Abstract
논문에서는 Image caption dataset인 MS-COCO dataset 보다 이미지 종류가 다양하고 대규모 사이즈의 데이터 셋인 Conceptual Captions data을 제시했다.
본 논문의 저자는 수십억개의 웹 페이지를 추출하고 필터링하여 해당 dataset을 구성했다. 또한 Inception-ResNet-v2기반의 모델을 이용해 conceptual caption과 MS-COCO dataset 간 성능을 비교한다.
1. Introduction
Image caption task는 크게 두 가지 분야가 발전하면서 진보해왔는데.첫번째로는 MS-COCO와 같은 많은 양의 annotated data를 활용할 수 있게 되면서, 두번째로는 Convolutional Neural Networks와 같은 강력한 모델 메커니즘을 사용할 수 있게 되면서이다.
본 논문의 저자는 이 두가지 data와 modeling 분야에 기여를 했다고 말하며 자세한 내용은 아래와 같다.

-
Data
본 논문의 저자는 COCO data 보다 더 많은 Image data로 구성된 Conceptual Caption dataset을 제공했다. 해당 dataset은 3.3M(3,300,000)개의 <image, description> 쌍으로 구성 되어있다.
또한 하나하나 신중히 선택한 데이터로 구성된 MS-COCO와 달리 Conceptual Caption의 image, caption은 web에서 추출 되고 필터링했기 때문에 MS-COCO보다 다양한 스타일을 표현할 수 있다.
-
modeling
논문에서 Image-feature extraction을 위해 사용된 모델은 Inception-ResNet-v2 모델이다.
caption generation을 위해 사용한 모델은 RNN기반 모델과 transformer 기반의 모델을 사용한다.
2. Related Work
image caption 의 발전 과정 등에 대한 설명
3. Conceptual Captions Dataset Creation
Conceptual Caption data는 아래 그림과 같은 pipeline으로 생성된다. 해당 pipeline은 수십억개의 webpages를 처리하며 이 webpages의 image와 alt-text로부터 <image, caption> 쌍을 추출하고 필터링한다. 자세한 내용은 밑에서 설명
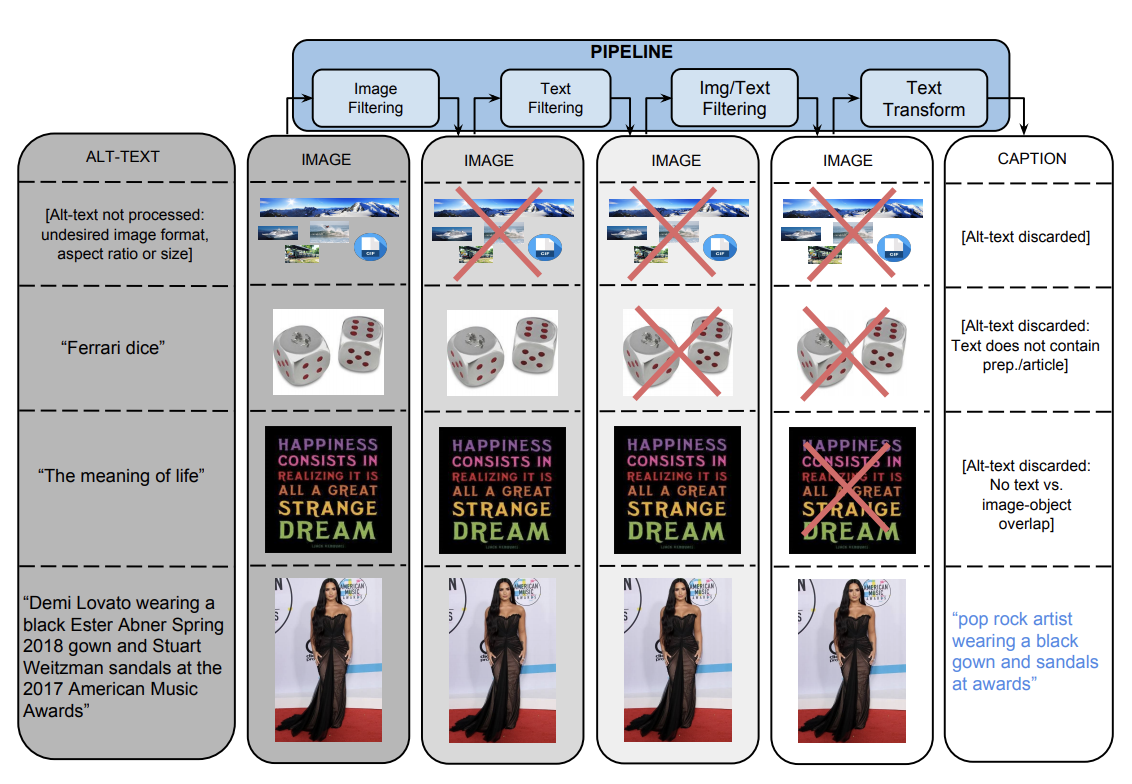
Image-based Filtering
pipeline의 첫번째 필터로서 image 기반 필터링이다. 인코딩된 이미지의 사이즈, 가로세로비율, 폭력적인 컨텐츠의 여하에 따라 image를 필터링한다. 아래 조건들을 모두 만족하는 image만 남는다.
- 이미지의 가로와 세로 모두 400 pixel 이상인 이미지
- 가로세로비율 2:1 혹은 1:2 미만인 이미지
- 음란물 혹은 비속어 탐지기에 감지되지 않는 이미지
해당 필터를 통해 전체 데이터의 65%는 걸러진다.
Text-based Filtering
두번째 필터링 구간으로 webpage HTML로 부터 Alt-text를 추출하는 구간이다. 아래와 같은 조건들을 만족해야한다.
(GooGle Natural language API를 이용해 POS 테그 분석, 폭력적인 컨텐츠 감지)
- 명사 혹은 전치사가 없거나 너무 많지 않은 텍스트
- 토큰이 많이 반복되지 않는 텍스트
- 대소문자 구별이 잘된 텍스트
- alt-text의 모든 토큰이 wikipedia에 5번 이상 등장하는 텍스트
- 자극적 혹은 폭력적인 내용이 없는 텍스트
해당 필터링을 진행하면 대략 3%의 후보 쌍만 남는다.
Image & Text-based Filtering
이미지와 텍스트 기반으로 필터링하는 구간이다.

- Google cloud vision API를 사용해서 image의 label을 예측
- 생성된 label과 alt-text와 어간(stem)을 비교한뒤 겹치지 않으면 제거
Text Transformation with Hypernymization
pipeline의 마지막 과정으로 image caption model의 학습 난이도를 낮추기 위해 실행하는 단계이다. 모든 필터를 거치고 남은 <image,caption> 쌍의 named entity들을 상위어(hypernym)으로 변환하거나 제거하는 구간이다.
- 고유명사, 숫자, 단위 제거
- 날짜 기간 전치사 기반의 위치 (e.g.,"in Los Angeles") 제거
- knowledge-graph를 이용해 named entity를 상위어로 교체
- 위 과정을 거쳐 동일한 단어가 나오면 복수형으로 변경 (actor and actor -> actors)
Conceptual Captions Quality
아래 표는 해당 pipeline을 통해 생성된 Conceptual Captions 데이터에 대해 사람이 평가한 결과다. 점수는 3점 만점이며 2+(good 이상)인 데이터는 전체 데이터중 90% 이상으로 높은 퀄리티의 image caption dataset이다.
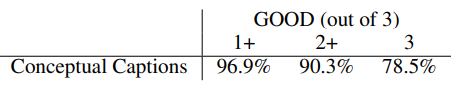
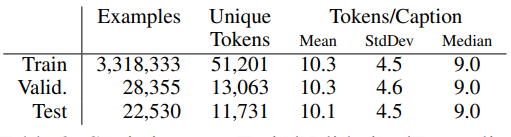
4. Image Captioning model
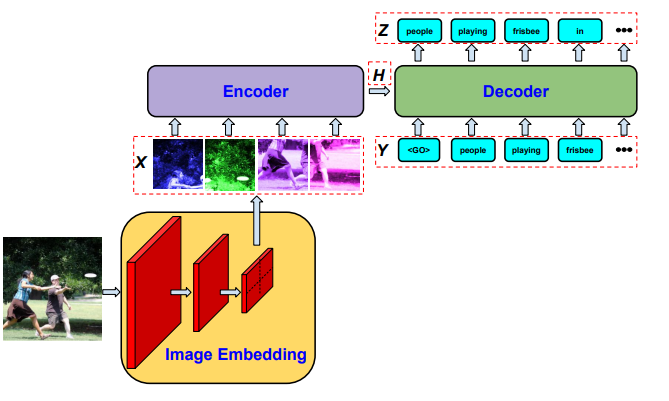
위 그림은 해당 논문에서 사용하는 model architecture이다. 해당 model 구조에는 세가지요소가 존재한다.
- CNN: 전처리된 이미지를 취하고 이미지 임베딩 벡터를 출력
- Encoder: image embedding을 tensor ()로 인코딩한다.
- Decoder: 각 time step 마다 를 출력한다
, 는 time step 에서 까지의 출력 시퀀스
해당 논문에서는 Encoder,Decoder의 arichitecture를 RNN 기반, transformer 기반 총 두게의 model을 사용해 두 model간 성능을 비교함. image Embedding을 위해서는 두 model 모델 모두 CNN모델인 Inception-ResNet-v2을 사용
4.1 RNN-based Models
RNN 기반의 모델은 2015년도에 발표된 Show-and-Tell 모델과 유사하다. show-and-tell model은 하나의 image embedding을 추출해서 decoder의 첫번째 RNN cell의 입력으로 사용한다. 본 논문에서는 image embedding을 바로 decoder의 입력으로 사용하는 것이 아니라 encoder RNN cell의 입력으로 사용한 뒤 encoder의 출력 결과를 decoder의 입력으로 사용한다.
또한 본논문에서는 전체 이미지를 하나의 embedding (1x1)으로 사용하는 기법과 이미지를 8x8로 분할하여 각 분할에 대해 image embedding을 추출하여 64개의 embedding을 사용하는 기법 모두 시도한다.
4.2 Transformer Model
transformer 기반의 model은 RNN기반 model에서 encoder와 decoder가 transformer 구조로 바뀐것 이외에 다른 점이 없다.
5. Experimental Results
Conceptual Caption dataset이 image caption model 학습에 미치는 영향을 평가하기 위해, Conceptual Caption dataset에서 학습된 모델과, COCO dataset에서 학습된 모델을 비교한다.
5.1 Dataset Detail
COCO Image Captions
Conceptual Captions
5.2 Experimental Setup
Image Preprocessing
입력 이미지에 임의의 비율을 사용해 distortion, cropping 기법을 적용
Encoder-Decoder
생략
Text Handling
학습시 caption의 최대 token 개수를 15개로 설정
Optimization
Inference
beam-search 사용
5.3 Qualitative Results

COCO-trained model VS Conceptual-trained model
COCO dataset으로 학습된 모델과 Conceptual Caption dataset으로 학습된 모델들은 다음과 같은 차이가 있는것을 관찰했다.
-
- 이미지에 존재하는 entity에 적합한 단어를 생성하는 능력이 차이남
위 결과에서 제일 왼쪽 이미지를 보면 COCO-trained model의 경우 이미지에 등장하는 사람들을 "a group of men"으로 표현했지만 conceptual-trained model은 "graduates"라는 더 적합한 용어를 생성했다.
- 이미지에 존재하는 entity에 적합한 단어를 생성하는 능력이 차이남
-
- COCO-trained model에서 hallucination이 관찰됨
Conceptual-trained model에서 hallucination 문제가 관찰 되지 않는 반면, COCO-trained model은 첫번째 이미지에서 "front of building", 두번째 이미지에서 "a clock and two doors" 등과 같은 이미지에 등장하지 않는 객체를 표현하는 것을 볼수 있다.
본 논문에서는 이러한 문제가 생기는 이유가 COCO-dataset의 높은 상관관계 때문이라고 주장(e.g. buliding이 존재하면 앞에는 단체가 있다.)
- COCO-trained model에서 hallucination이 관찰됨
-
- 다양한 이미지 타입
마지막 이미지에 대한 결과를 보면 COCO-trained model의 경우 학습시 보지 못했던 cartoon 이미지에 대해 hallucination 문제가 많은 반면 Conceptual-trained model은 hallucination 문제가 보이지 않음
- 다양한 이미지 타입
5.4 Quantitative Results
Flickr 1k Test에 대한 예측 결과를 전문 평가자들이 평가한 점수이며. 평가자는 <image, caption>을 받으면 image에 대한 caption을 모델이 잘 예측했는지 못했는 지를 평가한다.
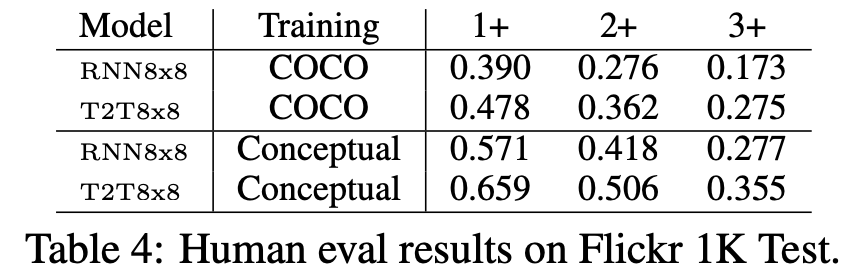
해당 표를 보면 인간이 평가하기에 전반적으로 conceptual-trained model이 더 높은 성능을 보인다는 것을 볼 수 있다.
5.4.2 Automatic Evaluation Results
-
COCO C40 Test data에 대한 평가 지표
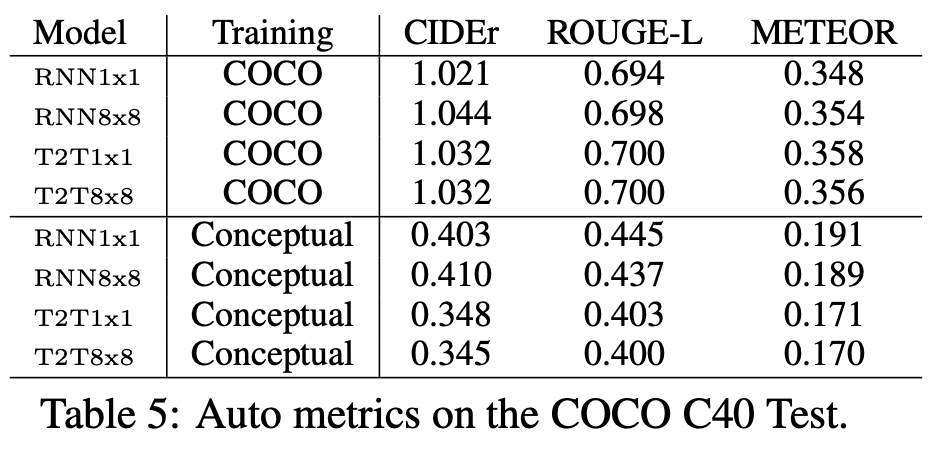
-
Conceptual Caption test set에 대한 평가지표
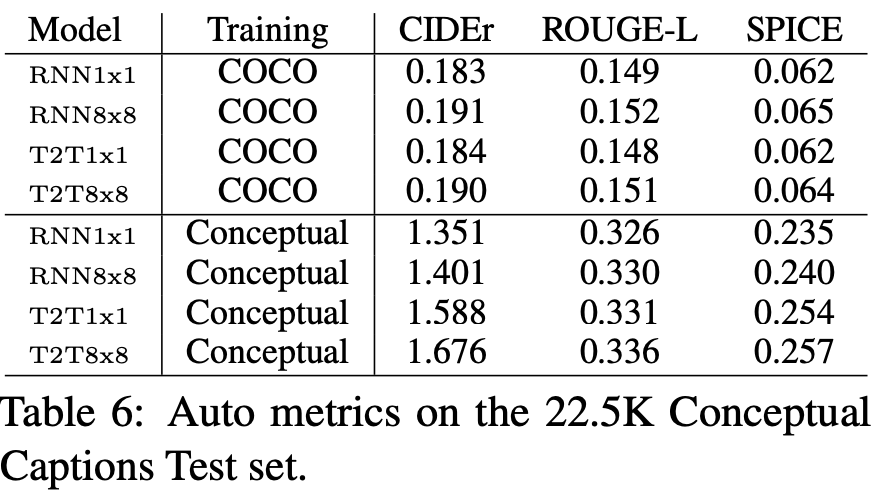
-
Flickr 1k Test에 대한 평가지표
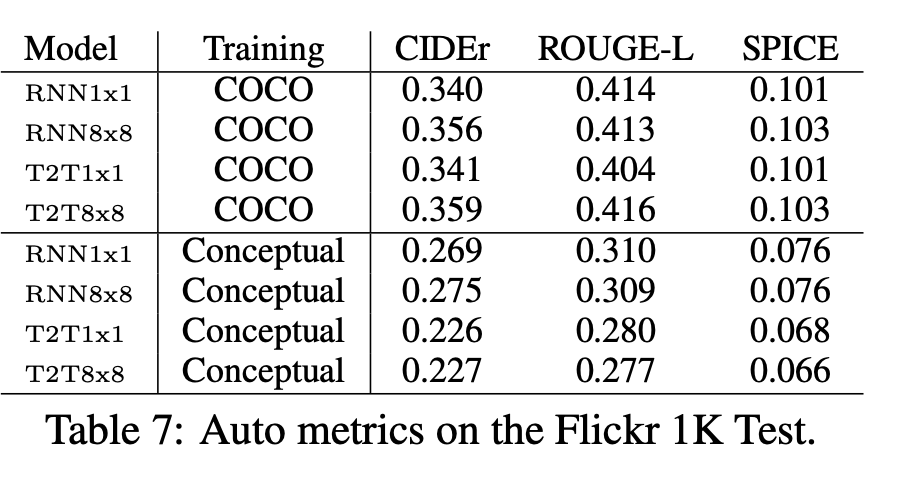
사람이 평가한 결과와 달리 자동 평가지표 결과는 전반적으로 COCO-trained model이 더 높은 것을 볼 수 있다. 본 논문의 저자는 인간이 분명히 평가를 더 잘하는 데 이러한 결과가 보이는 까닭은 자동 평가 방식은 hallucination에 대해 페널티를 적게 주기 때문이라고 주장했다.
6. Conclusions
