
A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN은 PGGAN 구조에서 Style transfer 개념을 적용하여 Generator architecture를 재구성한 논문이다.
[Abstract]
저자들은 Style transfer 문헌에서 차용하여 GAN을 위한 alternative generator architecture을 제안했다. 새로운 architecture는 자동으로 학습되고, 비지도의 높은 수준의 속성(예: 성별, 자세)과 생성된 이미지(예: 주근깨, 머리카락)의 확률적 변화를 분리하고, 직관적이고 통합적인 scale-specific control이 가능하게 한다. 새로운 Generator는 전통적인 distribution quality metrics 측면에서 SOTA를 개선하고, 입증할 수 있는 더 나은 보간 특성을 이끌어내며, variation의 latent factor를 더 잘 구분하한다. interpolation quality와 disentanglement을 정량화하기 위해 모든 Generator architecture에 적용할 수 있는 두 개의 새로운 자동화 방법을 제안한다.
[StyleGAN]
StyleGAN의 아이디어는 마치 화가가 눈동자 색만 다른 색으로 색칠하고, 머리카락 색만 다른 색으로 색칠하고 하는 것 처럼 PGGAN에서도 style들을 변형시키고 싶은데 Generator에 latent vector 가 바로 입력되기 때문에 entangle하게 되어서 불가능하다는 단점이 있었다. 그래서 논문의 저자들은 Style transfer처럼 원하는 style로 수치화 시켜서 GAN에 적용하고자 했다. 그래서 나온 아이디어가 각각 다른 style을 여러 scale에 넣어서 학습 시키는 방법이다.
하지만 latent variable 기반의 생성 모델은 가우시안 분포 형태의 random noise를 입력으로 넣어주는 특징을 갖고 있어 latent space가 entangle하게 된다. 따라서 StyleGAN은 학습 데이터셋이 어떤 분포를 갖고 있을지 모르니, GAN에 을 바로 넣어주지 말고 학습 데이터셋과 비슷한 확률 분포를 갖도록 non-linear하게 mapping을 우선적으로 하고 mapping된 를 이용하면 좀 더 학습하기에 쉽지 않을까? 하는 아이디어로 아래의 그림처럼 Mapping Network을 사용해 mapping된 를 각 scale에 입력으로 넣어서 학습을 시키게 된다.
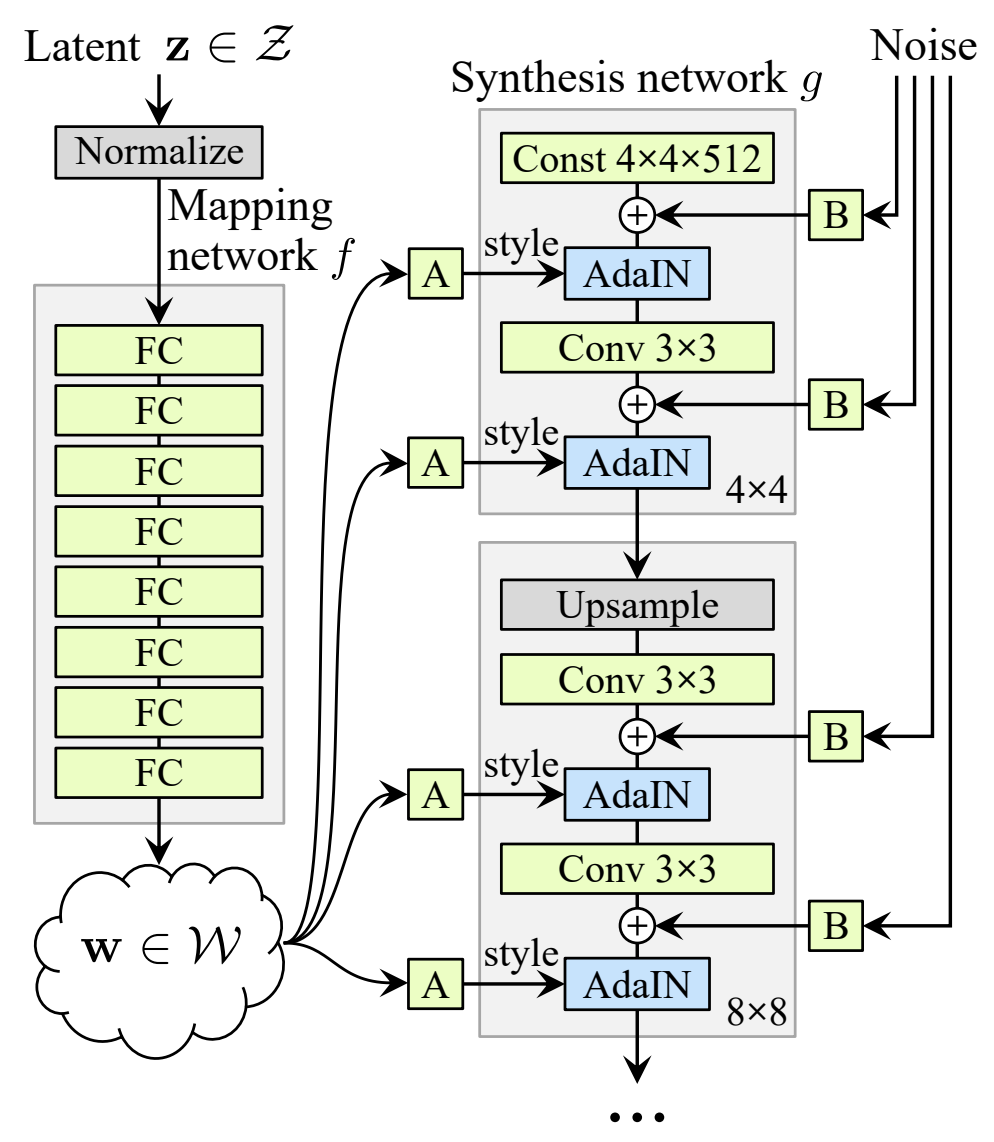
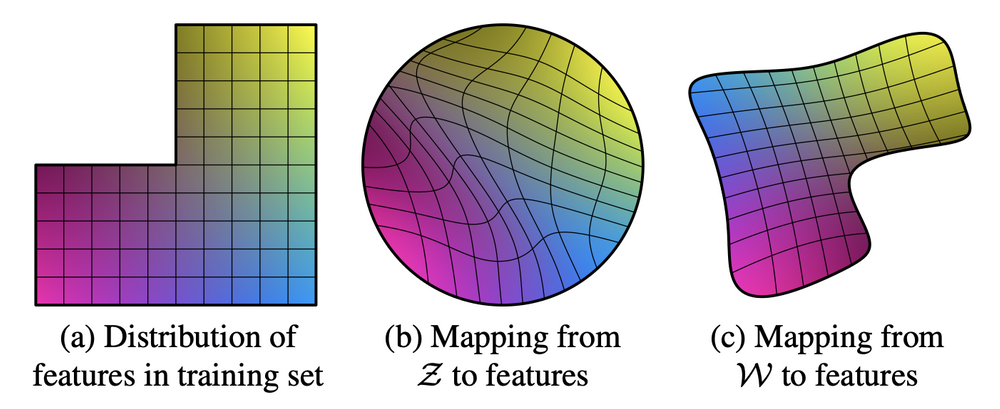
Mapping Network를 통해서 나온 는 정확하지는 않지만 학습 데이터셋의 확률 분포와 비슷한 모양으로 mapping이 된 상태이기 때문에 아래의 그림 (c)처럼 특징이 mapping된 latent space의 가 disentangle하게 된다.
[AdaIN]
AdaIN의 기능을 설명하기에 앞서 기본적인 예로 Neural Network을 한번 살펴보자. Neural Network에서 각 layer를 지나가며 scale, variance의 변화가 생기는 일이 빈번하게 발생하며 이는 학습이 불안정 해지는 현상이 발생한다. 따라서 이를 방지하기 위해 Batch Normalization 방법과 같은 normalization 기법을 각 layer에 사용함으로써 해결하곤 한다.
StyleGAN에서는 Mapping network를 거쳐서 나온 가 latent vector의 style로 각 scale을 담당하는 layer에 입력으로 들어가게 되며, 가 style에 영향을 주면서 동시에 학습이 불안정해지는 것을 방지하기 위해 normalization 해주는 방법을 사용한다.
AdaIN의 수식은 다음과 같다.
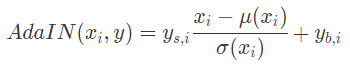
- 라는 linear coefficient를 곱해주고 상수를 더한다.
- 와 는 를 Affine Transformation을 거쳐서 shape을 맞추고 style을 입혀주게 된다.
수식을 보면 표준편차로 나누고 평균으로 뺀 값이니까 random variable을 정규화 시키는 것인데, instance에 대해 normalization 해주는 것이라고 볼 수 있다.
<중간 정리>
- 가 AdaIN을 통해 style을 입힐 때 shape이 맞지 않아 Affine Transformation을 거쳐서 shape을 맞춰준다.
- layer를 거치면 학습이 불안정해지므로 normalizaiton을 각 layer에다 추가를 해주는데 StyleGAN에서는 그 역할을 AdaIN이 한다.
- AdaIN에서 정규화를 할 때마다 한 번에 하나씩만 가 기여하므로 하나의 style이 각각의 scale에서만 영향을 끼칠 수 있도록 분리해주는 효과가 있다. 따라서 본 논문의 저자들은 style을 분리하는 방법으로 AdaIN이 효과적이라고 주장한다.
[Properties of the style-based generator]
1. Style mixing
Single latent 를 이용할 경우 특징
StyleGAN에서 동일한 latent vector 가 Mapping network 를 통해서 나온 하나만 계속 네트워크를 학습하다보면 correlation이 발생하며 학습이 되는 문제가 발생하게 될 수 있다.
<예시>
얼굴 학습 데이터셋 중 대머리인 사람 이미지 데이터들이 있는데, 그 대머리인 사람들이 모두 선글라스를 착용하고 있다면 GAN은 학습 데이터의 분포와 비슷한 분포를 갖도록 학습하다보니 Gnerator는 선글라스 = 대머리 라는 correlation이 발생하여 무조건 대머리인 사람은 선글라스를 착용한 상태로 생성하는 overfitting이 될 가능성이 높다.
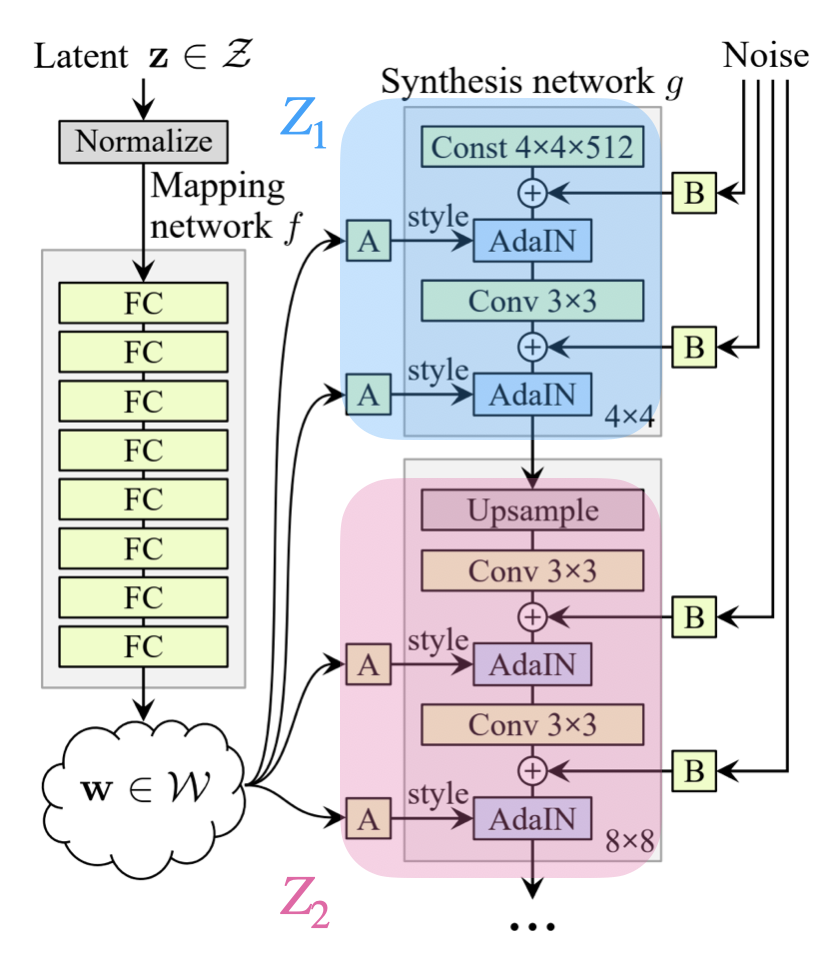
Multi latent 를 이용할 경우 특징
style correlation이 발생하지 않고 학습을 진행하기 위해서는 synthesis network를 학습시킬 때 하나의 latent vector 에서 나온 를 이용해서 학습하는 것이 아니라 latent space에서 뽑은 을 mapping network 에 통과시켜서 을 만든다. 이후 위의 그림과 같이 50:50 비율로 나눠서 각 layer에 적용해도 되고 다른 비율로 상황에 따라 적용하면 된다.
이런 style mixing 방법을 사용하면 다양한 style이 섞여서 synthesis network 학습이 된다. 따라서 Generator를 이용해서 이미지를 생성해 보면 style correlation이 거의 없으며 입력할 때 AdaIN을 통해 입력을 하게 되므로 regularization 효과도 볼 수 있게 된다.
그 결과 아래의 그림처럼 style correlataion 현상을 방지함으로써 각 layer에 해당하는 style들이 잘 구분되어 적용이 되는 것을 볼 수 있다.

2. Perceptual path length
latent space가 disentangle 하다는 것을 정량화하기 위해 본 논문에서는 다음과 같은 두 가지 측정 방법을 제안했다.
- perceptual path length
- linear separability (설명 생략)
latent space에서 아래의 그림처럼 blue point -> red point로 변화를 주면서 생성한 이미지들의 특징(예: 머리 색이 변경됐는지, 없던 점이 생겨났는지)들이 사람이 봤을 때 '어떤 특징들만 변화하였는지'를 잘 구분을 할 수 있는지에 대한 방법을 자동화 시켜서 perceptual path length 라는 개념을 제안했다.
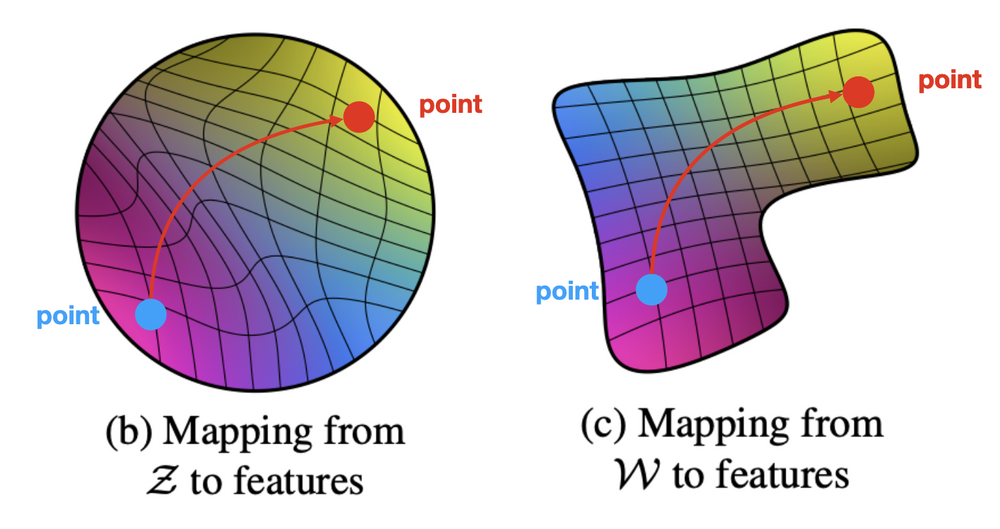
<측정 방법>
지금까지 생성된 이미지들 간의 거리가 얼마나 떨어져 있는지 알아보는 방법으로 L2-distance를 이용했지만, perceptual path length는 이미지들을 잘 구분하도록 학습된 pre-trained model을 이용해서 입력 이미지가 들어오면 그 이미지가 어떤 이미지인지 처리하기 위해 본 논문에서는 VGG16 모델을 사용하고 있다.
perceptual path length는 와 을 pre-trained VGG16에 각각 embedding 시켰을 때 VGG16 내에서 embedding 되는 pairwise image distance를 구하는 방법이다. 만약 에 변화를 주면서 생성되는 이미지 와 의 변화가 크다면 pairwise image distance 값도 커지게 되며 latent space가 entangle하다고 볼 수 있다.
극단적인 예시를 하나 들어보면, 아래의 그림은 학습 데이터셋의 분포를 억지로 끼어맞추기 형식으로 만든 latent space 이다. 그림을 보면 선(line)들이 규칙적이지 않고 불규칙하게 좁았다가 넓었다가 하는 것을 볼 수 있다. 저런 latent space에서 를 변형하면 남자였다가 갑자기 성별이 확 변하는 것처럼 사람이 봐도 많이 변했다는 것을 인지할 수 있을 정도로 이미지가 변하게 된다. 이런 상태를 "latent space가 entangle하다" 라고 말한다.
그런데 본 논문에서는 latent space가 disentangle하게 하기 위해 mapping network 를 통과한 latent space 를 이용하여 모델을 학습하게 된다. 이때 더 disentangle하게 만들기 위해서 style mixing 기법을 사용하게 된다. disentangle한 latent space에서 값을 바꿔주면 각 scale마다 담당하고 있는 특징들만 변하게 된다. 이를 "latent space가 disentangle하다" 라고 말한다.

3. 원하는 부분을 미세하게 변형하기
StyleGAN은 화가들이 미술 작품에서 특정 부분만 리터치하는 것처럼 내려간 머리카락을 살짝 올려줄 수 있다. 마치 인공지능계의 화가가 리터치하는 것과 같은 의미다.
전통적인 Generator는 하나로 입력되기 때문에 미세한 특정 부분만 변경해줄 수 없다는 특징이 있다. 하지만 StyleGAN은 각 해상도마다 style을 담당하는 layer에 mapping network를 거쳐서 나온 를 넣어주는 형식으로 구성되어 있어서 가능하다.
맨 위의 첫 번째 그림을 보면 style을 담당하는 를 AdaIN을 통해 입력해줄 뿐만 아니라 noise가 별도로 입력되는 것을 볼 수 있다. 이는 랜덤하게 noise를 입력시켜주면서 아래 그림과 같이 현재 style에서 화가가 리터치하듯 인공지능이 리터치하는 것처럼 만들어 준다.

[한계점]
StyleGAN의 한계점은 아래의 그림과 같이 물방울 형태의 blob들이 관측된다는 것이다. 이 한계점은 StyleGAN paper에는 나와있지 않고, StyleGAN2에 언급이 되어 있다.

[Conclusion]
High Resolution Image Generation하는 GAN 논문들 중 StyleGAN은 전통적인 방식과 다르게 각 style을 담당하는 layer에 style 를 AdaIN을 통해서 입력해주는 방법으로 학습함으로써 원하는 style로 변형시킬 수 있는 모델이며, 특히 높은 성능 향상을 보여주었다. 또한 latent space가 disentangle하게 되기 위해서 Mapping Network를 사용한 점이 매우 인상 깊다.
[참고 자료]
https://arxiv.org/pdf/1812.04948.pdf
https://blog.promedius.ai/stylegan_1/
https://blog.promedius.ai/stylegan_2/
https://arxiv.org/pdf/1710.10196.pdf
https://sensibilityit.tistory.com/508
