Dataset
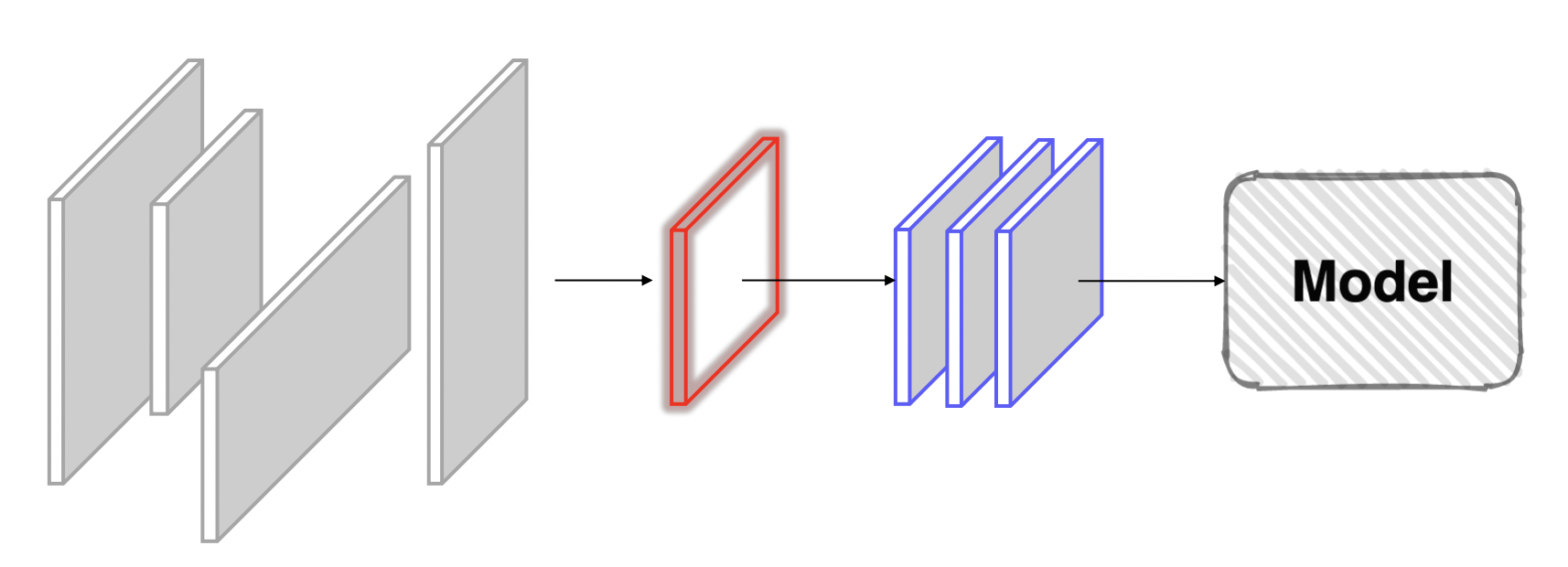
Data Processing의 단계에서는 주어진 vanilla Data를 모델이 좋아하는 형태로 변환한 것이 Dataset이다.
Pre-processing
실제 데이터는 Competition 데이터와 다르게 Noise가 있기도 하고 결측치 등으로 인해 활용하기 어려운 데이터인 경우가 대다수이다. 따라서 적절한 전처리과정은 Data Science Pipeline에서 매우 중요한 과정이다.
Bounding Box
자동차를 학습하는 과정이라면 자동차 이외의 부분은 사실상 필요 없는 정보, 노이즈에 가깝다.

Resize
계산의 효율을 위해서 사진을 적당한 크기로 변경해줄 수 있다.
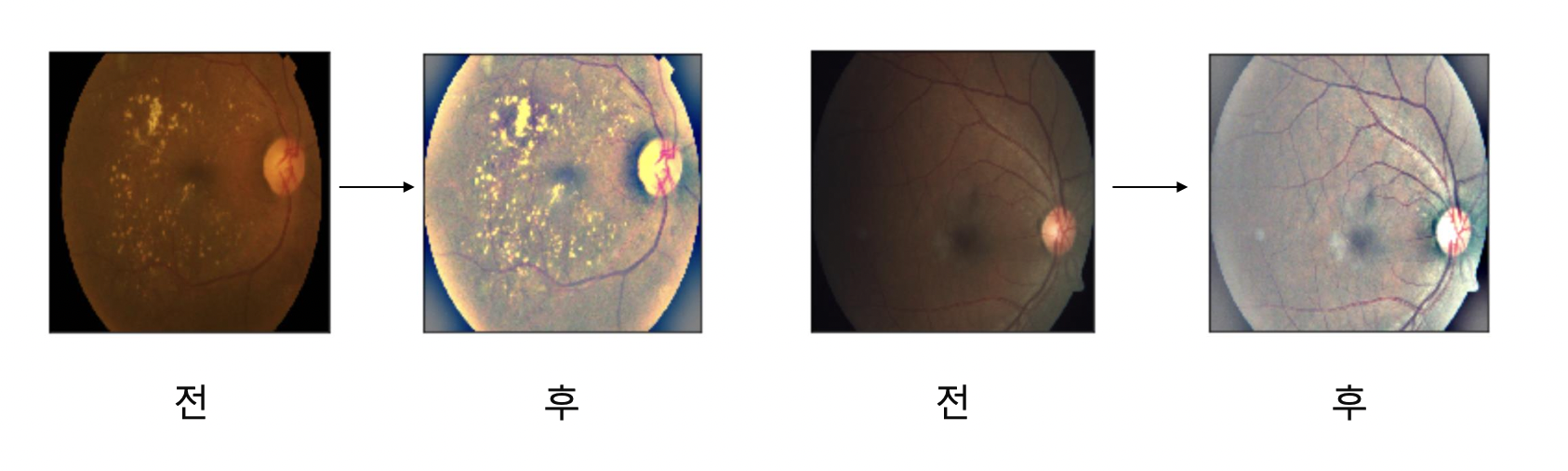
Example : APTOS Blindness Detection
사진의 밝기나 대비를 조절하여 학습의 성능을 높일 수 있다.
Generalization
Train/Validation
훈련 셋 중 일정 부분을 따로 분리, 검증 셋으로 활용
학습에 활용되지 않은 데이터를 통해 Generalize하는 것
Data Augmentation
주어진 데이터가 가질 수 있는 Case, State의 다양성
밝기,흐리게,상하반전 등 데이터의 도메인에서 발생할 수 있는 경우를 고려할 수 있다.
- torchvision.transforms
- RandomCrop, Flip
- Compose함수를 이용해 다양한 image data augmentation이 가능하다.
- Albumentation

하지만,
항상 좋은 결과를 가져다 주지는 않는다. 여러 도구 가운데 하나일 뿐, 무조건 적용 가능한 마스터키 같은 것도 사실 없다.
주제를 깊이 관찰해서 어떤 기법을 적용하면 다양성을 지닐 수 있는지를 실험으로 증명하는 것.
Data Generation
Data Feeding
먹이를 주다 = 대상의 상태를 고려해서 적정한 양을 준다.
- 모델 처리 속도와 data generating 속도를 감안해주는 것이 좋다.
예로, Transforms 객체에서 이미지 변환을 적용할 때, Resize와 RandomRotation의 순서를 바꾸는 것만으로 소요 시간이 많은 차이가 날 수 있게 된다.
Dataset
from torch.utils.data import Dataset
__init__ # MyDataset 클래스가 처음 선언 되었을 때 호출
__getitem__ # MyDataset의 데이터 중 index 위치의 아이템을 리턴
__len__ # MyDataset 아이템의 전체 길이
DataLoader
torch.utils.data.DataLoader(train_set,
batch_size = batch_size,
num_workers = num_workers,
drop_last = True)
Today is the day