Modules
import os
import pandas as pd
import numpy as np
from PIL import Image
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torchvision.transforms import Resize, ToTensor, Normalize
import plotly.express as px
from tqdm.notebook import tqdm
from glob import glob
import train_modeltrain_model은 같은 디렉토리 내에 있는 train_model.py 파일로, ViT 모델을 담고 있다.
Random Seed
SEED = 25
random.seed(SEED)
np.random.seed(SEED)
os.environ["PYTHONHASHSEED"] = str(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED) # type: ignore
torch.backends.cudnn.deterministic = True # type: ignore
torch.backends.cudnn.benchmark = True # type: ignoreDataset
dataset 구현에서 가장 신경쓴 부분은 __getiem__함수이다. index를 7로 나눈 몫과 나머지를 각각 변수로 저장해서 해당하는 사진 파일을 가져온다. 해당 파일의 사진을 열기 위해 glob, os.path.join 함수 등을 사용하였으며 클래스를 지정해주기 위해 itertools의 product함수를 사용해 리스트를 생성하고 인덱스를 찾아주는 형식으로 만들었다.
Model
ViT모델을 사용했으며, 마스크 착용 사진 데이터가 512X384인데 비해 중요한 얼굴 파일은 주로 가운데 위치하는 모습을 알 수 있다. 따라서 256X256 크기로 CentorCrop을 해주기로 했다. 따라서 아래의 모델에서 img_size는 256으로 지정했다.
# Channel, img_size, patch_size, emb_dim,n_enc_layers, num_heads,forward_dim, dropout_ratio,n_classes
model = train_model.vision_transformer(3, 256, 16, 16*16*3, 15, 8, 4, 0.2, 18)
model.to(device)DataLoader
다른 것보다도, 사진파일이 같은 사람이 연속으로 7장 나오는 형태이기 때문에 shuffle은 True값을 주는 것이 자명하다고 생각한다.
dataloaders_train = DataLoader(dataset, batch_size=batch_size, shuffle = True, num_workers=1)Model Training
Transform을 이용해 CentorCrop, ToTensor, Normalize를 사용했고 epoch는 10, criterion은 CE, optimizer는 Adam을 사용했다. batch size는 16으로 진행했다.
그렇게 좋은 성능이 나오지는 않았다.
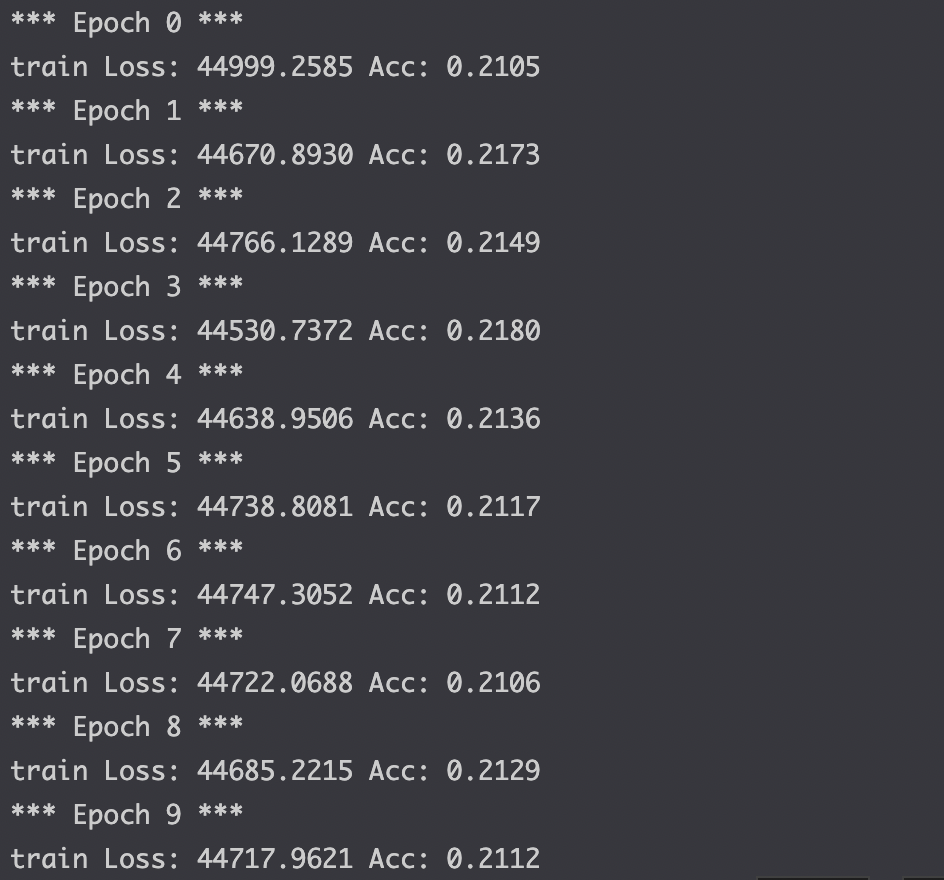
Model evaluation
valid(test) dataset과 dataloader를 각각 정의해준다. valid dataset은 이 Competition에서 테스트 데이터이므로 naming이 test와 혼동될 수 있다. shuffle을 False로 한 상태로 데이터를 불러오고, 결과값에 대해서 csv파일로 저장해 제출했다.
결과
Accuracy : 9.6984%
f1-score : 0.0098
현재 등수 : 82
그냥 랜덤하게 돌린 것보다 성능이 안좋게 나왔다. 제대로 학습이 되지 않은 것 같다.
더 해야할 것
- 내일 공개되는 Dataset과 DataLoader를 사용해서 효율성 올리기
- ResNet활용해보기
- ViT pretrain 모델 사용 가능한지 확인해보기
- Data Augmentation 및 데이터 추가에 대해 알아보기.
- Imbalanced Class에 대한 해결책 생각해보기
