비지도 학습은 데이터에서 패턴을 찾고 분류하는 것을 목적으로 하며, 주어진 데이터에 대한 사전 지식 없이 스스로 학습을 수행한다.
📍 연관 규칙 분석이란?
Association rule analysis
연관규칙분석은 데이터의 아이템들 사이에서 발생하는 규칙을 찾아내는 것으로, 규칙이 발생하기 위해 어떤 아이템들이 함께 나타나는지를 분석한다.
👉 마트에서 구매한 제품들의 구매 기록 데이터에서 어떤 제품들이 함께 구매되는지 분석하는 것이 연관규칙분석의 대표적인 예시다.
👉조금 더 최신 트렌드에 기반하여 예시를 들자면, 인터넷 쇼핑 등 다양한 컨텐츠 기반 추천에 사용되고 있다!
📍 연관 규칙 분석 알고리즘 종류
1. Apriori algorithm
2. FP-Growth algorithm
3. DHP algorithm
이 중 가장 널리 쓰이는 것이 Apriori algorithm이며, 알고리즘 구현이 비교적 간단하고 높은 수준의 성능을 보인다
🔎 Apriori 알고리즘이란?
- 특정 사건이 발생했을 때 함께 발생하는 또 다른 사건의 규칙이다.
- 빈발항목집합을 추출하는 것이 원리이다.
✔ 빈발항목집합? 최소 지지도 이상을 갖는 항목 집합!
📍 연관 규칙 분석의 지표
연관규칙분석은 지지도, 신뢰도, 향상도라는 3가지 지표를 이용해 연관성을 측정한다.
1. 지지도 (support)
Support(X->Y)
- 아이템 X,Y가 함께 거래된 비율
2. 신뢰도 (confidence)
Confidence(X->Y)
- X가 판매된 거래 중 아이템 Y가 판매된 거래의 비율
3. 향상도 (lift)
특정 아이템 X와 Y가 동시에 구매될 확률 대비 X와 Y가 서로 독립적으로 구매될 확률의 비율
-
lift > 1, 두 품목이 서로 양의 관계
👉 A를 샀을 때, B를 살 확률이 높은 것 -
lift = 1, 두 품목은 서로 독립적인 관계
-
lift < 1, 두 품목은 서로 음의 상관관계
👉 A를 샀을 때, B를 사지 않을 확률이 높은 것
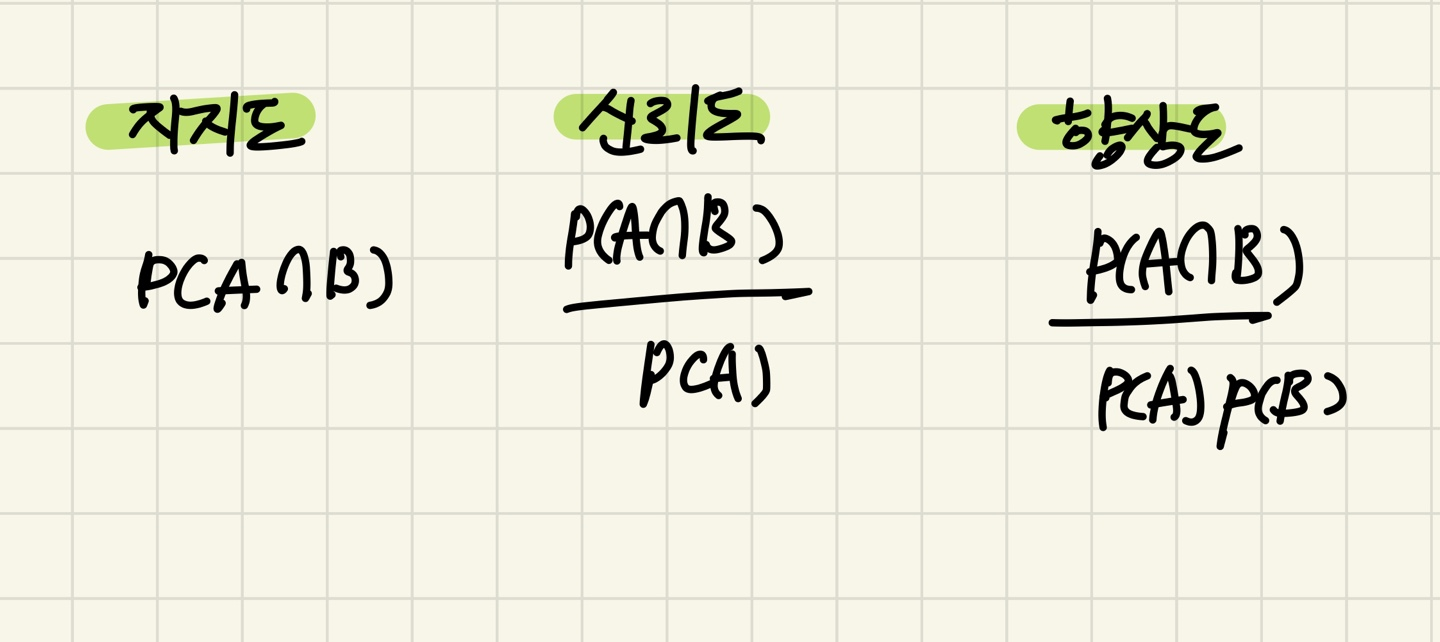 위와 같은 식으로 간단히 이해할 수 있다.
위와 같은 식으로 간단히 이해할 수 있다. 위의 예제를 통해 이해해보도록 하자.
위의 예제를 통해 이해해보도록 하자.
💻 Apriori 실습
data = [
['아메리카노', '카페라떼'],
['카페라떼', '아메리카노', '카푸치노'],
['바닐라라떼', '아메리카노'],
['녹차라떼', '카페라떼', '아메리카노'],
['카페모카', '아메리카노'],
['아메리카노', '카페라떼'],
['초콜릿', '아메리카노'],
['아메리카노'],
['카페모카', '카페라떼'],
['아메리카노','카페모카'],
['아메리카노','초콜릿'],
['초콜릿','카페모카'],
['바닐라라떼','아메리카노']
]
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
te = TransactionEncoder()
te_result = te.fit(data).transform(data)
te_result
import pandas as pd
df = pd.DataFrame(te_result,columns=['녹차라떼','바닐라라떼','아메리카노','초콜릿','카페라떼','카페모카','카푸치노'])
df
itemset = apriori(df, use_colnames=True)
itemset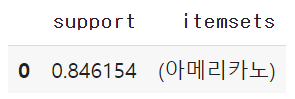
itemset = apriori(df, min_support=0.1, use_colnames=True) #최소 지지도 0.1 이상인 것만 추출
itemset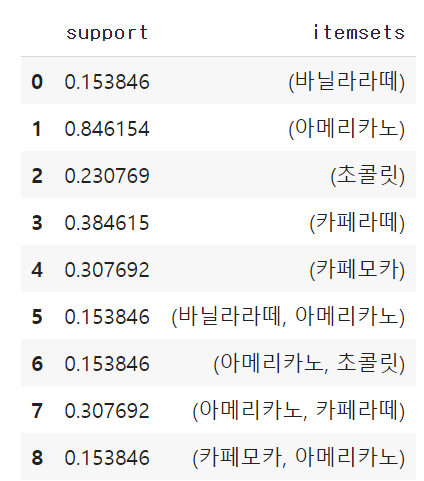
from mlxtend.frequent_patterns import association_rules
association_rules(itemset, metric="confidence", min_threshold=0.1) #최소 신뢰도 0.1 이상인 것만 추출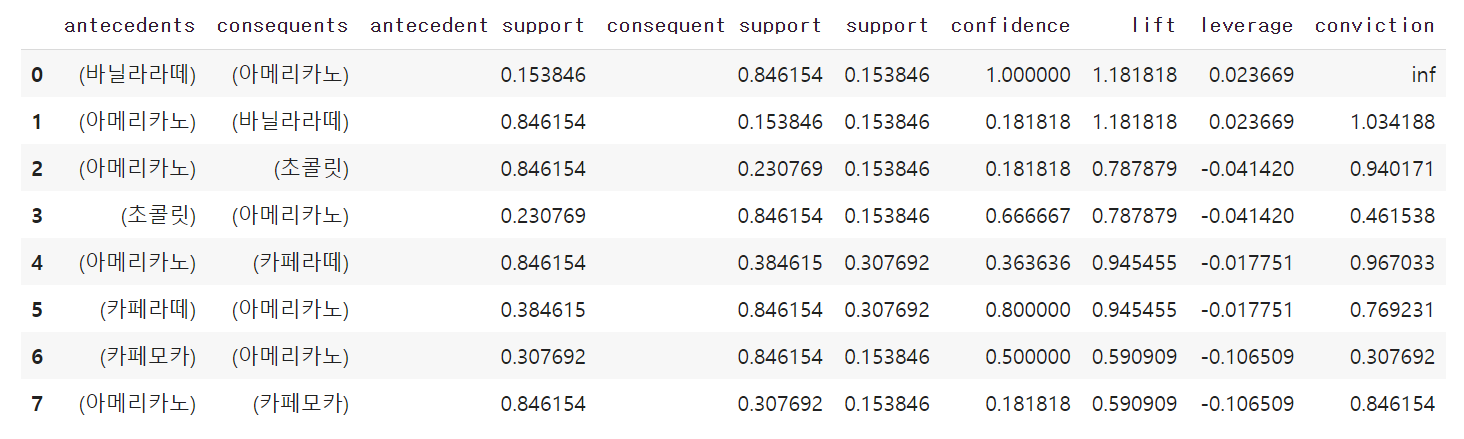
- lift > 1 인 것을 보면,(아메리카노->바닐라라떼),(바닐라라떼->아메리카노)가 같이 구매되는 확률이 있다고 볼 수 있다.

yunjin.log