BoostCamp Pstage
1.Boostcamp Pstage Day1(1, 2강)

캐글이나 데이콘 등으로 유명한 data science competition형태로 P stage를 진행한다.데이터 분석의 방향성을 설정할 수 있는 항목. 데이터의 의미, 목적, 산출물, 배경 도메인 등을 통해 의사결정을 도울 수 있다. 특히 해결해야할 문제에 대한 정의가
2.BoostCamp Pstage day1 EDA

COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게 되었습니다. 우리나라는 COVID-19 확산 방지를 위해 사회적 거리 두기를 단계적으로 시행하는 등의 많은 노력을 하고 있습니다. 과거 높은 사망률을 가진 사스(S
3.Boostcamp Pstage Day2(3, 4강)

Data Processing의 단계에서는 주어진 vanilla Data를 모델이 좋아하는 형태로 변환한 것이 Dataset이다.실제 데이터는 Competition 데이터와 다르게 Noise가 있기도 하고 결측치 등으로 인해 활용하기 어려운 데이터인 경우가 대다수이다.
4.BoostCamp Pstage day2 Dataset/DataLoader
train_model은 같은 디렉토리 내에 있는 train_model.py 파일로, ViT 모델을 담고 있다.다른 것보다도, 사진파일이 같은 사람이 연속으로 7장 나오는 형태이기 때문에 shuffle은 True값을 주는 것이 자명하다고 생각한다.Transform을 이용
5.BoostCamp Pstage day3
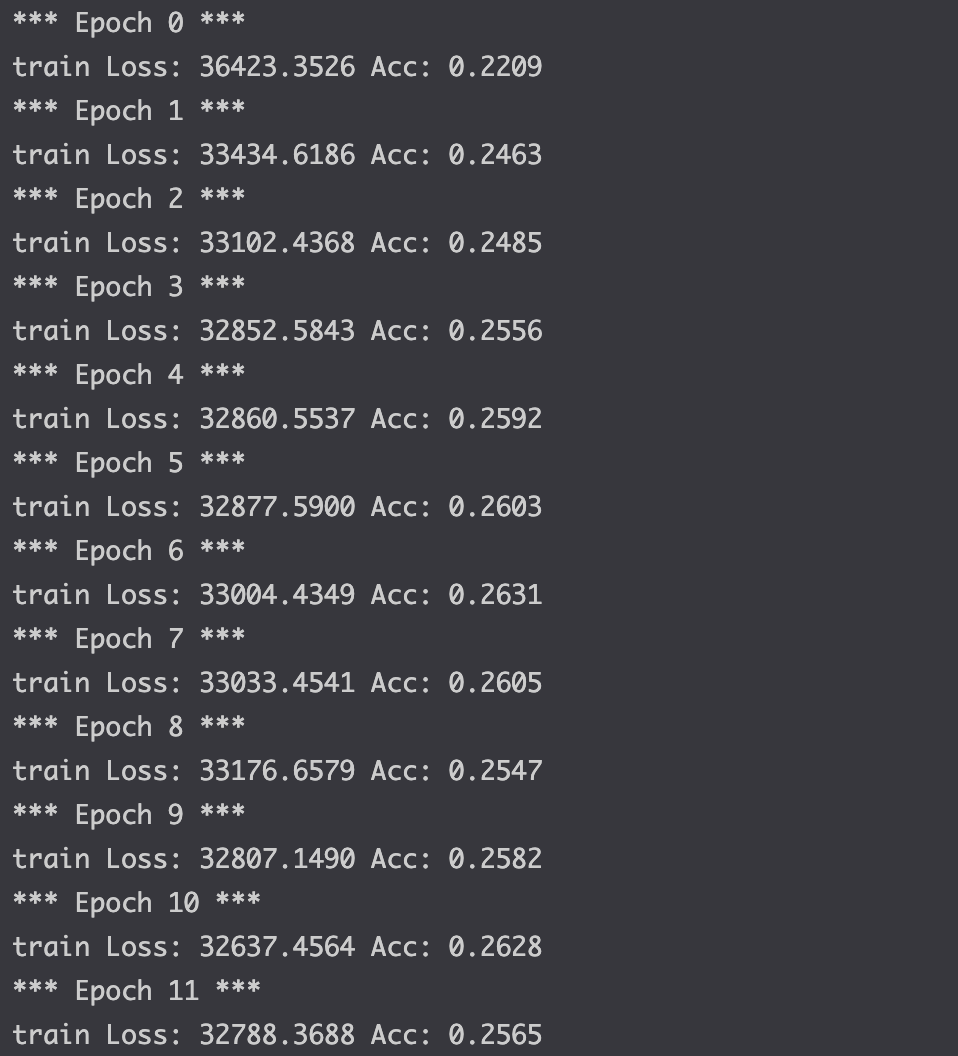
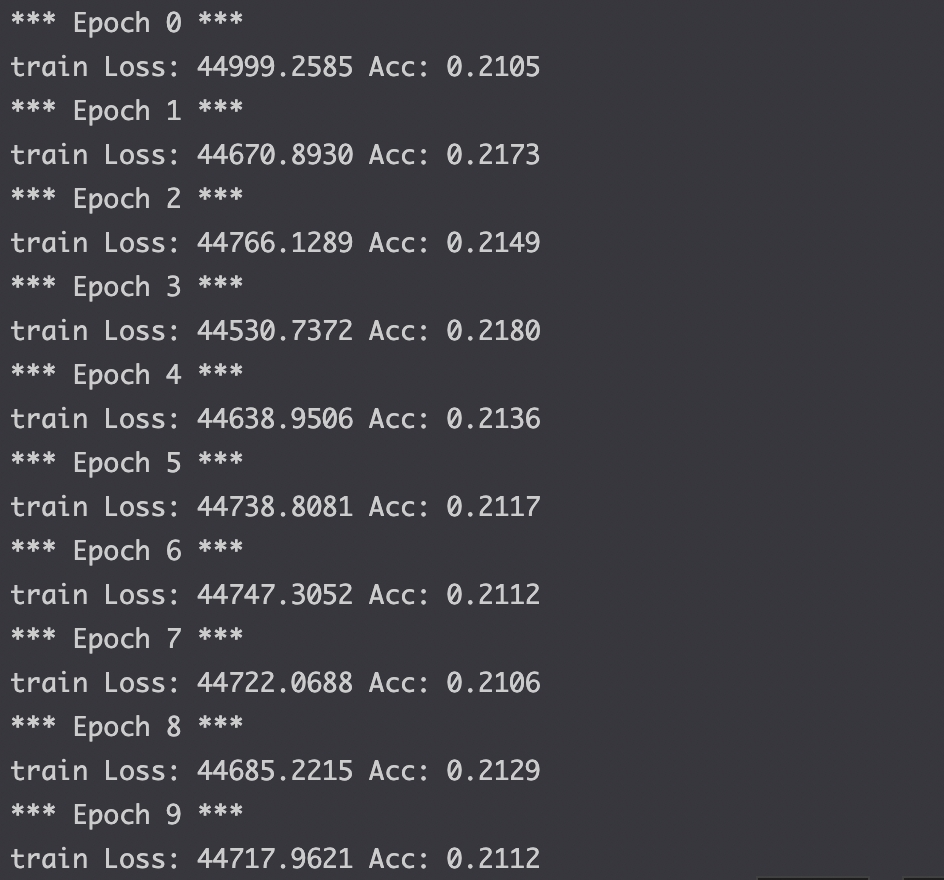
pretrained 모델을 활용했으나 학습데이터에서도 성능이 여전히 좋지 않았다.huggingface에서 pretrained모델을 불러와서 더 해볼 생각이다.
6.BoostCamp Pstage day3 Model

In general, a model is an informative representation of an object, person or system14 million images, 20 thousands categories대용량 데이터는 필수좋은 품질, 대용량의 데이
7.BoostCamp Pstage day4 Model
Loss 함수 = Cost함수 = Error함수Loss는 Module을 상속하는 같은 Family이고, 따라서 Criterion에 output을 넣게되면 input에서 output까지 연결된 어떠한 체인이 loss까지 연결되었고, backward함수를 통해 Gradie
8.BoostCamp Pstage day4

해야할 것1\. wandb chart로 나오게2\.
9.BoostCamp Pstage day5
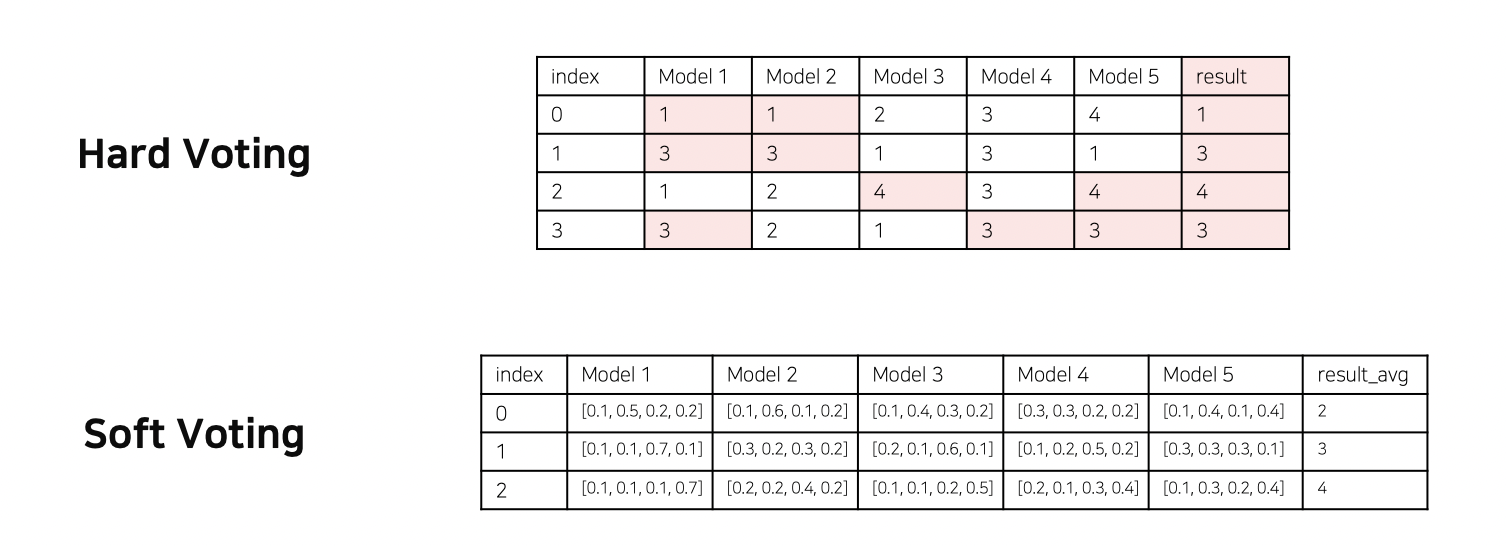
validation을 train set에서 여러번 진행할 수 있다.클래스의 분포를 고려한 validation은 Stratified K-fold라고 한다.test set에 augmentaion을 적용했을 때 판단하기 어려워하지 않을까?앙상블만큼이나 시간이 많이 걸리지만