Abstract
- 본 논문에서는 News image captioning을 위한 visual News Caption 모델을 제안한다.
- 또한 100만 개 이상의 news image와 article, image caption, meta data등으로 구성된 Visual News data를 설명한다.
본 논문에서는 Visual News Caption 모델이 event, entity와 같은 정보들이 포함된 caption을 생성할 수 있도록, visual, image 데이터의 feature를 효과적으로 결합한다.
1. Introduction
News Image Captioning
- News Image Captioning은 News Image와 기사를 이용해 News Image의 caption을 생성하는 Task이다.
- News Caption은 이미지의 요소를 깊고 구체적으로 설명하고 특정한 장소, 사람, 이벤트 등의 named entity들을 포함하는 caption을 생성해야하기 때문에 Image caption 보다 어렵다.
COCO(Common Objects in Context Dataset)
- 기존 image caption task에 사용하는 COCO Dataset은 image caption 모델을 학습하기에 충분한 양의 데이터가 존재하지만, 일상적인 데이터에 편향되어 수집되었다.
- 또한 기존 COCO Dataset의 caption들은 자세한 해석보다는 단순한 설명에 가깝고 caption에 등장하는 객체를 일반적으로 표현하기 때문에 News Caption을 생성하는 모델을 학습하기엔 적합하지 않음
Visual News Dataset
- 백만개 이상의 다양한 news image, news caption, news article, author information, meta data로 구성된 datasets
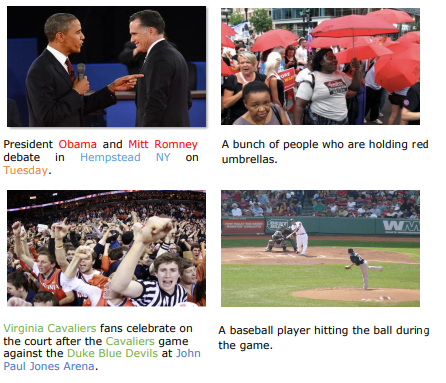
Visual News data(왼쪽)의 caption은 COCO data(오른쪽)에 비해 더 많은 정보를 담고 있다. 따라서 원 논문은 News Captioner에 적합한 Visual News Data를 사용한다.
2.Visual News Datasets
- Visual News Dataset 통계
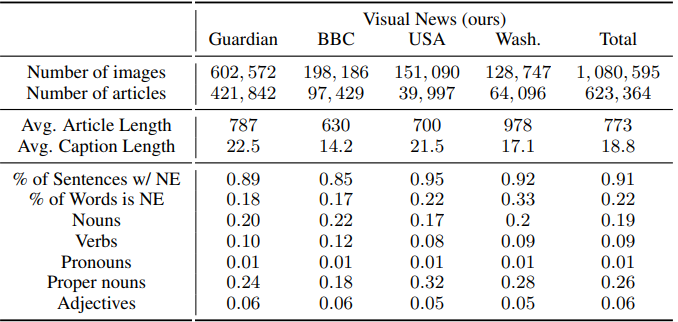
해당 논문에서 제시한 Visual News Datasets은 Guardian, BBC, USA Today, Washington Post 총 4개의 신문사로 부터 추출한 기사와 이미지 caption으로 구성 되어있다. 위 통계를 보면 모든 News Image는 1,000,000 개가 넘는 대규모 데이터셋이다.
- Visual News Dataset 예시
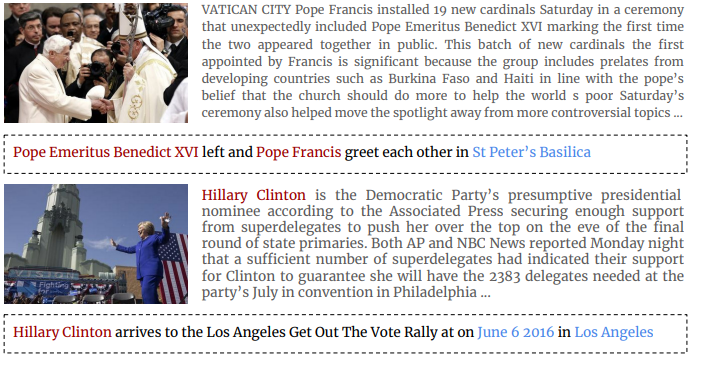
Visual News Data가 다른 News Data들에 비해 좋은점
- 논문이 쓰여질 당시 가장 큰 데이터 셋이다.
- 신문사 네 곳에서 기사와 이미지를 추출하였기 때문에 기사와 이미지가 다양하다.
3. Method
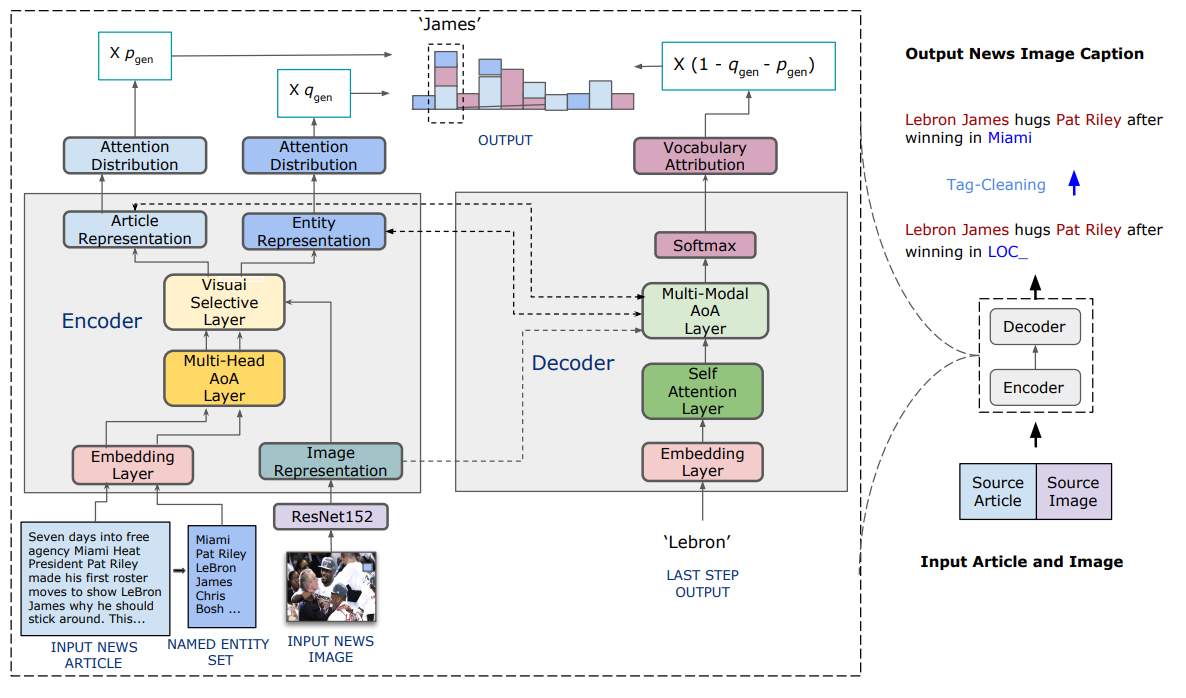
위 그림은 해당 논문에서 제시한 News Image Captioning 방법이다.
3.1 Image Encoder
image의 feature를 추출하기 위해 Image Encoder로 ImageNet에서 pre-trained Resnet152을 사용했다.
3.2 Text Encoder
뉴스 기사는 매우 길기 때문에 전체 기사 중 300개의 토큰만 사용, 이후 spaCy를 사용해서 기사에서 Entity를 추출한다.
News article과 Named Entitiy를 같은 Text Encoder에 각각 입력으로 넣어준다.
Word Embedding and Position Embedding
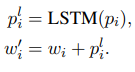
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
Multi-Head Attention on Attention Layer.
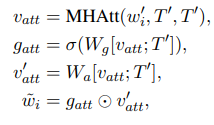
Visual Selective Layer
이전 연구들의 한계점은 image와 text에 대해 따로따로 encode했다는 점이다. 해당 논문에서는 image와 text 간 context 정보를 포함하는 representation을 생성하기 위해 Visual Selective Layer를 제안한다.
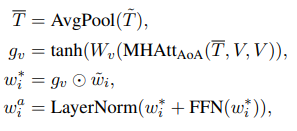
- Q,K,V를 각각 (src,src+img,src+img)로 MultiheadAttention에 입력한 결과 를 얻는다
- 이전 Multi-Head AoA의 출력 결과와 를 원소곱
3.3 Decoder
본논문에서의 Decoder는 이전에 생성된 토큰과 contextual information(encoder에서의 정보)를 이용해 다음 토큰을 생성한다.
Multi-Modal Attention on Attention Layer
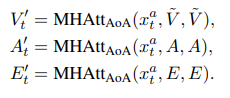
이전 time step에서 생성된 토큰 시퀀스
feature extractor(ResNet) image feature 정보
article의 encoded vector
Entity의 encoded vector
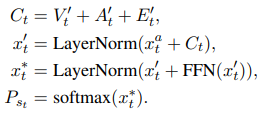
Multi-Head Pointer-Generator Module
추출된 named entity, 연관된 article로 부터 named entity를 얻기 위해 제안되었다
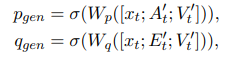
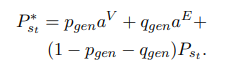
: Multi Modal Attention에서의 article의 attention score 평균
: Multi Modal Attention에서의 Entity의 attention score 평균
3.4 Tag-Cleaning
inference 시 OOV(out of vocabulary)를 해결하기 위해 OOV가 발생한 named entity를 "UNK"토큰 대신 named entity tag로 교체한뒤 모델의 입력으로 사용
e.g. "John Paul Jones Arena" -> "LOC_"
이후 inference시에 모델이 entity tag를 예측하면 entity set에서 같은 tag의 entity들 중 가장 많이 등장한 entity로 교체한다.
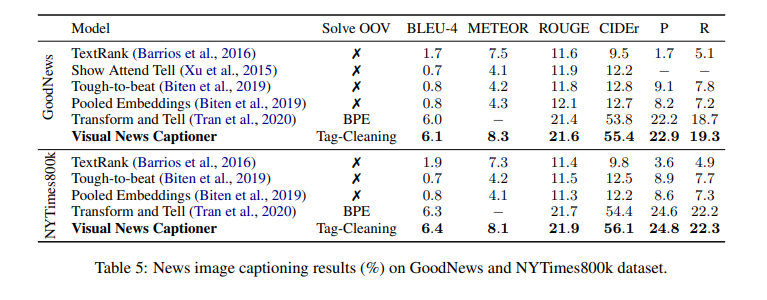
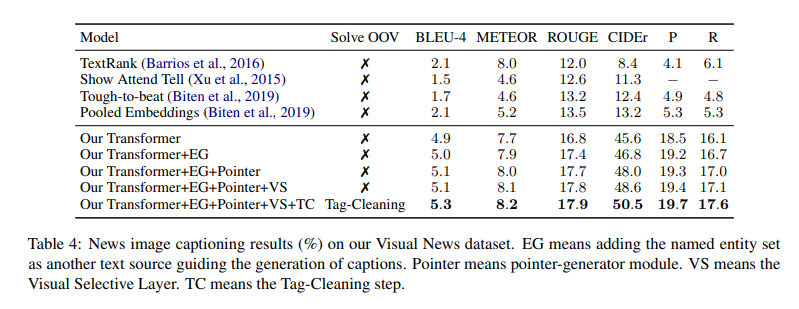
4. Experiments
-
Visual News dataset에 대한 평가 결과
-
GoodNews, NYTimes800k에 대한 평가 결과