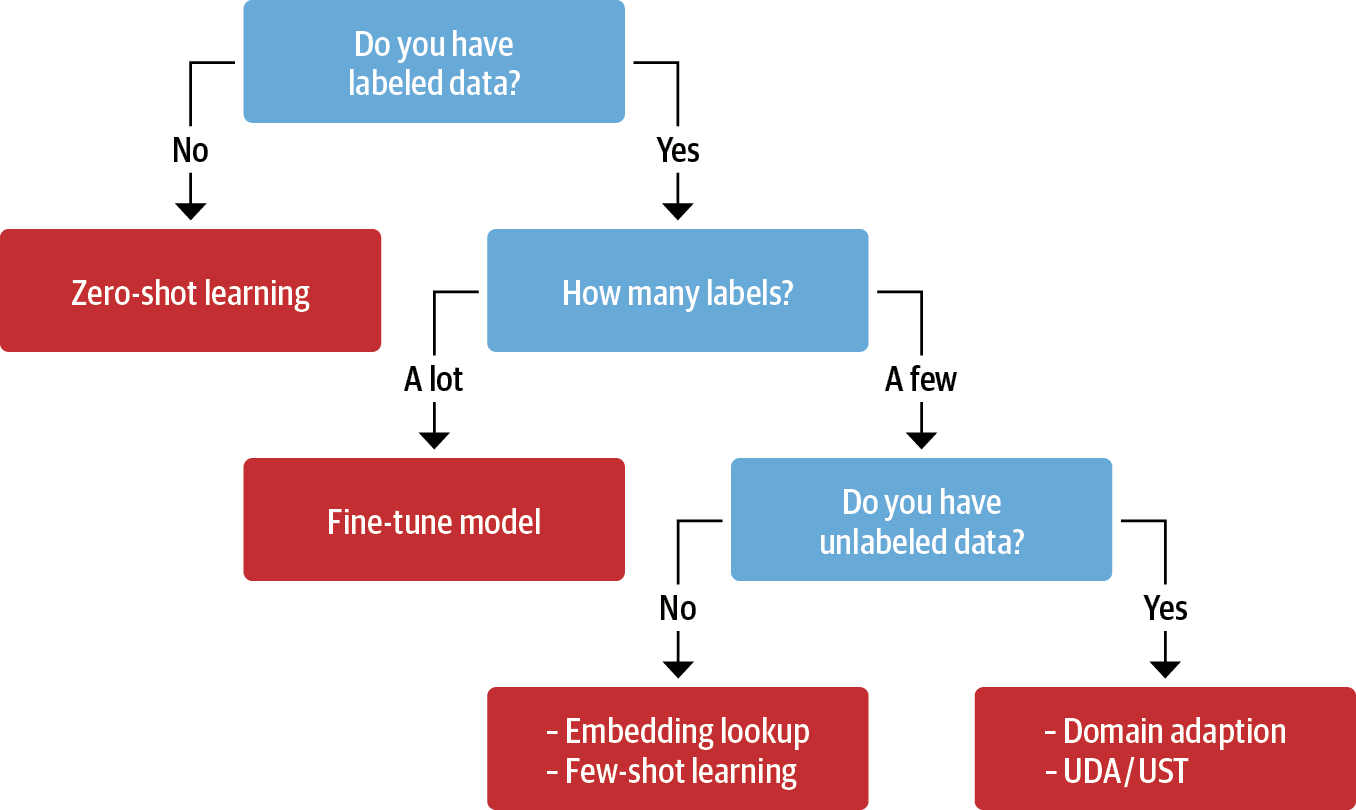
이번 챕터를 통해 아래 기법들과 같이 레이블링된 데이터가 적거나 없을 때 때 사용하는 기법들을 활용해 깃허브 이슈 태그를 예측하는 다중 레이블 텍스트 분류 모델을 만들어 보자.
- zero-shot learning
- few-shot learning
- Domain adaption
- UDA/UST
1. 깃허브 이슈 태거 만들기

깃허브 이슈 태거를 만들기 전에 hugging face의 transformers repository 이슈 페이지를 보면 그림과 같이 제목, 설명, 이슈의 태그의 정보를 담고있다. 이러한 정보를 이용해 이슈의 제목과 설명이 주어지면 한개 이상의 태그를 예측하는 다중 레이블 텍스트 분류 모델을 만들어보자.
1.1 데이터 준비
- 데이터 다운로드
transformers repository 이슈페이지의 정보를 다운받으면 거의 10,000개의 이슈가 존재한다.
import pandas as pd
dataset_url = "https://git.io/nlp-with-transformers"
df_issues = pd.read_json(dataset_url, lines=True)
print(f"데이터프레임 크기: {df_issues.shape}")데이터프레임 크기: (9930, 26)- 불필요한 데이터 제거
해당 정보에는 모델을 학습하기에 불필요한 정보(url, 유저 id 등)가 있으므로 학습에 필요한 제목과 내용, 태그(target label)의 정보만 남긴다.
df_issues["labels"] = (df_issues["labels"]
.apply(lambda x: [meta["name"] for meta in x]))-
EDA
각 행의 태그의 분포를 확인하면 대부분의 이슈는 레이블(태그)이 존재하지 않으며 대부분 하나 이하이다.
df_issues["labels"].apply(lambda x: len(x)).value_counts().to_frame().Tindex 0 1 2 3 4 5 labels 6440 3057 305 100 25 3 df_counts = df_issues["labels"].explode().value_counts().to_frame() print(f"레이블 개수: {len(df_counts)}") df_counts.head(8).T레이블 개수: 65index wontfix model card Core: Tokenization New model Core: Modeling Help wanted Good First Issue Usage labels 2284 649 106 98 64 52 50 46 해당 데이터셋에는 고유한 레이블이 65개 있고 레이블(태그)의 분포가 불균형하기 때문에 분류작업에 어려움이 있어 아래와 같이 데이터 필터링을 진행할 것이다.
-데이터 필터링
분류작업을 쉽게 만들기 위해 데이터셋을 필터링해 앞으로 다룰 레이블만 남긴다.
label_map = {"Core: Tokenization": "tokenization",
"New model": "new model",
"Core: Modeling": "model training",
"Usage": "usage",
"Core: Pipeline": "pipeline",
"TensorFlow": "tensorflow or tf",
"PyTorch": "pytorch",
"Examples": "examples",
"Documentation": "documentation"}
def filter_labels(x):
return [label_map[label] for label in x if label in label_map]
df_issues["labels"] = df_issues["labels"].apply(filter_labels)
all_labels = list(label_map.values())| index | tokenization | new model | model training | usage | pipeline | tensorflow or tf | pytorch | documentation | examples |
|---|---|---|---|---|---|---|---|---|---|
| labels | 106 | 98 | 64 | 46 | 42 | 41 | 37 | 28 | 24 |
데이터셋 준비를 마쳤으니 해당 데이터셋을 이용해 다중레이블분류에서의 레이블 부족 문제를 다뤄보자.
2. 레이블 부족 문제 다루기
2.1 레이블링된 데이터가 없는 경우
레이블링 된 데이터가 전혀 없는 경우에는 zero-shot classification을 사용한다.
2.1.1 자연어 추론 모델
이 책에서는 zero-shot classification을 위해 자연어 추론 (Natural Language Inference) 모델을 사용한다.
자연어 추론:
전제조건 하에 가설이 주어질 때 전제 조건과 일치, 중립, 모순인지 분류하는 task
전제 가설 레이블 His favourite color is blue He is into heavy metal music neutral She finds the joke hilarious She thinks the joke is not funny at all contradiction The house was recently The house is new entailment
2.1.2 적용 방법
자연어 추론 모델을 깃허브 이슈 태거에 적용하기 위해 이슈의 내용과 제목을 전제로 사용해 다음과 같은 가설을 만드는 것이다. {label}에는 이전에 필터링한 태그 8개가 들어간다.
"This example is about {label}"
2.1.3 코드 구현
#모델 불러오기
from transformers import pipeline
pipe = pipeline("zero-shot-classification", device = 0)
#추론
sample = ds["train"][0]
print(f"레이블: {sample['labels']}")
output = pipe(sample["text"], all_labels, multi_label = True)#다중레이블 분류를 위해 multi_label = True
print(output["sequence"][:400])
print("\n 예측:")
#결과 출력
for label, score in zip(output["labels"],output["scores"]):
print(f"{label}, {score:.2f}")레이블: ['new model']
Add new CANINE model
# 🌟 New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o
tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the
title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural
modeling, yet nearly all commonly-used models still require an explicit tokeni
예측:
new model, 0.98
tensorflow or tf, 0.37
examples, 0.34
usage, 0.30
pytorch, 0.25
documentation, 0.25
model training, 0.24
tokenization, 0.17
pipeline, 0.162.2 레이블링 된 데이터가 적은 경우
2.2.1 Data augmentation
데이터 증식(Data augmentation)은 갖고 있는 데이터 셋을 여러가지 방법으로 늘리는 기법이다. 텍스트 데이터에 경우 단어의 순서만 바뀌어도 의미가 크게 달라지기 때문에 augmentation이 까다롭다.
일반적으로 사용하는 두가지이다.
Back Translation

원본 언어로 된 텍스트를 기계 번역을 사용해 다른 언어로 번역한다. 그 다음 번역된 언어를 다시 원본 언어로 번역한다.
token perturbations(토큰 섞기)
훈련 세트의 한 텍스트에서 동의어 교체, 단어추가, 교환, 삭제 같은 간단한 변환을 임의로 선택해 수행
코드
from transformers import set_seed
import nlpaug.augmenter.word as naw
set_seed(3)
aug = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased",
device="cpu", action="substitute")
text = "Transformers are the most popular toys"
print(f"원본 텍스트: {text}")
print(f"증식된 텍스트: {aug.augment(text)}")2.3 레이블링되지 않은 데이터 활용
모델을 학습할 때 양질의 레이블링 된 데이터를 대량으로 구하는 것이 좋지만, 그렇다고 해서 레이블링되지 않은 데이터가 쓸모 없는 것은 아니다.
아래 세 가지 기법을 이용해 레이블링 되지 않은 데이터를 활용할 수 있다
domain adaption(도메인 적응)
하나의 도메인의 데이터에 대해 훈련된 모델을 다른 관련 도메인의 데이터에 대해 잘 수행하기 위해 적응시키는 과정을 의미한다.
이 책에서는 도메인 적응을 위해 masked language modeling으로 사전 학습된 BERT 모델을 사용해 레이블링이 없는 데이터셋에서 fine tune을 진행했다.
-
데이터 토큰화: return_special_tokens_mask=True 로 마스킹 데이터 얻기
def tokenize(batch): return tokenizer(batch["text"], truncation=True, max_length=128, return_special_tokens_mask=True) ds_mlm = ds.map(tokenize, batched=True) ds_mlm = ds_mlm.remove_columns(["labels", "text", "label_ids"]) -
fine tunning
from transformers import AutoModelForMaskedLM training_args = TrainingArguments( output_dir = f"{model_ckpt}-issues-128", per_device_train_batch_size=32, logging_strategy="epoch", evaluation_strategy="epoch", save_strategy="no", num_train_epochs=16, push_to_hub=True, log_level="error", report_to="none") trainer = Trainer( model=AutoModelForMaskedLM.from_pretrained("bert-base-uncased"), tokenizer=tokenizer, args=training_args, data_collator=data_collator, train_dataset=ds_mlm["unsup"], #ds_mlm["unsup"]: 레이블(토큰)이 없는 데이터 eval_dataset=ds_mlm["train"]) trainer.train()
Unsupervised data augmentation(비지도 데이터 증식)

UDA는 Label 데이터와 unlabeled 데이터를 함께 학습에 사용하는 방법이다. label 데이터를 활용하여 Supervised loss를 구성하고 unlabeled 데이터를 이용해 consistency loss를 구성한다.
이 두개의 Loss를 합쳐서 final loss를 구성하고 학습에 사용한다.
-
Supervised Loss
일반적인 분류 학습에 사용하는 cross_entropy loss로 labeled 데이터의 와 라벨 가 있으면 쉽게 구성할 수 있다.
-
Consistency Loss
unlabeled 데이터의 문장 와 에 augmentation을 적용한 을 분류 모델에 넣어 두 개의 확률 분포를 추출한 뒤 두 확률분포의 차이인 KL-Divergence를 계산하여 consistency loss로 활용한다.
uncertainty-aware self-training(불확실성 인지 자기훈련)
레이블링된 데이터에서 teacher모델을 학습한다. 학습한 teacher 모델을 사용해 레이블링 되지 않은 데이터에서 pseudo-label을 만들고 teacher가 만든 pseudo-label을 이용해 student를 학습한다.

