구축한 기출 데이터 활용하기
data.sql 사용
이전에 구축했던 data.sql을 src/main/resources에 복사 붙여넣기 합니다. 그러면 스프링 부트가 자동으로 로딩해줍니다.
단, properties 파일에 다음을 추가해주어야 합니다.
spring.jpa.defer-datasource-initialization=true
spring.sql.init.mode=always테스트용 properties 구분
모든 테스트용 properties에 위 코드를 추가할 필요는 사실 없습니다.
왜냐하면 기출 데이터 필요 없이 단위 테스트를 하는 코드도 있고, 기출 데이터가 필요한 테스트 코드 역시 있기 때문입니다.
따라서 둘을 구분하기 위해 properties를 두 개로 나눕니다.
1. application-test.properties
data.sql이 필요 없는 테스트의 경우입니다.
spring.jpa.hibernate.ddl-auto=create-drop
spring.jpa.defer-datasource-initialization=false
spring.sql.init.mode=never2. application-test-with-data.properties
spring.jpa.defer-datasource-initialization=true
spring.jpa.hibernate.ddl-auto=create-drop
spring.sql.init.mode=alwaysjoin과 fetch join 구분하기
SQL 쿼리 짜기
먼저 sql 쿼리입니다.
두 테이블을 조인해서 기출 질문의 모범 답안을 조회합니다.
select q.interview_question_id, q.model_answer_content from question_metadata q
inner join interview_question i
on q.interview_question_id=i.interview_question_id
where i.interview_question_id in (2,5,6,7,10);Querydsl로 옮기기
이 sql 쿼리를 QueryDSL로 옮기면 다음과 같습니다.
얻어낸 데이터는 편의를 위해 DTO로 만듭니다.
@Override
public List<ModelAnswerDTO> findModelAnswersOfQuestions(List<Integer> interviewQuestionIds) {
return jpaQueryFactory
.select(Projections.constructor(
ModelAnswerDTO.class, questionMetaData.interviewQuestion.id,
questionMetaData.modelAnswerContent))
.from(questionMetaData)
.innerJoin(interviewQuestion)
.on(questionMetaData.interviewQuestion.eq(interviewQuestion))
.where(interviewQuestion.id.in(interviewQuestionIds))
.fetch();
}n+1 문제가 발생하는 지 예측하기
이 메서드의 결과로 얻어낸 DTO는 연관 관계가 있는 엔티티를 참조하지 않습니다.
따라서 n+1 문제를 염려할 필요가 없습니다.
그리고 연관 엔티티인 interviewQuestion은 함께 영속화할 필요가 없으므로 fetchJoin()이 아니라 일반 Join()을 활용했습니다.
참고 자료
https://cobbybb.tistory.com/18
랜덤 쿼리
랜덤 쿼리는 면접 질문을 랜덤으로 출제하기 위해 필요합니다.
계층형 구조 랜덤 조회
기술 질문
첫 번째 시도
처음엔 면접 질문 5개와 꼬리 질문 5개를 출제해야 하므로 랜덤으로 5개의 꼬리 질문을 먼저 조회한 다음, 해당 되는 초기 질문 5개를 조회하려 했습니다.
순서가 좀 다른데요.
이유는 클로져 테이블의 구조 때문입니다.
다음과 같이 모든 질문은 자기 자신을 깊이 0으로 갖습니다.
초기 질문은 현재 33번까지의 id를 갖고 있습니다. 나머지는 꼬리 질문입니다.
ancestor : 1 descendant : 1 depth : 0
ancestor : 1 descendant : 34 depth : 1
ancestor : 1 descendant : 35 depth : 1
...
ancestor : 34 descendant : 34 depth : 0
ancestor : 35 descendant : 35 depth : 0다음 쿼리로는 초기 질문과 연관된 꼬리질문을 같이 조회하기 힘듭니다. 왜냐하면 ancestor가 초기 질문 id여야 하는데, ancestor, descendant, depth만으론 초기 질문인지 찾아내기 어렵기 때문입니다.
select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor=1 and qct.depth=1;반대로 꼬리 질문은 찾기 쉽습니다.
ancestor와 descendant가 다르고, depth가 1이면 꼬리 질문을 찾아낼 수 있습니다.
select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor!=qct.descendant and qct.depth=1 and iq.interview_keyword_id=1 order by rand() limit 5;그런데 이렇게 했더니, 꼬리 질문은 뽑아내는데 똑같은 초기 질문을 가리키는 경우가 생겼습니다.
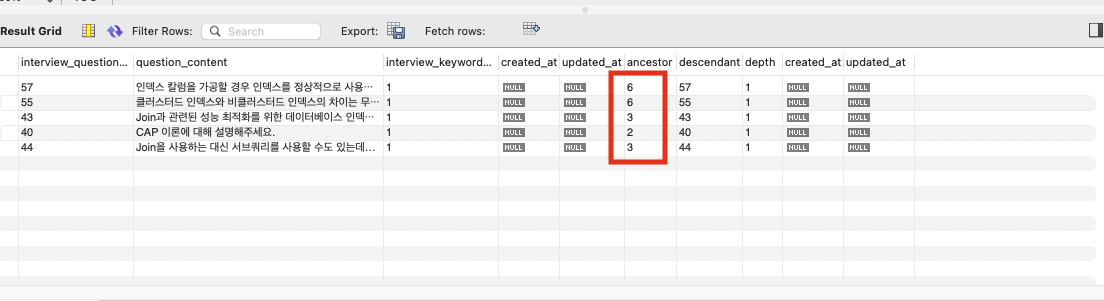
두 번째 시도
쿼리를 이것 저것 실험해보다가, 생각을 바꾸게 되었습니다.
초기 질문을 찾아내는 방법을 알아냈습니다.
다음 쿼리를 활용하면 초기 질문 id만 조회하는 걸 확인할 수 있었습니다.
select distinct qct.ancestor from question_closure_table as qct where qct.ancestor!=qct.descendant and qct.depth=1;아래 쿼리를 했더니 db와 관련된 초기 질문만 받아옵니다.
select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor in (select distinct qct.ancestor from question_closure_table as qct where qct.ancestor!=qct.descendant and qct.depth=1)
and qct.depth=0 and iq.interview_keyword_id=1;세 번째 시도
초기 질문을 랜덤으로 5개 뽑아오는 것은 성공했습니다. 그런데, 각 초기 질문마다 꼬리 질문이 4개씩 있는데 그 중 하나를 랜덤으로 뽑아야 합니다.
어떻게 하면 쿼리 하나로 해결할 수 있을까 고민했지만... 너무 어려웠습니다 ㅠ
그래서 어쩔 수 없이 UNION ALL을 활용하기로 했습니다.
(UNION은 중복 제거를 해서 더 느리고, UNION ALL은 중복 제거를 굳이 하지 않아서 더 빠르다고 합니다.
각 초기 질문마다 꼬리 질문은 중복이 없기 때문에 UNION ALL을 활용했습니다.)
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =1 and qct.depth=1 order by rand() limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =2 and qct.depth=1 order by rand() limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =3 and qct.depth=1 order by rand() limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =5 and qct.depth=1 order by rand() limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =6 and qct.depth=1 order by rand() limit 1);좀 많이 복잡해보이네요 ㅎㅎㅎ;;;
인성 질문
인성 질문은 필수 질문 5개, 랜덤 질문 5개이므로 두 쿼리를 유니온하면 됩니다.
select * from interview_question where interview_keyword_id=7 UNION ALL
(select * from interview_question where interview_keyword_id=11 order by rand() limit 5);rand() 튜닝하기
rand() 구문에 대해서 구글링을 해보니 성능 상 문제가 있다는 것을 발견했습니다.
해당 쿼리를 실행하게 되면 실행 순간에 레코드마다 각각 임의의 값을 할당한 다음, 그 값으로 다시 정렬을 수행합니다. (이 임의의 값은 미리 생성된 데이터가 아니므로 인덱스를 타지 못합니다!!)
즉 1억 건의 데이터가 있으면 1억 건 할당 + 1억 건 정렬이라는 어마어마한 비효율이 발생합니다.
따라서 randId라는 랜덤 조회만을 위한 칼럼을 추가하기로 했습니다. 그리고 이 칼럼에 인덱스를 추가하면 인덱스 스캔을 활용할 수 있게 됩니다.
하지만, 현재 데이터는 300건이 넘지 않기 때문에 대량의 데이터에서 극소량 조회하는 인덱스는 크게 효율적이지 않습니다.
그러므로 데이터 베이스 확장성을 위해 randId를 추가하되, 아직 인덱스는 효율적이지 않아 추가하진 않았습니다.
쿼리로는 테이블을 변경하고 전부 랜덤 id를 추가합니다.
ALTER TABLE interview_question ADD column rand_id INT NOT NULL;
update interview_question set rand_id=floor((rand()*100000000));기술 질문으로 튜닝 시도
다음과 같이 쿼리를 변경했습니다.
초기 질문을 5개 랜덤으로 얻어오는 쿼리
select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor in (select distinct qct.ancestor from question_closure_table as qct where qct.ancestor!=qct.descendant and qct.depth=1)
and qct.depth=0 and iq.interview_keyword_id=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 5;
초기 질문 5개에 대해 꼬리 질문을 각각 1개씩 얻어오는 쿼리
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =1 and qct.depth=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =2 and qct.depth=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =3 and qct.depth=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =5 and qct.depth=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 1)
UNION ALL
(select * from interview_question as iq
join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor =6 and qct.depth=1 and iq.rand_id>=floor((rand()*100000000)) order by iq.rand_id limit 1);처음엔 잘 작동하는 것 같았습니다만... 몇 번 반복 시행하니 5개를 조회하는 게 아니라 3개 또는 4개를 조회하는 경우가 발생했습니다!!
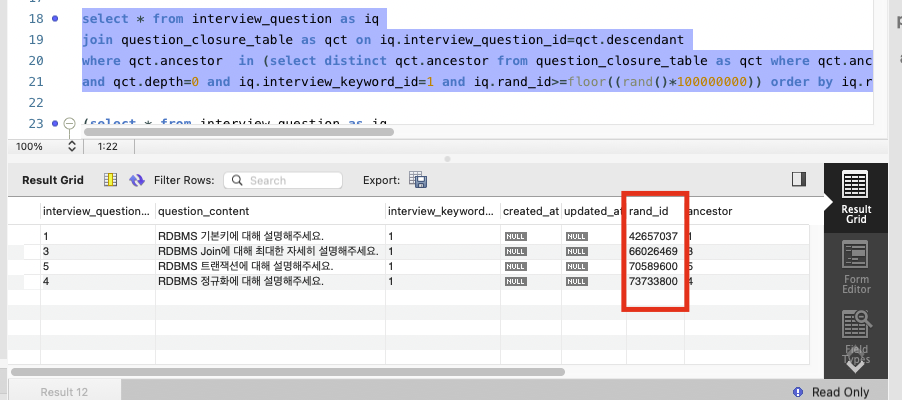
곰곰히 생각해보니 다음 구절이 문제인 것 같았습니다.
where iq.rand_id>=floor((rand()*100000000)) 현재 데이터가 300건도 안되기 때문에, rand() x 100000000 은 너무나 큰 분포를 갖게 됩니다... 따라서 부등호에 걸리지 않는 경우가 많은 것 같습니다.
그렇다고 rand() x 100 처럼 범위를 작게 해도 반드시 5개를 조회하진 않았습니다.
데이터 자체가 적다보니 100으로 줄여도 부등호에 걸리지 않는 것이 많은 것 같습니다.
그리고 아예 rand() x 5로 줄여볼까도 생각했었는데요. 그런데 그렇게 하면 >= 이기 때문에 작은 randId를 가진 질문일수록 랜덤으로 조회될 확률이 낮아집니다. 불공평한 랜덤인 것이죠.
결론
- 대규모 확장성 설계를 위해 인덱스를 사용할 수 있도록 randId를 미리 설정하였습니다.
- 그런데 현재 시점에선 데이터 자체가 너무 적어 rand() 튜닝 방식으로는 조회 갯수가 부족한 경우가 발생했습니다.
- 그래서 randId는 미리 만들어 놓되, 데이터가 현저히 적은 현재 상황에서는 기존 rand() 방식을 활용하기로 했습니다.
참고 자료
https://leezzangmin.tistory.com/28
https://blog.naver.com/sinjoker/221524576602
https://annahxxl.tistory.com/5
