문제 상황
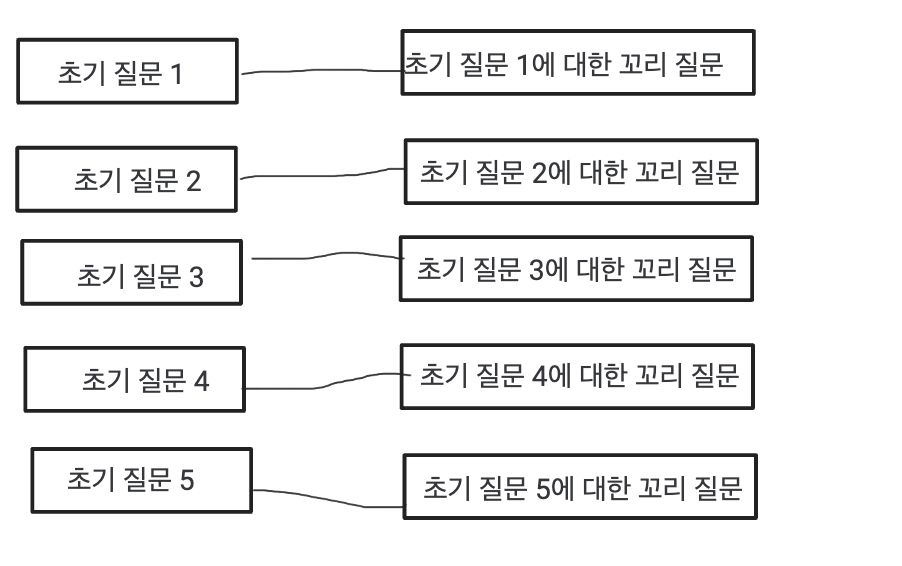
얻고자 하는 결과는 "초기 질문 5개를 받아오고, 각 질문에 대해 꼬리질문을 랜덤으로 1개씩 가져온다." 입니다.
rand() 쿼리 튜닝은 현재 표본 수가 너무 적은 관계로 효과가 크지 않아 적용하지 않았습니다.
그런데 코드 퀄리티에 문제가 생겼습니다.
리포지토리
먼저 리포지토리 쿼리입니다.
각 면접 질문마다 랜덤 조회를 해야하기 때문에 UNION ALL을 활용했습니다.
하지만 문제가 있죠. 메서드 파라미터입니다. 이 메서드는 특히나 호출하는 곳의 코드를 지저분하게 만들고 있습니다.
@Query(value = ""
+ "(SELECT iq.interview_question_id,iq.question_content,iq.interview_keyword_id, iq.created_at, iq.updated_at, iq.rand_id FROM interview_question AS iq "
+ "JOIN question_closure_table AS qct ON iq.interview_question_id = qct.descendant "
+ "WHERE qct.ancestor = :ancestor_id1 AND qct.depth = 1 ORDER BY rand() LIMIT 1) "
+ "UNION ALL "
+ "(SELECT iq.interview_question_id,iq.question_content,iq.interview_keyword_id, iq.created_at, iq.updated_at, iq.rand_id FROM interview_question AS iq "
+ "JOIN question_closure_table AS qct ON iq.interview_question_id = qct.descendant "
+ "WHERE qct.ancestor = :ancestor_id2 AND qct.depth = 1 ORDER BY rand() LIMIT 1) "
+ "UNION ALL "
+ "(SELECT iq.interview_question_id,iq.question_content,iq.interview_keyword_id, iq.created_at, iq.updated_at, iq.rand_id FROM interview_question AS iq "
+ "JOIN question_closure_table AS qct ON iq.interview_question_id = qct.descendant "
+ "WHERE qct.ancestor = :ancestor_id3 AND qct.depth = 1 ORDER BY rand() LIMIT 1) "
+ "UNION ALL "
+ "(SELECT iq.interview_question_id,iq.question_content,iq.interview_keyword_id, iq.created_at, iq.updated_at, iq.rand_id FROM interview_question AS iq "
+ "JOIN question_closure_table AS qct ON iq.interview_question_id = qct.descendant "
+ "WHERE qct.ancestor = :ancestor_id4 AND qct.depth = 1 ORDER BY rand() LIMIT 1)"
+ "UNION ALL "
+ "(SELECT iq.interview_question_id,iq.question_content,iq.interview_keyword_id, iq.created_at, iq.updated_at, iq.rand_id FROM interview_question AS iq "
+ "JOIN question_closure_table AS qct ON iq.interview_question_id = qct.descendant "
+ "WHERE qct.ancestor = :ancestor_id5 AND qct.depth = 1 ORDER BY rand() LIMIT 1)", nativeQuery = true)
List<InterviewQuestion> findFollowupQuestionsForAncestors(@Param("ancestor_id1") Integer ancestorId1, @Param("ancestor_id2") Integer ancestorId2,
@Param("ancestor_id3") Integer ancestorId3, @Param("ancestor_id4") Integer ancestorId4, @Param("ancestor_id5") Integer ancestorId5);서비스
위 리포지토리 메서드를 사용하는 서비스 코드의 일부입니다.
@Service
public class InterviewQuestionService {
private List<InterviewQuestion> giveFollowupQuestionsAboutInitialQuestions(
List<InterviewQuestion> initialTechQuestions) {
List<InterviewQuestion> followupQuestions =
this.interviewQuestionRepository.findFollowupQuestionsForAncestors(
initialTechQuestions.get(0).getId(), initialTechQuestions.get(1).getId(),
initialTechQuestions.get(2).getId(), initialTechQuestions.get(3).getId(),
initialTechQuestions.get(4).getId());
if (followupQuestions.size() != QUESTION_SIZE) {
throw new InvalidQuestionCountException(
"Followup questions size must be equal to " + QUESTION_SIZE);
}
return followupQuestions;
}
}보시면 List의 인덱스를 일일이 주입해서 호출하고 있는데요.
다음과 같은 문제점이 있습니다.
(1) 0,1,2,3,4 라는 숫자를 프로그래머가 직접 일일이 신경써야 합니다. 매직 넘버와 같은 느낌도 납니다. 다른 개발자가 본다면 왜 이렇게 보내는지, 그리고 숫자는 왜 0,1,2,3,4인지 의아할 거 같습니다.
(2) 0,1,2,3,4를 넣는 것을 실수할 수 있습니다.
(3) 유지보수에 있어서 최악입니다. 만약 초기 질문이 5개가 아니라 8개로 변경해야 한다면, 메서드 파라미터 역시 8개가 필요하게 됩니다. 이 또한 하드 코딩해야 합니다.
선택지
어플리케이션 레벨에서 해결하기
초기 질문을 받아온 다음, 각 질문에 대해 꼬리질문을 가져오는 "도메인 규칙"은 건드리지 않습니다. 왜냐하면 서비스 근간을 흔드는 것이기 때문이죠.
대신 1개씩 랜덤하게 가져오는 것이 아니라 In (...) 구문을 활용하여 해당되는 꼬리질문을 모조리 조회한 다음, 자바에서 랜덤을 활용하여 필터링하는 방식입니다.
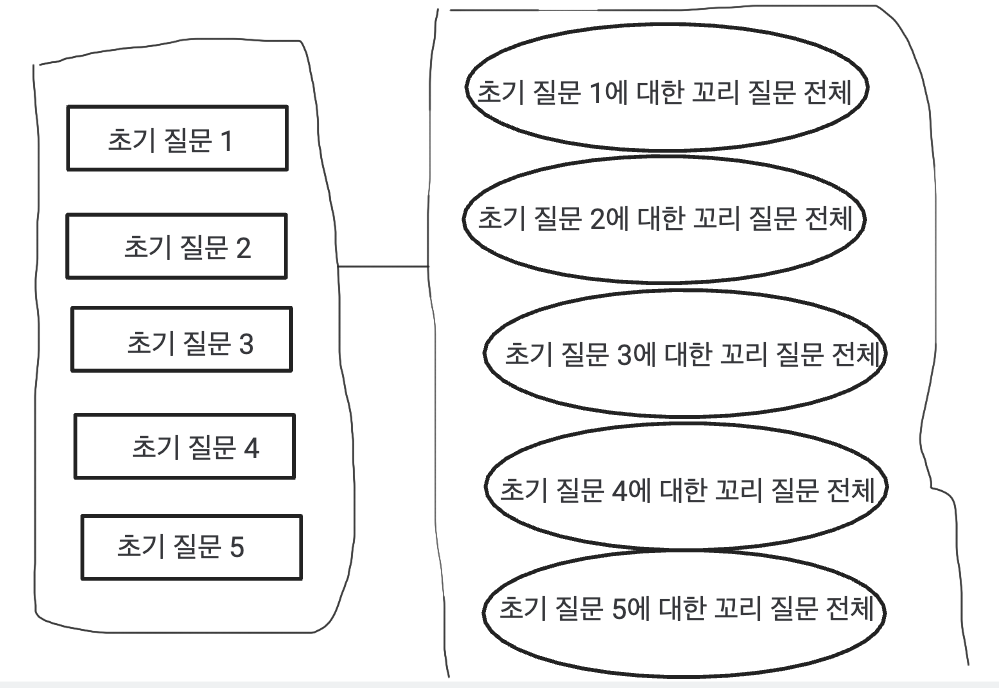
select * from interview_question as iq join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor in (1,2,3,5,6) and qct.depth=1;위와 같이 In 을 활용해서 각각 조회하는 게 아니라 그냥 다 조회하는 방식입니다.
얻어낸 결과들은 ancestor를 활용하여 초기질문이 무엇인지 알아낼 수 있으므로 자바 어플리케이션 단에서 랜덤하게 골라내면 됩니다.
장점
(1) 쿼리가 단순해집니다.
(2) 쿼리가 단순해지므로 native query를 사용하지 않고 querydsl을 사용할 수 있습니다.
(3) 메서드 파라미터가 단순해집니다.
(4) h2를 활용한 테스트에서 편리합니다. 왜냐하면 모든 DB에서 지원하는 쿼리만 존재하기 때문입니다.
단점
(1) 전체를 조회해야 합니다. 그 중에서 랜덤하게 골라내므로 필요없는 것들을 조회하는 것과 마찬가지입니다. 이는 메모리 낭비라 할 수 있습니다.
(2) 현재 질문은 200개밖에 되지 않습니다. 하지만 10만개가 넘어가면 많은 메모리 낭비가 생길뿐만 아니라 조회 속도도 느려질 것입니다.
스토어드 프로시져
스토어드 프로시져를 활용하면 RDBMS단에서도 프로그래밍을 할 수 있게 됩니다. 그런데 문제가 있습니다.
조사를 해보니, H2 인메모리 DB에서는 스토어드 프로시져를 제공하지 않는다고 합니다.
이는 테스트를 할 때, 해당 메서드는 H2가 아니라 Mysql을 직접 연결해서 해야하는 것입니다...
따라서 테스트하기 번거로워지고, RDBMS 벤더가 달라지면 스토어드 프로시져 역시 바뀌어야 하기 때문에 유지보수가 좋지 않을거 같아 폐기했습니다.
비동기 db call 이후의 취합
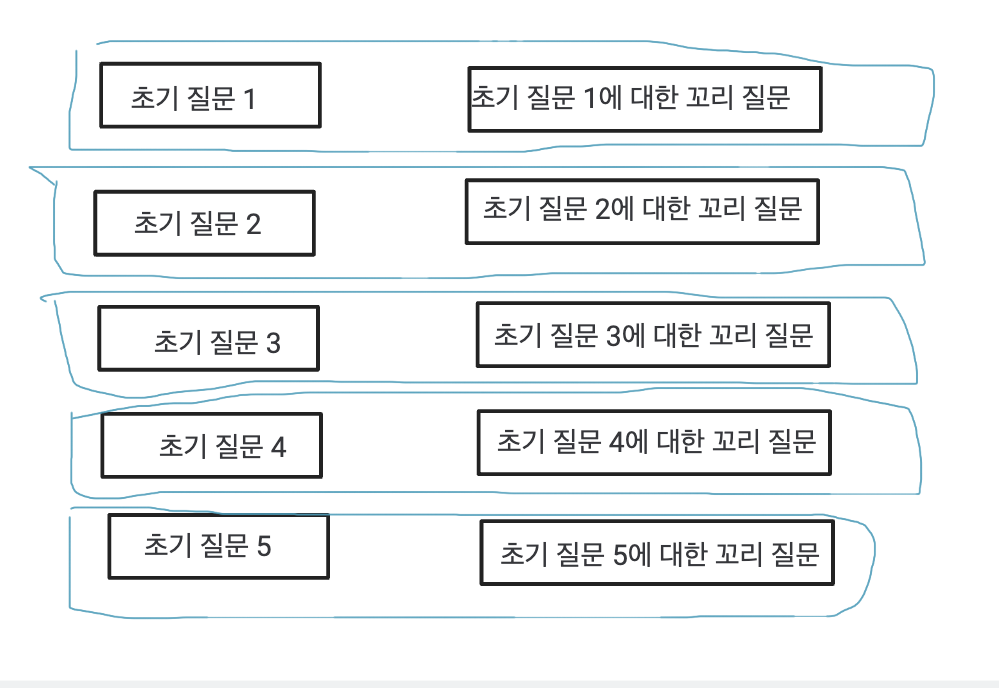
다음 sql을 비동기로 호출한 다음 취합하는 방식입니다.
select * from interview_question as iq join question_closure_table as qct on iq.interview_question_id=qct.descendant
where qct.ancestor = 1 and qct.depth=1 order by rand() limit 1;장점
(1) 쿼리가 단순해집니다.
(2) 불필요한 데이터를 조회하지 않으므로 메모리 낭비가 발생하지 않습니다.
단점
(1) 초기 질문이 n개이면 n개에 대한 DB 커넥션이 필요하므로 커넥션 풀을 빠르게 고갈시킵니다.
(2) 비동기 호출 도중에 실패가 발생하면 골치 아파집니다. 예를 들어 5개 조회 해야 하는데 3,4번째가 실패하면 예외 처리를 해줘야 합니다.
결론
어플리케이션 레벨에서 해결하기로 결정했습니다.
이유는 다음과 같습니다.
(1) 스토어드 프로시져는 또다른 유지보수 문제를 낳습니다.
(2) 비동기 DB 호출은 복잡하며 커넥션 풀을 빠르게 고갈시킵니다. 그리고 비동기를 사용하는 이유는 대부분 응답 시간 개선을 위해서인데, 기존 쿼리랑 비교했을 때 크게 개선될 것 같지 않습니다. (union all로 한 번에 조회하기 때문입니다.)
(3) 현재 질문은 200개이며, 아무리 기술 면접 질문이 늘어나도 전체 1000개를 넘기가 힘들거라고 판단했습니다.
그래도 랜덤으로 뽑는 것 때문에 낭비가 발생하는 것은 사실입니다.
그래서 추후에 Redis 캐싱 같은 것도 연구해봐야 할 것 같습니다.
어떤 영역에서 조회했던 것을 또 DB에서 긁어오는 것보단 캐싱한 것을 조회하는게 더 빠를 거라 예상하기 때문입니다.
결과
리포지토리
In 쿼리로 전부를 조회하는 단순한 쿼리로 변경되었기 때문에 querydsl을 사용할 수 있게 되었습니다.
@Override
public List<FollowupQuestionDTO> findFollowupQuestionsForAncestors(
List<Integer> interviewQuestionIds) {
int DIRECT_FOLLOWUP_QUESTION_DEPTH = 1;
return jpaQueryFactory
.select(Projections.constructor(FollowupQuestionDTO.class, questionClosureTable.ancestor,
interviewQuestion.id, interviewQuestion.questionContent))
.from(interviewQuestion)
.innerJoin(questionClosureTable)
.on(interviewQuestion.id.eq(questionClosureTable.descendant))
.where(questionClosureTable.ancestor.in(interviewQuestionIds)
.and(questionClosureTable.depth.eq(DIRECT_FOLLOWUP_QUESTION_DEPTH)))
.fetch();
}서비스
인덱스를 일일이 지정하는 것이 아닌, Id의 리스트를 파라미터로 넣는 것으로 바꿨습니다. 이제 초기 질문 개수가 미지수 n개여도 됩니다.
단, 모든 관련 꼬리 질문을 조회하는 것 뿐이므로 랜덤으로 1개 씩 뽑은 후, 초기 질문과 매핑하는 로직이 추가적으로 필요합니다.
private List<FollowupQuestionDTO> giveAllFollowupQuestionsAboutInitialQuestions(
List<InterviewQuestion> initialTechQuestions) {
List<Integer> initialTechQuestionIds = initialTechQuestions.stream()
.map(InterviewQuestion::getId).toList();
return this.interviewQuestionRepository.findFollowupQuestionsForAncestors(
initialTechQuestionIds);
}조회한 모든 꼬리 질문에서 각 ancestor마다 1개씩 꼬리질문을 랜덤으로 뽑습니다.
private List<FollowupQuestionDTO> chooseOneRandomFollowupQuestionOfEachInitialQuestion(
List<FollowupQuestionDTO> followupQuestionDTOList) {
Random random = new Random();
// FollowupQuestionDTO의 리스트를 입력 받아서 같은 ancestor를 가진 DTO들을 그룹화한 후,
// 각 그룹에서 랜덤하게 한 개의 DTO를 선택하여 새로운 리스트를 만듭니다.
return followupQuestionDTOList.stream()
.collect(Collectors.groupingBy(FollowupQuestionDTO::getAncestor))
.values().stream().map(group -> group.get(random.nextInt(group.size())))
.collect(Collectors.toList());
}마지막으로 (초기 질문, 꼬리 질문) 쌍으로 매핑합니다.
private List<TechQuestionPairDTO> mapInitialQuestionAndFollowupQuestion(
List<InterviewQuestion> initialTechQuestions,
List<FollowupQuestionDTO> chosenRandomFollowupQuestions) {
if (initialTechQuestions.size() != chosenRandomFollowupQuestions.size()) {
throw new IllegalArgumentException(
"Initial questions size must be equal to chosenRandomFollowupQuestions");
}
// (초기 질문 (id=1), 꼬리 질문 (ancestor=1))과 같이 매핑하기 위해 정렬합니다.
List<InterviewQuestion> sortedInitialQuestions = initialTechQuestions.stream()
.sorted(Comparator.comparing(InterviewQuestion::getId))
.toList();
List<FollowupQuestionDTO> sortedFollowupQuestions = chosenRandomFollowupQuestions.stream()
.sorted(Comparator.comparing(FollowupQuestionDTO::getAncestor))
.toList();
return IntStream.range(0, QUESTION_SIZE)
.mapToObj(
i -> new TechQuestionPairDTO(sortedInitialQuestions.get(i),
sortedFollowupQuestions.get(i)))
.collect(Collectors.toList());
}