📔설명
DML, TCL, DDL, DCL을 알아보자
🥩DML
DML(Data Manipulation Language) : 테이블에 데이터 입력, 수정, 삭제
=> 데이터의 변경사항을 영구적으로 저장하기 위해선 COMMIT 명령어를 수행해야 함 (단, sql server는 기본적으로 dml 명령어를 auto commit으로 처리
=> 테이블 전체의 데이터를 삭제하는 경우 삭제된 데이터를 로그로 저장하는 DELETE보다, 시스템 부하가 적은 TRUNCATE TABLE 권고 (단, truncate table은 삭제된 데이터의 로그가 없어 rollback 불가능, sql server의 경우 사용자가 임의적으로 트랜잭션 시작 후 truncate table로 데이터 삭제 후 오류 발견 시 rollback 가능)
1. INSERT
단일 행 INSERT 문
단일 행 insert 문 : values 절 포함
=> 한 번에 한 행만 입력
=> into절의 칼럼명과 values절의 값을 서로 1:1 매핑, 칼럼명 기술 순서는 테이블에 정의된 칼럼 순서와 동일할 필요 X, into절에 기술하지 않은 컬럼은 default로 null 입력
=> Primary key 제약 또는 Not null 제약이 지정된 칼럼은 null 허용X로 오류 반환
=> char또는 varchar2 등 문자 유형일 경우 '와 함께 값 입력
=> 숫자 유형일 경우 그냥 숫자만 입력
insert into 테이블명 [(칼럼1, 칼럼2, ...)] values (값1, 값2, ...);INSERT
INTO PLAYER (PLAYER_ID, PLAYER_NAME, TEAM_ID, POSITION, HEIGHT, WEIGHT, BACK_NO)
VALUES ('2002007', '박지성', 'K07', 'MF', 178, 73, 7);
into절의 칼럼명은 생략 가능
=> 테이블에 정의된 칼럼 순서대로 values절에 모든 값들을 빠짐없이 기술해야 함
INSERT INTO PLAYER
VALUES ('2002010','이청용','K07','','BlueDragon','2002','MF','17',NULL, NULL,'1',180,69);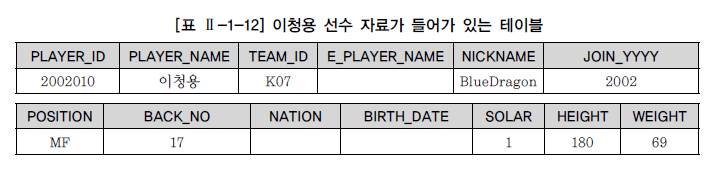
미지의 값은 ''로 표현하거나, Null이라고 명시적으로 표현 가능
values절에 서브쿼리를 사용해 SQL 작성 가능
--현재 사용중인 player_id 최대값에 1을 더한 값 사용
insert into player(player_id, player_name, team_id)
values ((select to_char(max(to_number(player_id))+1) from player,
'홍길동', 'k06');서브 쿼리를 이용한 다중 행 INSERT 문
INSERT문에 서브 쿼리 사용시 서브쿼리의 결과를 테이블에 입력 가능
=> 서브 쿼리 결과가 다중 행이면, 한 번에 여러 건 입력
=> into절의 칼럼명 개수와 서브쿼리의 select 절 칼럼 개수 일치해야 함
insert into 테이블명 [(칼럼1, 칼럼2, ...)]
서브쿼리;insert into team(team_id, region_name, team_name, orig_yyyy, stadium_id)
select replace(team_id, 'K','A') as team_id,
region_name, region_name||'올스타' as team_name,
2019 as orig_yyyy, stadium_id
from team
where region_name in ('성남', '인천');
--2개 삽입2. UPDATE
UPDATE : 잘못 입력되거나 변경이 발생해 데이터를 수정해야 하는 경우 사용
=> update 다음에 데이터를 수정할 대상 테이블명 입력
=> set절에는 수정할 칼럼명과 수정될 값 기술
=> where절에는 수정 대상이 될 행을 식별할 수 있도록 조건식 기술
=> where절 X시 전체 데이터 수정됨
update 테이블명
set 수정할 칼럼명1=수정될 새로운 값1
[, 수정할 칼럼명2=수정될 새로운 값2]
[, ...]
[where 수정 대상 식별 조건식] ;UPDATE PLAYER
SET POSITION = 'MF'
WHERE POSITION IS NULL;update문의 set절에 서브 쿼리를 사용하면, 서브 쿼리의 결과로 값이 수정
=> 서브쿼리가 null 반환시 해당 컬럼 결과 null될 수 있음
update stadium a
set (a.ddd, a.tel) = (select x.ddd, x.tel
from team x
where x.team_id=a.hometeam_id);
-- 20행 갱신
-- 홈팀이 없는 경기장의 DDD가 null로 변경되어버림update문의 where절에 서브 쿼리를 사용해 수정될 행 식별 가능
-- 홈팀의 정보가 존재하는 경기장의 지역번호를 홈팀으로 바꿈
update stadium a
set (a.ddd, a.tel) = (select x.ddd, x.tel
from team x
where x.team_id=a.hometeam_id)
where exists (select 1
from team x
where x.team_id=a.hometeam_id);
-- team 테이블 두번 조회하는 비효율 => merge문 사용3. DELETE
DELETE : 테이블에 저장된 데이터가 더이상 필요 없어질 경우 데이터 삭제 수행
=> delete from 다음 삭제할 자료가 저장된 테이블명 입력
=> from은 생략 가능
=> where절에는 삭제 대상이 될 행을 식별할 수 있는 조건식 기술
=> where절 생략시 테이블 전체 데이터 삭제
delete [from] 테이블명
[where 삭제 대상 식별 조건식];delete player
where position='DF'
and join_yyyy<=2010;delete문의 where절에 서브 쿼리 사용시, 다른 테이블 참조해 삭제할 행 식별 가능
-- 소속 선수가 10명 이하인 팀에 소속된 선수 삭제
delete player
where team_id in (select team_id
from player
group by team_id
having count(*)<=10);4. MERGE
MERGE문 : 새로운 행을 입력하거나, 기존 행을 수정하는 작업을 한 번에 함
=> merge 다음 입력, 수정되어야 할 타켓 테이블명 입력
=> using절에 입력, 수정에 사용할 소스 테이블 입력
=> on절에 타겟 테이블과 소스 테이블간의 조인 조건식 기술
=> on절의 조인 조건에 성공한 행은 matched then으로 update, 조인에 실패한 행은 not matched then 수행
merge
into 타겟 테이블명
using 소스 테이블명
on (조인 조건식)
when matched then
update
set 수정할 칼럼명1=수정될 새로운 값1
[, 수정할 칼럼명2=수정될 새로운 값2, ...]
when not matched then
insert [(칼럼1, 칼럼2, ...)]
values (값1, 값2, ...)
;merge
into team t
using team_tmp s
on (t.team_id=s.team_id)
when matched then
update
set t.region_name=s.region_name,
t.team_name=s.team_name,
t.ddd=s.ddd,
t.tel=s.tel
when not matched then
insert (t.team_id, t.region_id, t.team_name,t.stadium_id,t.ddd,t.tel)
values (s.team_id, s.region_id, s.team_name,s.stadium_id,s.ddd,s.tel);using절에 소스 테이블 대신 서브 쿼리 사용 가능
merge
into team t
using (select * from team_tmp where region_name in ('성남','부산','대구','전주')) s
on (t.team_id=s.team_id)
when matched then
update
set t.region_name=s.region_name,
t.team_name=s.team_name,
t.ddd=s.ddd,
t.tel=s.tel
when not matched then
insert (t.team_id, t.region_id, t.team_name,t.stadium_id,t.ddd,t.tel)
values (s.team_id, s.region_id, s.team_name,s.stadium_id,s.ddd,s.tel);merge update절 또는 merge insert절을 선택적으로 사용 가능
merge
into team t
using team_tmp s
on (t.team_id=s.team_id)
when matched then
update
set t.region_name=s.region_name,
t.team_name=s.team_name,
t.ddd=s.ddd,
t.tel=s.tel;🍠TCL
1. 트랜잭션 개요
트랜잭션 : 데이터베이스의 논리적 연산단위
=> 밀접히 관련돼 분리될 수 없는 한 개 이상의 데이터베이스 조작
=> 하나 이상의 SQL 문장 포함
=> 분할할 수 없는 최소의 단위
=> 전부 적용하거나 전부 취소 (ALL OR NOTHING)
=> 하나의 논리적인 작업 단위를 구성하는 세부적인 연산들의 집합
TCL(Transaction Control Language) : 트랜잭션 제어 명렁어
commit: 올바르게 반영된 데이터를 데이터베이스에반영rollback: 트랜잭션 시작 이전의 상태로되돌리는 명령어savepoint: 트랜잭션의일부만 취소할 수 있게 만드는 명령어
insert, update, delete 등이 트랜잭션의 대상
=> select for update 등의 배타적 lock을 요구하는 select는 트랜잭션 대상

잠금(LOCK) : 트랜잭션이 수행하는 동안 특정 데이터에 대해서 다른 트랜잭션이 동시에 접근하지 못하도록 제한하는 기법
=> 트랜잭션의 특정(특히 원자성)을 충족하기 위함
=> 잠금이 걸린 데이터는 잠금을 실행한 트랜잭션만 독점적으로 접근 가능
=> 다른 트랜잭션으로부터 방해나 간섭을 받지 않는 것이 보장
=> 잠금 걸린 데이터는 잠금을 수행한 트랜잭션만 해제 가능
2. COMMIT
COMMIT : 입력, 수정, 삭제한 데이터에 대해 전혀 문제가 없을 경우, 트랜잭션 완료 가능
=> insert, delete, update를 수행한 후 변경 작업이 완료됐음을 데이터베이스에 알려주기 위해 사용
commit이나 rollback 이전의 데이터 상태
- 데이터의 변경을
취소해 이전 상태로복구 가능 현재 사용자는select로결과 확인 가능다른 사용자는현재 사용자가 수행한 명령의결과 볼 수 없음- 변경된 행은
잠금(LOCKING)이 설정돼서다른 사용자가 변경 불가
delete from player;
-- 481행 삭제
commit;
--커밋 완료commit 이후 데이터 상태
- 데이터에 대한
변경 사항이 데이터베이스에반영 이전 데이터는영원히 잃어버리게 됨모든 사용자는결과를 볼 수 있음- 관련된 행에
잠금이 풀리고,다른 사용자들이행 조작 가능
SQL Server의 COMMIT
Oracle : DBMS가 트랜잭션 내부적으로 실행, DML 수행 후, 사용자가 임의로 commit 또는 rollback 수행해야 트랜잭션 종료
SQL Server : 기본적으로 Auto Commit 모드이므로, 사용자가 commit 이나 rollback 처리 할 필요X
=> DML 구문 성공시 자동으로 commit, 오류 발생시 자동으로 rollback
delete from player;
--481개의 행이 영향을 받음SQL Server에서의 트랜잭션 3가지 방식
AUTO COMMIT: SQL Server의기본 방식, DML과 DDL을 수행할 때마다DBMS가 트랜잭션 컨트롤하는 방식암시적 트랜잭션:Oracle과 같은 방식으로 처리,트랜잭션의 시작은DBMS가 처리하고트랜잭션의 끝은사용자가 명시적으로 commit 또는 rollback 처리
=>인스턴스 단위(서버 속성 창 연결화면에서 기본연결 옵션 중 암시적 트랜잭션에 체크) 또는세션 단위(세션 옵션 중SET IMPLICIT TRANSACTION ON사용)로 설정 가능명시적 트랜잭션:트랜잭션의 시작과끝모두사용자가 명시적으로 지정
=>BEGIN TRANSACTION(BEGIN TRAN 가능)으로 시작,COMMIT TRANSACTION(TRANSACTION 생략 가능)또는ROLLBACK TRANSACTION(TRANSACTION 생략 가능)으로 종료, ROLLBACK시최초의 BEGIN TRANS까지모두 rollback
3. ROLLBACK
ROLLBACK : 테이블 내 insert, delete, update한 데이터에 대해 commit 이전에는 변경 사항을 취소 가능
=> 데이터 변경 사항이 취소돼, 데이터가 이전 상태로 복구되며, 관련된 행에 대한 잠금이 풀리고 다른 사용자들이 데이터 변경 가능
update player set height=100;
--480행 갱신
rollback;
--롤백 완료SQL Server의 ROLLBACK
SQL Server는 기본 auto commit이므로, 임의적으로 rollback을 수행하려면 명시적으로 트랜잭션 선언해야 함
BEGIN TRAN
update player set height=100;
-- 480개 행 영향
rollback;
--명령 완료ROLLBACK 이후 데이터 상태
- 데이터에 대한
변경 사항취소 - 데이터가
트랜잭션 시작 이전의 상태로 되돌아감 - 관련된 행에
잠금 풀리고,다른 사용자들이행 조작 가능
rollback과 commit 사용 효과
데이터 무결성보장영구적인 변경을 하기 전데이터 변경 사항 확인가능논리적으로 연관된 작업을그룹핑해 처리 가능
4. SAVEPOINT
SAVEPOINT 정의시 rollback할 때 트랜잭션에 포함된 전체 작업 롤백X, 현 시점에서 savepoint까지 트랜잭션의 일부만 롤백 가능
=> 복수의 저장점 정의 가능, 동일 이름으로 여러 개 정의시 마지막 정의한 저장점만 유효
--oracle
savepoint svpt1;
--sql server
save transaction svtr1;저장점까지 롤백 시 rollback 뒤에 저장점 명
--oracle
rollback to svpt1;
--sql server
rollback transaction svtr1;저장점 설정 이후에 있었던 데이터 변경에 대해서만 원래 데이터 상태로 되돌림
--savepoint 1
--oracle
savepoint svpt1;
-- 저장점이 생성됐습니다.
insert into player(player_id, team_id, player_name, position, height, weight, back_no)
values ('1997035','k02','이운재','GK',182,82,1);
--1개의 행이 만들어짐
rollback to svpt1;
--롤백 완료-- SQL Server
BEGIN TRAN
save tran svtr1;
--명령 완료
insert into player(player_id, team_id, player_name, position, height, weight, back_no)
values ('1997035','k02','이운재','GK',182,82,1);
-- 1개 행 영향
rollback tran svtr1;
--명령 완료--savepoint 2
--oracle
savepoint svpt2;
-- 저장점이 생성됐습니다.
update player set height=100;
--480행 갱신
rollback to svpt2;
--롤백 완료-- SQL Server
BEGIN TRAN
save tran svtr2;
--명령 완료
update player set height=100;
-- 480개 행 영향
rollback tran svtr2;
--명령 완료--savepoint 3
--oracle
savepoint svpt3;
-- 저장점이 생성됐습니다.
delete from player;
--480행 삭제
rollback to svpt3;
--롤백 완료-- SQL Server
BEGIN TRAN
save tran svtr3;
--명령 완료
delete from player;
-- 480개 행 영향
rollback tran svtr3;
--명령 완료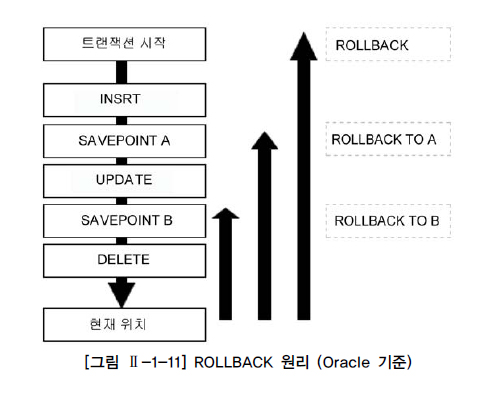
특정 저장점까지 롤백시 그 저장점 이후 설정한 저장점은 무효
=> rollback to A 실행하면 저장점 B는 존재X
저장점 지정 없이 롤백시 반영되지 않은 모든 변경 사항 취소하고 트랜잭션 종료
트랜잭션에 대해 다시 정리
커밋과 롤백의 목적 : 데이터 변경을 발생시키는 insert, update, delete 명령어 수행 시 변경되는 데이터 무결성 보장
COMMIT과 ROLLBACK을 실행하지 않아도 자동으로 트랜잭션이 종료되는 경우 (Oracle)
DDL문장을 실행하면,자동 커밋이 수행데이터베이스를정상적으로 접속 종료하면 자동으로 트랜잭션커밋애플리케이션 이상 종료로 데이터베이스와의 접속이단절됐을 경우 트랜잭션 자동롤백
트랜잭션이 자동으로 종료되는 경우 (SQL Server)
애플리케이션 이상 종료로 데이터베이스와의 접속이단절됐을 경우 트랜잭션 자동롤백
🥟DDL
1. CREATE TABLE
테이블 : 데이터베이스의 가장 기본적인 객체, 행과 열 구조로 데이터 저장
=> 테이블 생성을 위해선 해당 테이블에 입력될 데이터 정의, 정의한 데이터의 데이터 유형 결정
테이블과 칼럼 정의
기본키 칼럼 : 테이블에 존재하는 모든 데이터를 고유하게 식별할 수 있으면서, 반드시 값이 존재하는 단일 칼럼이나 칼럼의 조합들 중 하나를 선정
테이블과 테이블 간에 정의된 관계 : 기본키와 외부키를 활용해 설정

CREATE TABLE
create table 테이블명(
칼럼명1 데이터유형 [기본 값] [NOT NULL],
칼럼명2 데이터유형 [기본 값] [NOT NULL],
칼럼명3 데이터유형 [기본 값] [NOT NULL],
...
);테이블 생성 시 주의사항
테이블명은 객체를 의미할 수 있는 적절한 이름 사용, 가능한단수형권고테이블명은 다른 테이블의 이름과중복X- 한 테이블 내에서는
칼럼명이중복X - 테이블 이름을 지정하고
각 칼럼들은괄호()로 묶어 지정 각 칼럼들은콤마,로 구분, 테이블 생성문의 끝은 항상세미콜론;칼럼에 대해서는 다른 테이블까지 고려해일관성있게 사용 (데이터 표준화 관점)칼럼 뒤에데이터 유형은꼭 지정테이블명과칼럼명은 반드시문자로 시작, 벤더별 길이 한계벤더에서 사전에 정의한예약어사용 불가A-Z,a-z,0-9,_,$,#문자만 허용

DBMS는 칼럼을 DB명+DB사용자명+테이블명+칼럼명과 같이 계층적 구조를 가진 전체 경로로 관리
--oracle
CREATE TABLE PLAYER (
PLAYER_ID CHAR(7) NOT NULL,
PLAYER_NAME VARCHAR2(20) NOT NULL,
TEAM_ID CHAR(3) NOT NULL,
E_PLAYER_NAME VARCHAR2(40),
NICKNAME VARCHAR2(30),
JOIN_YYYY CHAR(4),
POSITION VARCHAR2(10),
BACK_NO NUMBER(2),
NATION VARCHAR2(20),
BIRTH_DATE DATE,
SOLAR CHAR(1),
HEIGHT NUMBER(3),
WEIGHT NUMBER(3),
CONSTRAINT PLAYER_PK PRIMARY KEY (PLAYER_ID),
CONSTRAINT PLAYER_FK FOREIGN KEY (TEAM_ID) REFERENCES TEAM(TEAM_ID)
);테이블 추가 주의 사항
- 테이블 생성시
대소문자 구분 X, 기본적으로 테이블이나 칼럼은대문자로 만들어짐 DATETIME데이터 유형은 별도로크기 지정X문자 데이터 유형은 반드시 가질 수 있는최대 길이표시마지막 칼럼은콤마 X- 칼럼에 대한
제약조건은CONSTRAINT를 이용해 추가
칼럼 LEVEL 정의 방식 : 제약조건을 각 칼럼의 데이터 유형 뒤에 기술
테이블 LEVEL 정의 방식 : 제약조건을 테이블 정의 마지막에 기술
제약조건
제약조건(CONSTRAINT) : 사용자가 원하는 조건의 데이터만 유지하기 위한, 즉 데이터 무결성을 유지하기 위한 데이터베이스의 보편적인 방법
=> 테이블의 특정 칼럼에 설정하는 제약
DEFAULT: 데이터 입력 시 칼럼 값을 지정하지 않은 경우null값이 입력되는데, default값을 정의했다면null값 대신정의된기본값(default)이 자동 입력
생성된 테이블 구조 확인
--oracle
DESCRIBE 테이블명;
-- 또는
DESC 테이블명;
--sql server
exec sp_help 'dbo.테이블명'
goSELECT 문장으로 테이블 생성 사례
CTAS, Create Table ~ As Select ~ : select 문장을 활용해 테이블 생성
=> 기존 테이블을 이용하여 데이터 유형을 다시 정의하지 않아도 됨
=> 기존 테이블 제약조건 중 NOT NULL제약만 적용됨
=> 기본키,고유키,외래키,CHECK등의 다른 제약조건은 없어짐
Select ~ Into ~ : SQL Server의 CTAS
=> 칼럼 속성에 Identity(시퀀스 같은 것)를 사용했다면, Identity 속성까지 같이 적용
--oracle
create table team_temp
as select * from team;
--sql server
select * into team_temp from team;2. ALTER TABLE
ALTER TABLE : 칼럼을 추가/삭제하거나 제약조건을 추가/삭제하는 등 테이블 구조 변경
ADD COLUMN
ADD COLUMN : 테이블에 필요한 칼럼 추가
--oracle
ALTER TABLE 테이블명
ADD(추가할 칼럼명1 데이터유형 [기본 값] [NOT NULL]
[, 추가할 칼럼명2 데이터유형 [기본 값] [NOT NULL]
, ...]);
--sql server
ALTER TABLE 테이블명
ADD 추가할 칼럼명1 데이터유형 [기본 값] [NOT NULL]
[, 추가할 칼럼명2 데이터유형 [기본 값] [NOT NULL]
, ...];새롭게 추가된 칼럼은 테이블의 마지막 칼럼이 되며, 칼럼 위치 지정은 불가
alter table player add (address varchar2(80));DROP COLUMN
DROP COLUMN : 테이블에서 필요 없는 칼럼 삭제
=> 데이터가 있거나 없거나 모두 삭제 가능
=> 칼럼 삭제 후 최소 하나 이상의 칼럼이 테이블에 존재해야 함
=> 한 번 삭제된 칼럼 복구 불가
--oracle
ALTER TABLE 테이블명 DROP (삭제할 칼럼명1 [, 삭제할 칼럼명2, ...]);
--sql server
ALTER TABLE 테이블명 DROP COLUMN 삭제할 칼럼명1 [, 삭제할 칼럼명2, ...];ALTER TABLE PLAYER DROP COLUMN ADDRESS;MODIFY COLUMN
MODIFY COLUMN : 테이블에 존재하는 칼럼에 대해 데이터 유형, 디폴트 값, NOT NULL 제약조건에 대해 변경
--oracle
ALTER TABLE 테이블명
MODIFY ( 칼럼명1 데이터유형 [기본 값] [NOT NULL]
[, 칼럼명2 데이터유형 [기본 값] [NOT NULL]
, ...]);
--sql server
ALTER TABLE 테이블명 ALTER COLUMN 칼럼명 데이터유형 [NOT NULL];칼럼 변경시 고려사항
칼럼 크기를늘릴수는 있지만, 테이블에 데이터가 존재한다면 칼럼의 크기를줄이는 데제약
=>기존 데이터가 훼손될 수 있기 때문- 해당 칼럼이
NULL값만 갖고 있거나 테이블에아무 행도 없으면칼럼 크기 줄이기 O - 해당 칼럼이
NULL값만 갖고 있으면데이터 유형 변경O default값을 바꾸면변경 작업 이후발생하는 행 삽입에만 영향null값이없을 경우에만not null 제약조건추가 가능
--oracle
ALTER TABLE TEAM_TEMP MODIFY (ORIG_YYYY VARCHAR2(8) DEFAULT '20020129' NOT NULL);
--sql server
ALTER TABLE TEAM_TEMP ALTER COLUMN ORIG_YYYY VARCAHR(8) NOT NULL;
-- 명령 완료
ALTER TABLE TEAM_TEMP ADD CONSTRAINT DF_ORIG_YYYY DEFAULT '20020129' FOR ORIG_YYYY;RENAME COLUMN
RENAME COLUMN : 칼럼명을 변경
--oracle
ALTER TABLE 테이블명 RENAME COLUMN 기존 칼럼명 TO 새로운 칼럼명;
--sql server
sp_rename '기존 칼럼명', '새로운 칼럼명', 'COLUMN';RENAME COLUMN으로 칼럼명이 변경되면, 해당 칼럼과 관계된 제약조건에 대해서도 자동으로 변경
--oracle
ALTER TABLE PLAYER RENAME COLUMN TEMP_ID TO PLAYER_ID;
--sql server
sp_rename 'dbo.PLAYER.PLAYER_ID', 'TEMP_ID', 'COLUMN'; DROP CONSTRAINT
DROP CONSTRAINT : 테이블 생성 시 부여했던 제약조건 삭제
ALTER TALBE 테이블명 DROP CONSTRAINT 제약조건명;ALTER TABLE PLAYER DROP CONSTRAINT PLAYER_FK;ADD CONSTRAINT
ADD CONSTRAINT : 특정 칼럼에 제약조건을 추가
ALTER TALBE 테이블명 ADD CONSTRAINT 제약조건명 제약조건(칼럼명);ALTER TABLE PLAYER ADD CONSTRAINT PLAYER_FK FOREIGN KEY (TEAM_ID) REFERENCES TEAM(TEAM_ID);참조 제약조건을 추가하면, 참조 무결성 옵션에 따라 데이터를 삭제하려는 경우, 외부 테이블에서 참조되고 있기 때문에 삭제가 불가능하게 제약 가능
=> 외래키 설정을 통해 실수에 의한 테이블 삭제나 필요 데이터의 의도하지 않은 삭제를 방지 가능
3. RENAME TABLE
RENAME TABLE : 테이블의 이름 변경
--oracle
RENAME 기존 테이블명 TO 새로운 테이블명;
--sql server
sp_rename '기존 테이블명', '새로운 테이블명';--oracle
RENAME TEAM TO TEAM_BACKUP;
--sql server
sp_rename 'dbo.TEAM','TEAM_BACKUP';4. DROP TABLE
DROP TABLE : 불필요한 테이블 삭제
DROP TABLE 테이블명 [CASCADE CONSTRAINT];- 테이블의
모든 데이터및구조삭제 cascade constraint: 해당 테이블과 관계 있었던참조 제약조건도삭제(sql server는 cascade 옵션 존재X, 테이블 삭제 전foreign key 제약 조건또는참조하는 테이블삭제해야 함)
DROP TABLE PLAYER;5. TRUNCATE TABLE
TRUNCATE TABLE : 테이블 자체가 삭제되는 것은 아니고, 모든 행들이 제거되고 저장 공간을 재사용 가능하도록 해제
TRUNCATE TABLE 테이블명;TRUNCATE TABLE TEAM;drop table : 테이블 자체가 없어지기 때문에, 테이블 구조 확인 불가
truncate table : 테이블 구조는 유지한 채 데이터만 삭제
=> auto commit됨 (정상적인 복구 불가능)
🥠DCL
1. DCL 개요
DCL(Data Control Language) : 유저 생성 및 권한 제어 명령어
2. 유저와 권한
운영 시스템에서 사용하던 유저를 공개하면, 데이터 손실의 우려가 커짐
=> 새로운 유저를 생성하고, 생성한 유저에게 공유할 테이블 및 오브젝트에 대한 접근 권한 부여해 문제 해결
대부분 데이터베이스는 데이터 보호와 보안을 위해 유저와 권한 관리
오라클에서 제공하는 유저들
| 유저 | 역할 |
|---|---|
| SCOTT | Oracle 테스트용 샘플 계정 Default 패스워드 : TIGER |
| SYS | 백업 및 복구 등 데이터베이스 상 모든 관리 기능 수행 가능한 최상위 관리자 계정 |
| SYSTEM | 백업, 복구 등 일부 관리 기능 제외 모든 시스템 권한 부여받은 DBA 계정 (Oracle 설치 시 패스워드 설정) |
오라클은 유저를 통해 데이터베이스에 접속
=> 아이디와 비밀번호방식으로 인스턴스에 접속, 그에 해당하는 스키마에 오브젝트 생성등의 권한 부여
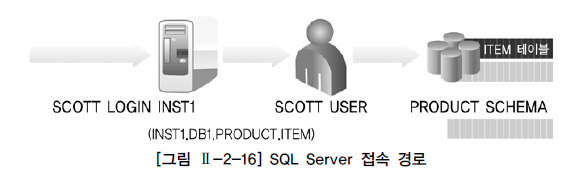
SQL Server는 인스턴스 접속을 위해 로그인을 생성
=> 인스턴스 내에 존재하는 다수의 데이터베이스에 연결해 작업하기 위해 유저 생성 후 로그인과 유저 매핑
=> 특정 유저는 특정 데이터베이스 내 특정 스키마에 대해 권한 부여
SQL Server 로그인 방식
마이크로소프트 윈도우 운영체제 인증 방식:윈도우에로그인한 정보를 가지고 접속
=> 윈도우 사용자 계정을 통해 연결시운영체제의윈도우 보안 주체 토큰을 사용해계정 이름과암호가유효한지 확인, 즉윈도우에서사용자ID확인
=> SQL Server는암호 요청X,ID 유효성 검사 X
=> 기본 인증 모드
=> SQL Server 인증보다 훨씬 더안전
=>kerberos 보안 프로토콜사용
=>트러스트된 연결혼합 모드(Windows 인증 또는 SQL 인증) 방식:Oracle처럼사용자 아이디와비밀번호로 접속
유저 생성과 시스템 권한 부여
사용자가 실행하는 모든 DDL문장은 권한이 있어야 실행 가능 => 시스템 권한
유저 생성 권한(CREATE USER) : 새로운 유저 생성시 필요한 권한
--oracle
CONN SCOTT/TIGER
--SCOTT 유저로 접속
create user sqlp identified by db2024;
--권한 불충분DBA 권한을 갖고 있는 SYSTEM 유저로 접속하면, 유저 생성 권한을 다른 유저에게 부여 가능
--oracle
grant create user to scott;
conn scott/tiger
create user sqlp identified by db2024;
--사용자 생성SQL Server는 유저 생성 전에 로그인 생성해야 함
=> 로그인 생성 가능한 권한을 가진 로그인은 sa
-- sql server
-- 로그인 후 최초로 접속할 데이터베이스는 AdventureWorks 데이터베이스로 설정
create login sqlp with password='db2024', default_database=AdventureWorks;sql server에서 유저는 데이터베이스마다 존재
=> 유저 생성을 위해선 생성하고자 하는 유저가 속할 데이터베이스로 이동한 후 처리
-- sql server
use adventureworks;
go
create user sqlp for login sqlp with default_schema=dbo;유저가 생성 되었으나, 아무런 권한도 부여받지 못해 로그인을 하면, create session 권한이 없다는 오류 발생
=> 유저가 로그인을 하려면 create session 권한을 부여받아야 함
grant create session to sqlp;
conn sqlp/db2024;
--연결로그인 권한만 부여됐으므로 테이블 생성을 위해선 테이블 생성 권한(create table)이 불충분하다는 오류 발생
--oracle
grant create table to sqlp;
--sql server
use adventureworks;
go
grant create table to sqlp;
--스키마에 권한 부여
grant control on schema::dbo to sqlp;OBJECT에 대한 권한 부여
OBJECT(객체) 권한 : 특정 오브젝트인 뷰, 테이블 등에 대한 SELECT, INSERT, DELETE, UPDATE 등 작업 명령어 의미
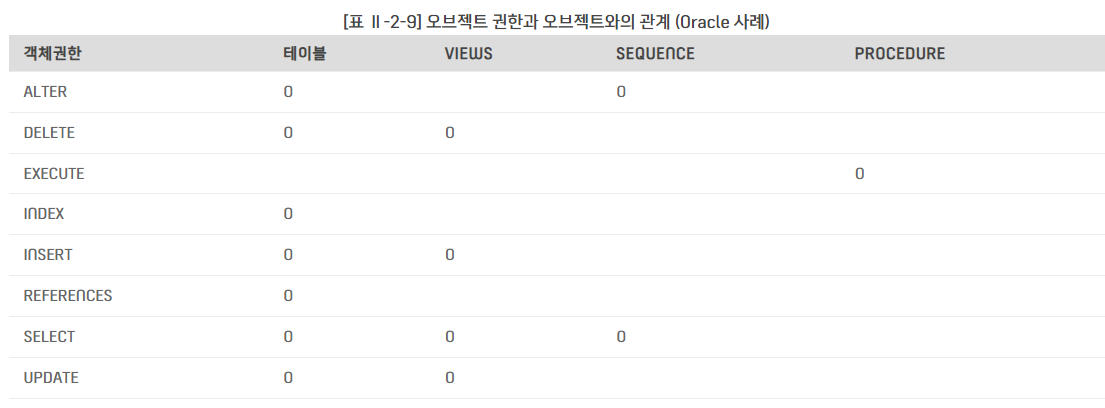
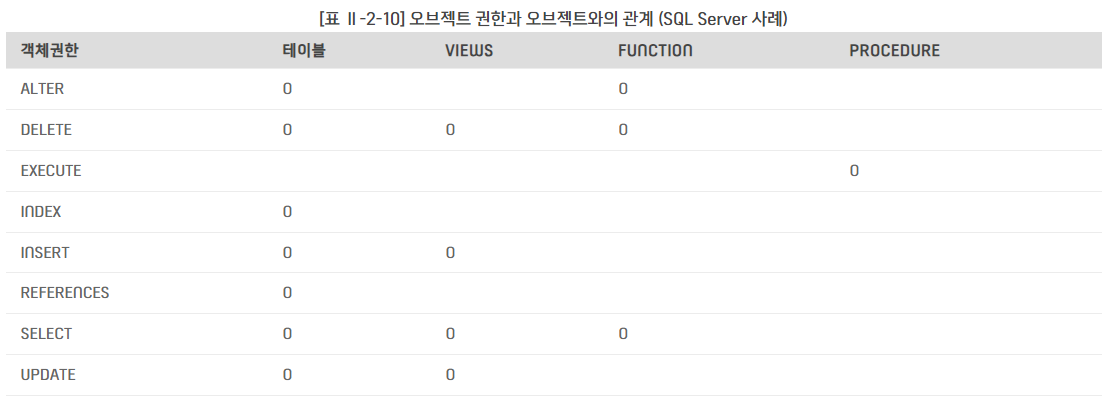
모든 유저는 자신이 생성한 테이블 외에 다른 유저의 테이블에 접근하려면 해당 테이블에 대한 오브젝트 권한을 소유자로부터 부여받아야 함
=> sql server는 유저가 스키마에 대한 권한만을 가지므로 테이블과 같은 오브젝트는 유저가 소유하는 것이 아닌 스키마가 소유하게 되며 유저는 스키마에 대해 권한을 가짐
다른 유저가 소유한 객체에 접근하려면 객체 앞에 객체를 소유한 유저의 이름을 붙여야 함
=> sql server는 객체 앞에 소유한 유저 이름 대신 객체가 속한 스키마 이름을 붙임
grant select on menu to scott;
--oracle
select * from sqlp.menu;
--sql server
select * from dbo.menu;select 권한만 부여받았으므로 update, insert, delete와 같은 다른 작업은 불가능
=> 오브젝트 권한은 SELECT, INSERT, UPDATE, DELETE 등 따로 권한 관리
3. Role을 이용한 권한 부여
ROLE : 유저들과 권한들 사이에서 중개 역할
=> 데이터베이스 관리자는 role을 생성하고 role에 각종 권한 부여 후, role을 다른 role이나 유저에게 부여
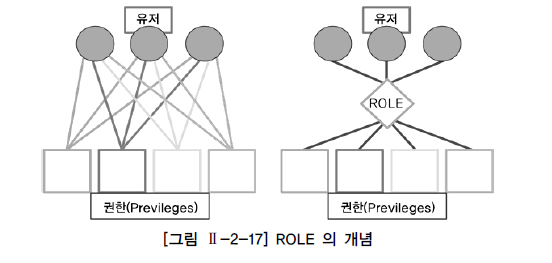
ROLE에는 시스템 권한과 오브젝트 권한 모두 부여 가능
--권한을 취소할 때는 REVOKE 사용
--oracle
revoke create session, create table from sqlp;--역할 생성 시 CREATE ROLE
-- ROLE 만들고, SQLP 유저에게 부여
create role login_table;
grant create session, create table to login_table;
grant login_table to sqlp;ROLE을 사용해 권한을 부여하는 것이 직접 부여하는 것 보다 빠르고 안전하게 유저 관리 가능
CONNECT ROLE과 RESOURCE ROLE에 포함된 권한 목록 (Oracle)
| CONNECT | RESOURCE |
|---|---|
| CREATE CLUSTER | |
| CREATE INDEXTYPE | |
| CREATE OPERATOR | |
| CREATE SESSION | CREATE PROCEDURE |
| CREATE SEQUENCE | |
| CREATE TABLE | |
| CREATE TRIGGER | |
| CREATE TYPE |
일반적으로 유저 생성 시 CONNECT와 RESOURCE ROLE을 사용해 기본 권한 부여
DROP USER : 유저를 삭제하는 명령어
=> CASCADE 옵션 : 해당 유저가 생성한 오브젝트 먼저 삭제 후 유저 삭제
drop user sqlp cascade;
--menu 테이블도 같이 삭제됨
create user sqlp identified by db2024;
grant connect, resource to sqlp;SQL Server에서는 ROLE을 생성해 사용하기보다는 기본적으로 제공되는 ROLE에 멤버로 참여하는 방식으로 사용
특정 로그인이 멤버로 참여할 수 있는 서버 수준 역할(ROLE)
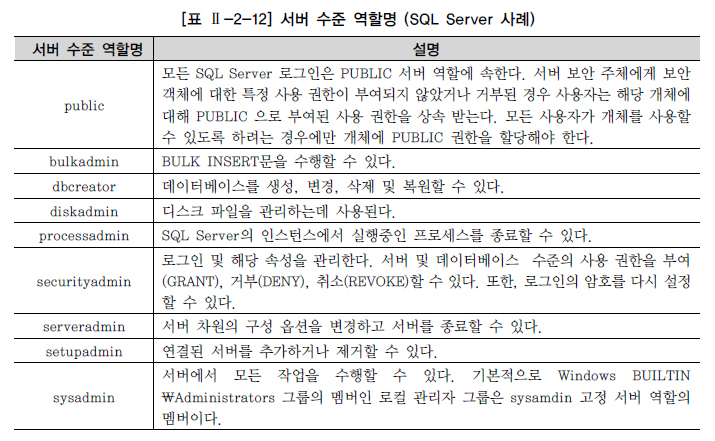
데이터베이스에 존재하는 유저가 참여할 수 있는 데이터베이스 수준 역할의 멤버
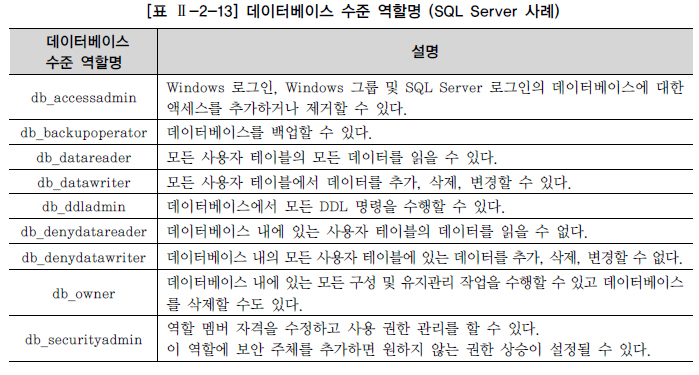
인스턴스 수준의 작업이 필요한 경우 서버 수준 역할 부여, 작은 개념인 데이터베이스 수준의 권한이 필요한 경우 데이터베이스 수준 역할 부여
=> 로그인에게는 서버 수준 역할 (인스턴스 수준 요구)
=> 사용자에게는 데이터베이스 수준 역할 (데이터베이스 수준 요구)
