🔎 차원축소
-
차원축소는 고차원데이터를 저차원 공간으로 변환(매핑)하는 과정으로, 불필요한 특성을 제거하거나 데이터의 중요한 특성만을 유지하면서 데이터를 단순화할 수 있다.
-
차원 축소는 대표적으로 주성분 분석(PCA), 다차원 척도법(MDS),t-SNE 등의 방법이 있다.
❓ 차원 축소가 왜 필요한가
고차원 데이터는 많은 특성을 포함하며, 이런 특성이 많아질수록 데이터의 복잡성, 계산 복잡성이 증가
❓차원축소에서 '매핑'이란
고차원 공간의 데이터 포인트들을 저차원 공간으로 변환하는 과정!
이는 보통 션형 변환 또는 비선형 변환을 통해 이루어진다.
-
선형 변환
데이터를 회전, 확대/축소, 이동 등의 변환으로 단순화 할 수 있으며, 주성분 분석 등에서 사용된다. -
비선형 변환
데이터의 복잡한 패턴과 구조를 보존하기 위해 사용된다.
비선형 변환의 대표적인 예로 t-SNE가 있는데, 데이터를 저차원 공간으로 매핑하며, 주로 시각화를 위해 사용된다.
📌 PCA (Principal Component Analysis)
PCA는 고차원 데이터를 저차원으로 축소하는 선형 변환 방법 중 하나로, 원본 데이터에서 가장 많은 정보를 담고 있는 주성분을 추출해 새로운 축으로 변환하게 된다.
PCA의 핵심 아이디어는??
👉 원본 데이터의 분산을 최대로 보존하는 새로운 축을 찾는 것!
📌 PCA 과정
-
데이터를 중앙으로 이동시켜 각 변수의 평균이 0이 되도록 함
✔ 데이터를 중앙으로 이동시킨 다는 것? 각 데이터의 값에서 해당 데이터 집합 전체의 평균을 뺀 값을 사용해 데이터를 다시 조정하는 것 (= 중앙으로 이동, 평균 제거)✔ 데이터의 분포를 원점에 맞추어줌으로써 데이터 간 거리를 계산하는 데에 있어서 분산을 최대화하고, 공분산 행렬의 고유 벡터를 찾아내기 쉽게 해주는 효과 -
데이터를 분산이 큰 순서대로 정렬
👉분산을 유지하는 이유는?
데이터의 고유한 특성을 최대한 유지하기 위해서! -
주성분 추출
-
주성분을 이용해 데이터를 새로운 축으로 변환
-
적절한 차원 수 결정
공분산
두 확률 변수가 함께 변화하는 정도를 나타내는 값으로, 두 변수 간의 상관 관계를 나타내는 통계적 지표
EX)영어를 잘하면 수학도 잘할까?가 궁금할 때
👉분산이 가장 큰 차원은 공분산 행렬에서 고윳값이 가장 큰 고유벡터
- 공분산 행렬은 대칭행렬이며, 고유값 분해를 통해 고유 벡터와 고유값을 계산할 수 있음
고유벡터?
-
어떤 선형변환을 가해도 방향이 변하지 않고, 그 크기만 변하는 벡터
-
어떤 행렬 A가 주어졌을 때, 아래의 식을 만족하는 비 영벡터 X를 고유벡터, λ를 고유값이라 함
PCA는 이 공분산 행렬의 고유벡터 중 고유값이 가장 큰 순서대로 차원을 축소함
👉 고유값이 큰 고유 벡터는, 데이터의 분산이 가장 큰 방향을 나타내고, 새로운 좌표축을 구성할 때 이러한 방향을 우선적으로 고려하게 되는 것!
= 즉, 분산이 가장 큰 고유값을 갖는 고유벡터를 선택하는 것은, 데이터의 분산을 최대한 보존하는 주성분을 찾는 것과 같은 의미!비영벡터
모든 요소가 0이 아닌 벡터,벡터는 크기와 방향을 가지는 개체이기 때문에 크기가 0인 벡터를 영벡터(zero vector)라고 한다. 따라서, 비영벡터는 크기와 방향을 가지며, 영벡터와 대조된다!
💻PCA 실습
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 데이터 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# PCA 모델 생성 및 학습
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 2차원 산점도 그래프 그리기
plt.scatter(X_pca[:,0], X_pca[:,1], c=y)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('PCA of IRIS dataset')
plt.show()
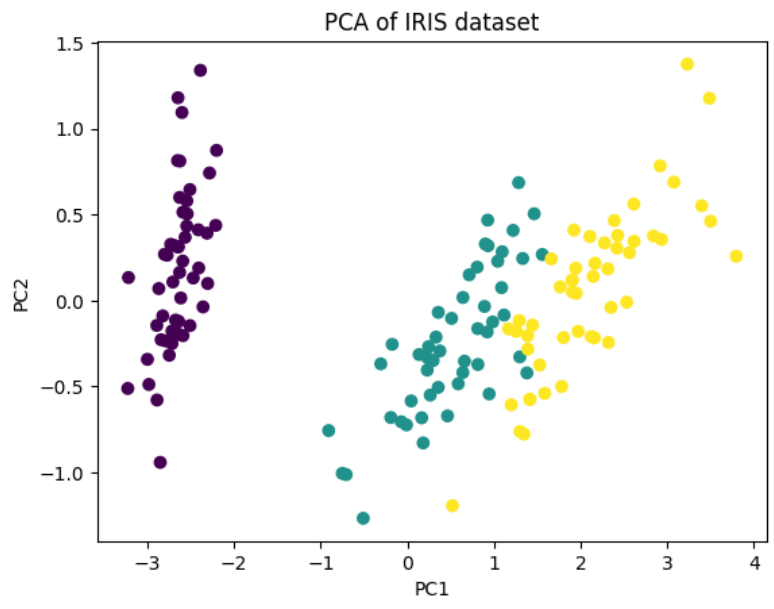
-
원래 iris 붓꽃 데이터는 4개의 feature를 가진 4차원 공간의 데이터이다. 시각화 그래프로 보기 위해 2차원으로 차원 축소를 해 산점도 그래프로 나타낸 실습이다!
-
pca1과 pca2는 주성분 중 가장 설명력이 높은 첫 번째 주성분(PC1)과 두 번째 주성분(PC2)으로 추출된 결과
