📌 비선형 차원축소
원래의 데이터 형태가 선형이 아닌 곡선과 같이 비선형을 나타내는 모형일 때 더 성능이 좋음
EX) MNIST 데이터 셋에 대해 차원 축소를 고려하면, 8과 같은 숫자들은 곡선들로 이루어짐 = T-SNE와 같은 비선형 차원축소 알고리즘을 사용하면 더 성능이 좋음
PCA의 경우 선형 분석 방식이었기 때문에 차원을 감소히키면 군집화 되어 있는 데이터들이 뭉게지는 문제가 발생한다.
👉 이 문제를 해결하기 위한 방법이 t-SNE!
t-SNE는 거리를 확률로 바꾸어 접근하는 방식으로, SNE(Stochastic Neighbor Embedding)을 변형한 기법이다.
🔎 SNE (Stochastic Neighbor Embedding)
고차원의 데이터 n개를 동일한 개수의 저차원의 데이터로 만들고자 하고, 차원을 줄이더라도 데이터간의 거리는 원래와 유사하게 하고자 하는 것
= 기존에 이웃이었던 점들을 차원 축소 후에도 이웃으로 유지시키는 것
📌 t-SNE (티스니)
고차원 데이터의 시각화를 위한 비선형 차원 축소 알고리즘입니다. t-SNE 알고리즘은 데이터 포인트 간의 유사도를 보존하면서 고차원 데이터를 저차원으로 투영
-
데이터 포인트 간의 거리를 정의하기 위해 가우시안 분포를 사용
- 각 데이터 포인트 i에서 다른 데이터 포인트 j까지의 유사도를 유클리드 거리로 계산
- 이 거리를 가우시안 분포로 변환
- 각 데이터 포인트 i에서 다른 데이터 포인트 j까지의 조건부 확률 분포를 계산
👉 이 조건부 확률 분포는 i가 j와 가까울수록 높아짐 (가우시안 분포는 평균과 분산을 갖는 확률 분포로, 평균 값에 가까울수록 높은 값을 가짐)
-
t-SNE 알고리즘은 저차원에서도 데이터 포인트 간의 거리를 가우시안 분포로 정의
🔎 저차원에서 가우시안 분포 계산?
- t-SNE 알고리즘은 KL 발산을 최소화하는 방식으로 저차원에서의 가우시안 분포KL(Kullback-Leibler divergence,쿨백 라이블러 발산) 발산
KL 발산은 두 확률 분포의 차이를 계산하는 지표로 사용되는 것
더 쉽게 말하자면, 두개의 확률 분포 A,B가 있을 때, A에서 특정 사건이 발생할 확률과 B에서 특정 사건이 발생할 확률이 얼마나 차이가 나는지를 나타냄
✔ P = 원래의 확률 분포이고, Q = 비교 대상의 확률 분포
✔ KL 발산은 항상 양수이며, 두 분포가 완전히 일치할 경우에는 0의 값을 가짐
t-SNE에서는 고차원 데이터와 저차원 데이터 간의 확률 분포를 비교하여 KL 발산을 최소화하는 방식으로 저차원에서의 데이터 포인트를 찾아냄. 이를 통해 고차원 데이터의 구조를 최대한 보존하면서 저차원에서 시각화 가능한 형태로 변환!
- t-SNE 알고리즘은 확률 분포의 그래디언트를 계산해 저차원의 데이터 포인트를 이동시킴
👉 이 과정을 반복해서, 고차원 데이터의 구조를 최대한 보존하면서 저차원에서 시각화 가능한 형태로 변환하는 것!
💻 MNIST 데이터셋을 이용한 t-SNE 실습
perplexity
- t-SNE에서의 중요한 하이퍼파라미터 중 하나
- t-SNE가 고차원 데이터의 구조를 보존하면서 저차원으로 축소하는 데 얼마나 많은 주변 데이터 포인트를 고려할지를 결정
👉 t-SNE에서는 각 데이터 포인트 i를 중심으로 하여 거리에 따른 가중치를 부여하는데, 이 가중치는 perplexity 값에 의해 결정된다! 이때, perplexity 값은 각 데이터 포인트의 가중치를 조정하는 데 사용된다. 작은 perplexity 값은 작은 영역 내의 가중치를 높여주고, 큰 perplexity 값은 넓은 영역 내의 가중치를 높여주는 역할을 하는 것
- t-SNE가 고차원 데이터의 구조를 보존하면서 저차원으로 축소하는 데 얼마나 많은 주변 데이터 포인트를 고려할지를 결정
- 5에서 50까지 선택할 수 있으며, 데이터셋에 따라 최적의 값을 찾아야 함
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.manifold import TSNE
# MNIST 데이터셋 다운로드
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
#입력 데이터(이미지 데이터는 각 픽셀의 밝기 정보를 담고 있는 행렬 형태이므)의 최대값인 255로 나눠서 0~1사이의 값으로 변경(스케일)
X = mnist.data / 255.0
#y값은 라벨 정보(0-9로 구성)
y = mnist.target
# t-SNE를 사용하여 2차원(n_components=2)으로 축소
tsne = TSNE(n_components=2, perplexity=30, verbose=1) #verbose =1 학습 로그 출력
X_tsne = tsne.fit_transform(X)
# 시각화
plt.figure(figsize=(10, 10))
#X_tsne[:, 0]와 X_tsne[:, 1]는 각각 n_components로 설정된 차원 수에 해당하는 축
#만약 n_components를 3으로 설정하면, X_tsne[:, 0], X_tsne[:, 1] 및 X_tsne[:, 2]는 각각 x, y 및 z 축을 나타내게 됨
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y.astype(int), cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(ticks=range(10))
plt.title('MNIST dataset t-SNE Visualization graph')
plt.show()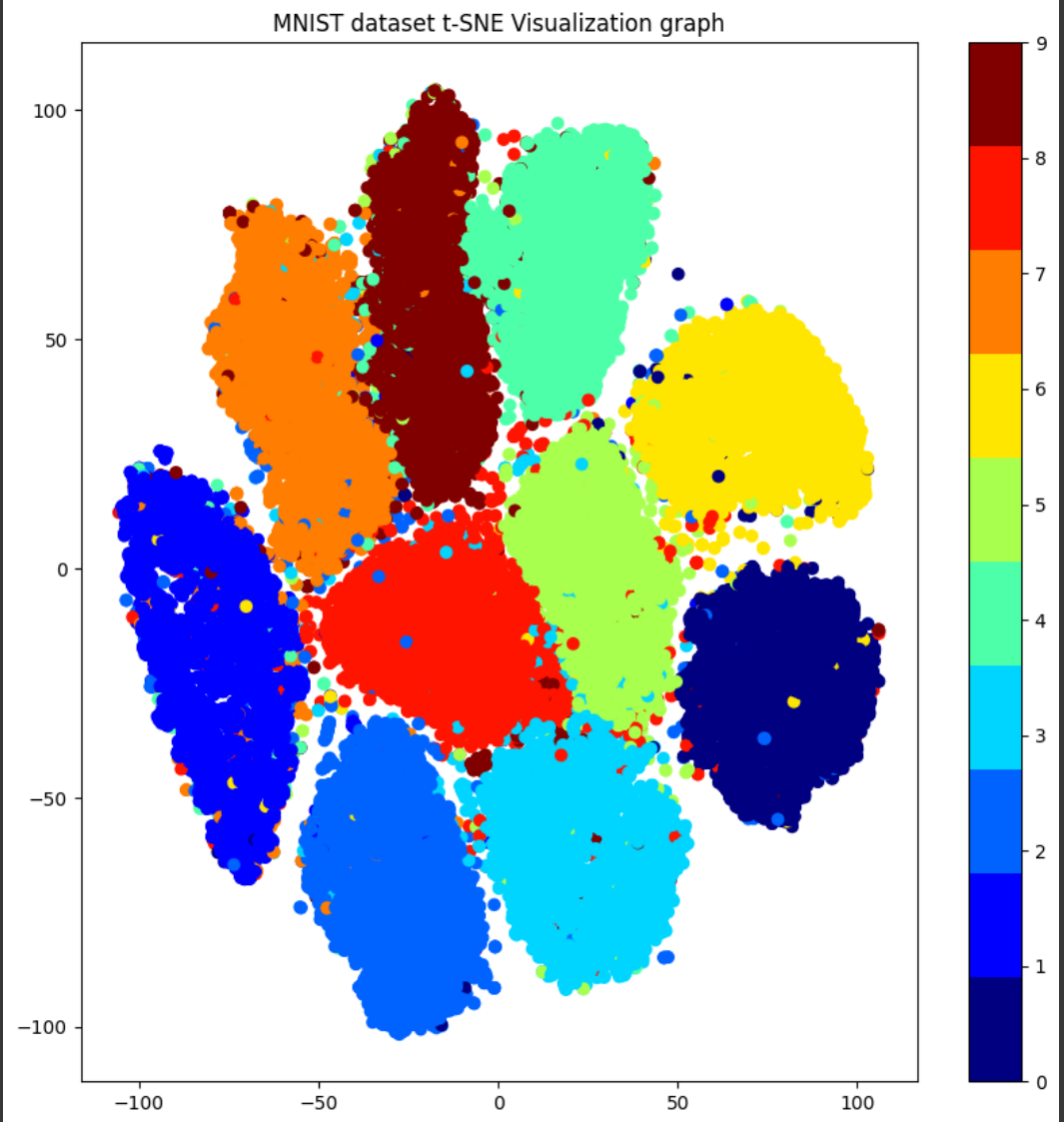
시각화 그래프 해석해보기
💎 각 점은 각각의 이미지를 의미
💎 색상은 해당 이미지가 어떤 숫자를 나타내는지(0-9)
💎 0과 6은 비슷한 모양이기 때문에 가까이 위치
