을 주는 최전방의 데이터 포인트)
📌 마진
- 서포트 벡터와 결정 경계 사이의 거리
- 서포트 벡터의 목표는?
👉 마진을 최대로 하는 결정 경계를 찾는 것 !!
마진이 클수록 우리가 현재 알지 못하는 새로운 데이터에 대해 안정적으로 분류할 가능성이 높다.
- 서포트 벡터의 목표는?
📌 svm 종류
-
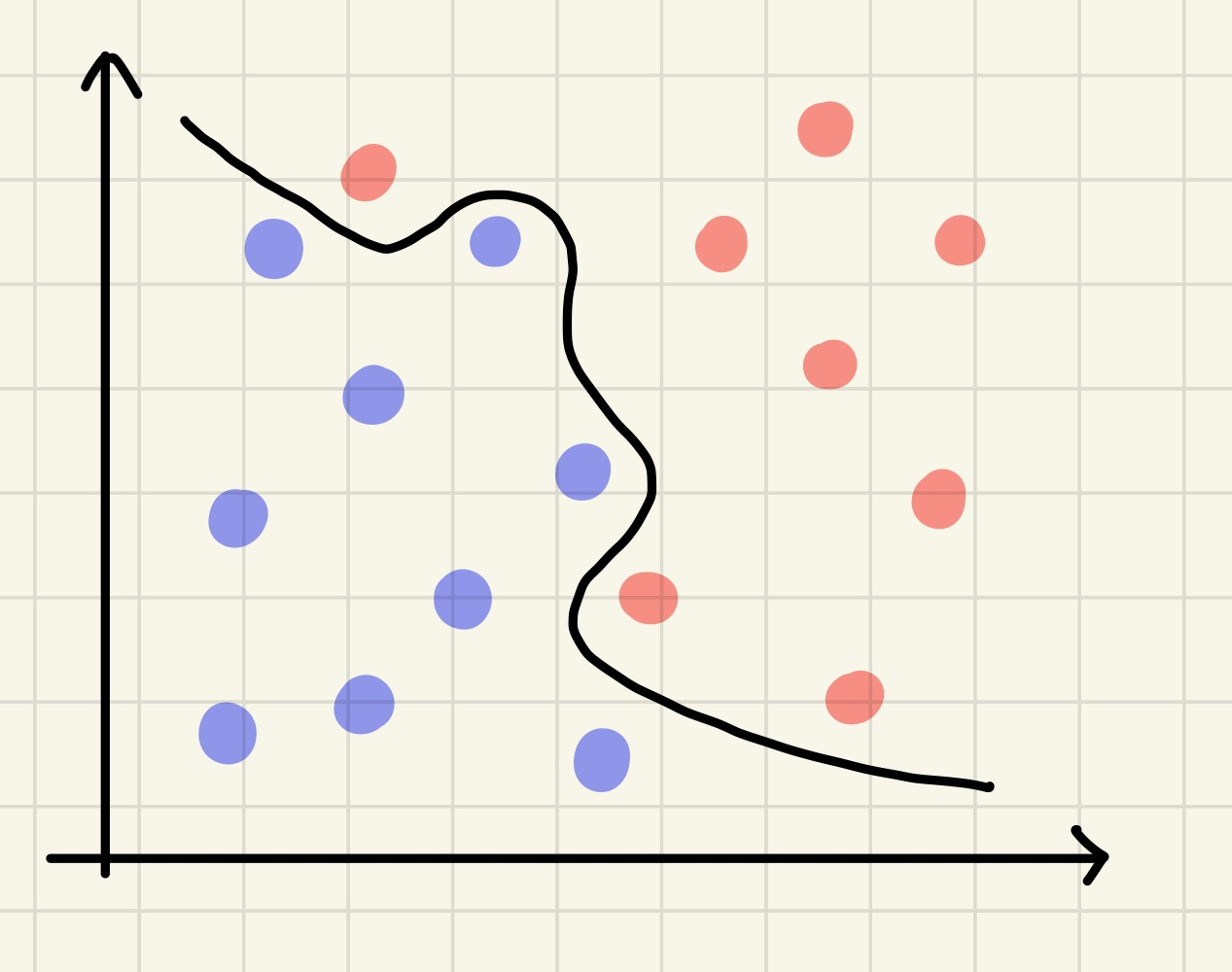
하드마진 svm
이름에서 알 수 있듯이 마진 값을 하드하게/타이트하게 잡기 때문에 이상치를 허용하지 않는다. 이에 따라 과적합이 발생할 가능성이 높고, 노이즈로 인해 최적의 결정 경계를 잘못 구분하거나 못 찾는 경우가 발생할 수 있다.
-
소프트 마진 svm
위와 같은 하드 마진 svm의 특징을 보완해 사용하는 것이 소프트 마진 svm이다. 소프트 마진은 이상치들을 어느정도 허용하면서 결정 결계를 설정한다.
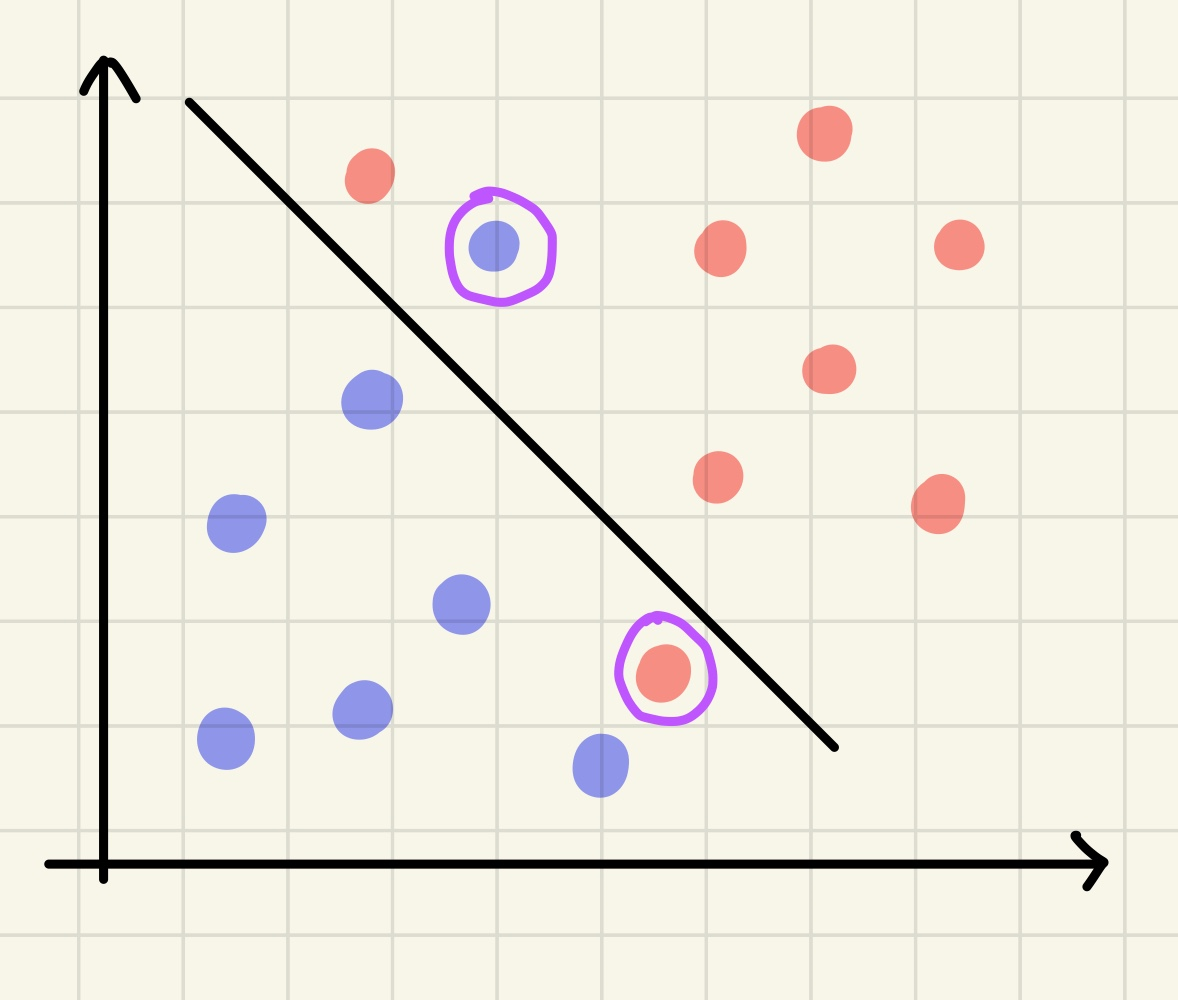
SVM 회귀 문제
회귀 문제로 SVM을 사용하려면 데이터들을 대표할 수 있는 직선을 만드는 것이 목표이다. 그렇기 때문에 데이터들을 아우르는 마진을 잡고 그 중앙에 회귀선을 그어주는 방식으로 작동한다. 마진이 좁을수록 데이터들을 대표할 수 있는 회귀선을 잘 만들 수 있다.
그렇다면?? 👉 하드 마진을 사용하는 것이 좋다!
(분류의 경우에는 두 집단 사이의 거리가 먼, 마진이 큰 것이 좋기 때문에 소프트 마진을 사용하는 것이 좋다고 한다.)
📌 비용
-
약간의 오류를 허용하기 위해 비용(C)이라는 변수를 사용함
-
비용이 낮을수록, 마진을 최대한 높이고, 학습 에러율을 증가시키는 방향으로 결정 경계선을 만듦
-
비용이 높을수록, 마진은 낮아지고, 학습 에러율은 감소하는 방향으로 결정 경계선을 만듦
👉 비용이 너무 낮으면 과소 적합 가능성이, 비용이 또 너무 높으면 과대 적합의 위험성이 있기 때문에 적절한 비용값을 찾는 것이 중요
📌 결정 경계
N = 데이터의 벡터 공간
( 데이터가 3차원 공간에 분포할 경우 결정 경계는 3-1= 2차원이므로, 결정 경계는 면으로 나타남
이러한 이유로 결정경계를 초평면이라고 칭하기도 함)
📌 커널 트릭
- 실제로 데이터를 고차원으로 보내진 않지만 보낸 것과 동일한 효과를 줘서 매우 빠른 속도로 결정 경계선을 찾는 방법
[ 1차원의 결정 경계 찾기 ]
1차원의 결정 경계는 1-1 = 0차원으로 나타나기 때문에 점(노란색 네모) 하나로 세모 집단과 동그라미 집단을 구분해야함!
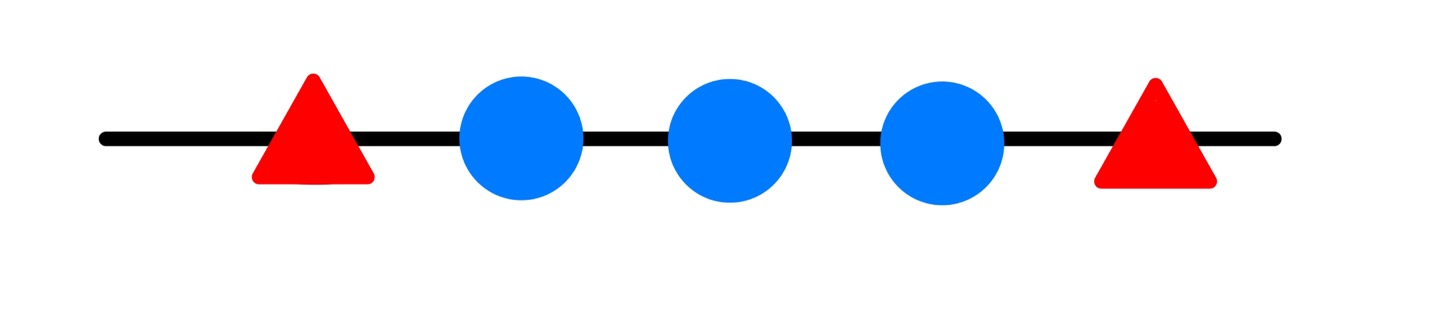
이렇게 데이터의 집단이 있다.
 이 두가지 모두 노란색 네모를 기준으로 나눠진 것을 보면 잘못 분류되어 있는 것을 볼 수 있다.
이 두가지 모두 노란색 네모를 기준으로 나눠진 것을 보면 잘못 분류되어 있는 것을 볼 수 있다.
SVM은 N-1차원의 초평면으로 두 데이터 집단을 구분해야하기 때문에, 주어진 저차원 벡터 공간의 데이터를 고차원 벡터 공간으로 옮겨줌으로써 결정 경계를 찾는 방법을 생각해야 하는 것
그렇다면 위의 X축 위의 점들을 2차원으로 옮겨주면??
(Y = X^2이라는 함수를 통해 1차원 데이터를 2차원으로 옮겨주도록 하자)
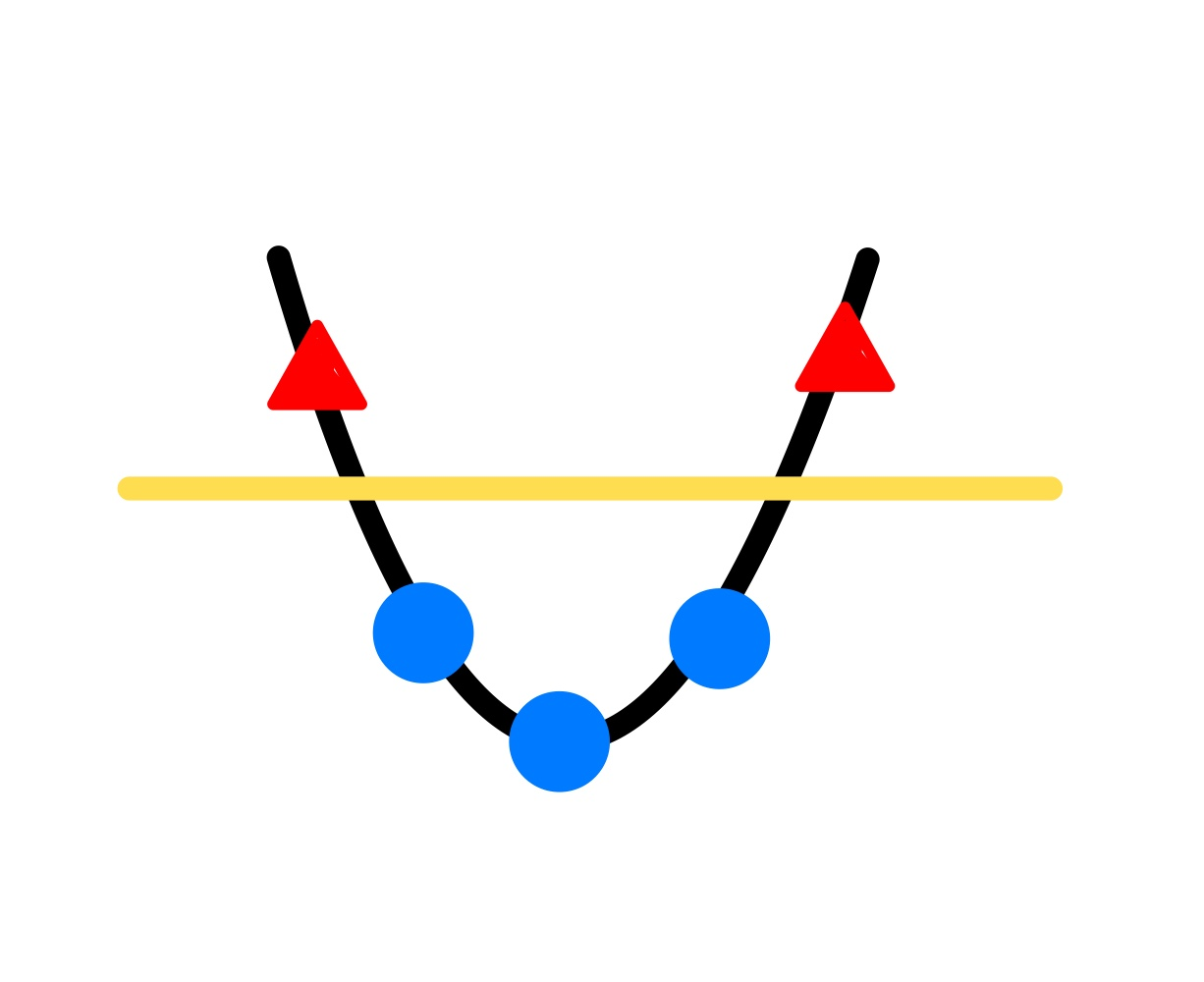 2차원 공간으로 옮겨지니 1차원의 결정 경계선으로 완벽히 분리됨!
2차원 공간으로 옮겨지니 1차원의 결정 경계선으로 완벽히 분리됨!
이렇게 저차원 데이터를 고차원의 데이터로 옮겨주는 함수가 매핑 함수
하지만! 실제로 많은 양의 데이터를 매핑 함수를 통해 옮겨주는 것은 계산량이 너무 많아 현실적으로 사용하기 힘들다..
그렇기 때문에 앞에서 언급한 개념인, 커널 트릭을 사용하면 된다.
다시 말해, 커널트릭은 선형 분리가 주어진 차원에서 불가능할 경우 고차원으로 데이터를 옮기는 효과를 통해 결정 경계를 찾는 것
📌 파라미터 튜닝
svm을 할 때 정확도를 높이기 위해 조절 가능한 파라미터는 비용(cost)과 감마(gamma)이다.
- 비용: 마진 너비 조절 변수, 클수록 마진 너비가 좁아지고, 적을수록 마진 너비가 넓어짐
- 감마: 커널의 표준 편차 조절 변수, 작을수록 데이터포인트의 영향이 커져서 경계가 완만해짐, 클수록 데이터포인트가 결정 경계에 영향을 적게 미쳐 경계가 구부러짐.
((✔ 아래 시각화 그래프를 통해 확인))
🔎 svm의 장단점
장점
1) 커널 트릭을 사용하여 특성이 다양한 데이터를 분류하는 데 강하다.
( N개의 특성을 가진 데이터는 N차원 공간의 데이터 포인트로 표현, N차원 공간 또는 그 이상의 공간에서 초평면을 찾아 데이터 분류가 가능하기 때문)
2) 파라미터를 통해 과대적합, 과소적합을 막을 수 있다.
3) 적은 학습 데이터로도 높은 분류가 가능하다.
단점
1) 데이터 전처리 과정이 중요하다.
( 데이터의 특성이 다양하거나, 확연히 다른 경우에 데이터 전처리 과정을 통해 데이터 특성 그대로 벡터 공간에 표현해야 함)
- 스케일링에 따라 데이터들이 찍히는 위치가 달라짐-> 그에 따라 결정 경계가 달라짐!
스케일링이란? 데이터들의 차원을 맞춰주는 것!
2) 데이터 특성이 많을 경우 결정 경계 및 데이터의 시각화가 어려움
⚙ 참고) 그리드 서치(gridsearch)
그리드 서치는 개발자가 부여한 비용고 감마 후보들을 모두 조합해서 최적의 비용과 감마 조합을 찾아냄
(=그리드 서치를 이용하면 간편하게 최적의 비용과 감마를 알아낼 수 있음!)
💻 svm 실습 [분류]
| 변수 | 설명 |
|---|---|
| Player | 선수이름 |
| Pos | 포지션 |
| 3P | 한 경기 평균 3점슛 성공 횟수 |
| 2P | 한 경기 평균 2점슛 성공 횟수 |
| TRB | 한 경기 평균 리바운드 성공 횟수 |
| AST | 한 경기 평균 어시스트 성공 횟수 |
| STL | 한 경기 평균 스틸 성공 횟수 |
| BLK | 한 경기 평균 블로킹 성공 횟수 |
[ 농구 선수 게임 기록 학습을 통한 포지션 예측하기 실습 ]
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
import numpy as np
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/PYTHON/basketball_stat.csv")
df.drop(['2P','AST','STL'],axis=1,inplace=True)
from sklearn.model_selection import train_test_split
train,test = train_test_split(df,test_size=0.2) # 20%를 테스트 데이터로 분류
def svc_param_selection(x,y,nfolds):
svm_parameters = [
{'kernel':['rbf'],
'gamma':[0.00001,0.0001,0.001,0.01,0.1,1],
'C':[0.01,0.1,1,10,100,1000]
}]
clf = GridSearchCV(SVC(), svm_parameters, cv=10) #cv = 교차검증을 위한 fold 횟수
clf.fit(x_train,y_train.values.ravel()) #ravel 다차원 배열을 1차원으로
print(clf.best_params_)
return clf
x_train = train[['3P','BLK']]
y_train = train[['Pos']]
clf = svc_param_selection(x_train,y_train.values.ravel(),10)
#최적의 파라미터로 학습된 svm 모델 시각화
#시각화할 비용 후보들 저장
C_candidates = []
C_candidates.append(clf.best_params_['C']*0.01)
C_candidates.append(clf.best_params_['C'])
C_candidates.append(clf.best_params_['C']*100)
#시각화할 감마 후보들 저장
gamma_candidates = []
gamma_candidates.append(clf.best_params_['gamma']*0.01)
gamma_candidates.append(clf.best_params_['gamma'])
gamma_candidates.append(clf.best_params_['gamma']*100)
#3점슛과 블로킹 횟수로 학습
x = train[['3P','BLK']]
#농구선수 포지션을 학습 모델의 분류값으로 사용
y = train['Pos'].tolist()
#시각화를 위해 센터(C)와 슈팅가드(SG)를 숫자로 표현
position=[]
for gt in y:
if gt =='C':
position.append(0)
else:
position.append(1)
import matplotlib.pyplot as plt
plt.figure(figsize=(16,16))
xx,yy= np.meshgrid(np.linspace(0,4,100),np.linspace(0,4,100))
for (k,(C,gamma,clf)) in enumerate(classifiers):
z = clf.decision_function(np.c_[xx.ravel(),yy.ravel()])
z = z.reshape(xx.shape)
plt.subplot(len(C_candidates),len(gamma_candidates),k+1)
plt.title("gamma = 10^%d, C=10^%d" % (np.log10(gamma),np.log10(C)),
size='medium')
plt.pcolormesh(xx,yy,-z,cmap=plt.cm.RdBu)
plt.scatter(x['3P'],x['BLK'],c=position,cmap=plt.cm.RdBu_r,edgecolors='k')
#파라미터 후보들을 조합해서 학습된 모델들 저장
classifiers = []
for C in C_candidates:
for gamma in gamma_candidates:
clf = SVC(C=C,gamma=gamma)
clf.fit(x,y)
classifiers.append((C,gamma,clf))
x_test = test[['3P','BLK']]
y_test = test[['Pos']]
y_true,y_pred = y_test, clf.predict(x_test)
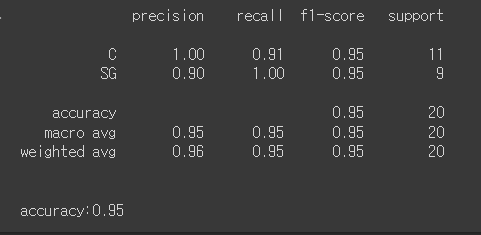
print(classification_report(y_true,y_pred))
print()
print('accuracy:' + str(accuracy_score(y_true,y_pred)))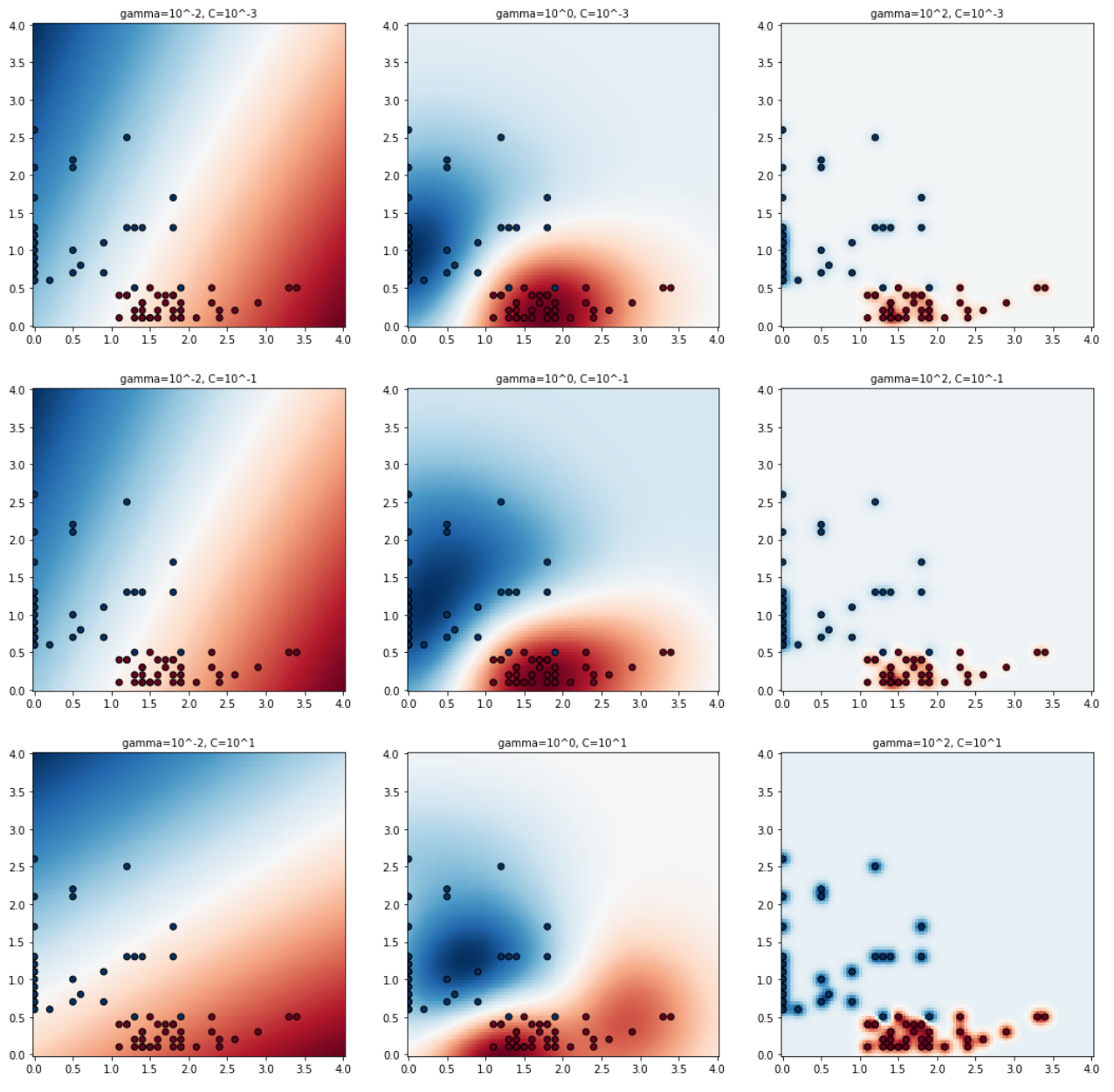
🔎 시각화 그래프 해석
- 좌/우로 비교해 보면 감마의 크기에 따른 결정 경계의 곡률 변화를 확인할 수 있음!
(커널의 표준 편차 조절 변수, 작을수록 데이터포인트의 영향이 커져서 경계가 완만해짐, 클수록 데이터포인트가 결정 경계에 영향을 적게 미쳐 경계가 구부러짐) - 위/아래로 비교해 보면 C의 크기에 따른 결정 경계선 위치 변환을 확인할 수 있음!
(마진 너비 조절 변수, 클수록 마진 너비가 좁아지고, 적을수록 마진 너비가 넓어짐)- (1,1)에 위치한 그래프 : gamma ⬇️ / 결정경계에 영향이 크다. / 완만하다. cost ⬇️ / 마진이 크다.
- (3,3)에 위치한 그래프 : gamma ⬆️ / 결정경계에 영향이 작다. / 구부러진다. cost ⬆️ / 마진이 작다.
🔎 실행결과