📔설명
서브쿼리, 집합 연산자, 그룹, 윈도우 함수, Top N 쿼리, 계층형 질의, PIVOT절, 정규 표현식 등을 알아보자
🥗서브 쿼리

서브쿼리(Subquery) : 하나의 SQL 문안에 포함되어 있는 또 다른 SQL문
=> 메인쿼리가 서브쿼리를 포함하는 종속적인 관계
=> 서브쿼리는 메인쿼리의 칼럼 모두 사용 가능
=> 메인쿼리는 서브쿼리의 칼럼 사용 불가능
질의 결과에 서브쿼리 칼럼을 표시해야 할 경우 조인 방식으로 변환하거나 스칼라 서브 쿼리등 사용
서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인 쿼리 레벨로 결과 집합 생성
서브 쿼리 사용 시 주의 사항
서브쿼리는괄호로 감싸서 기술- 서브쿼리는
단일 행또는복수 행비교연산자와 함께 사용 가능
=>단일행 비교 연산자는 서브 쿼리 결과가 반드시1건 이하여야 하고,복수행 비교 연산자는 결과 건수 상관 X 중첩 서브 쿼리및스칼라 서브 쿼리에서는ORDER BY사용 X
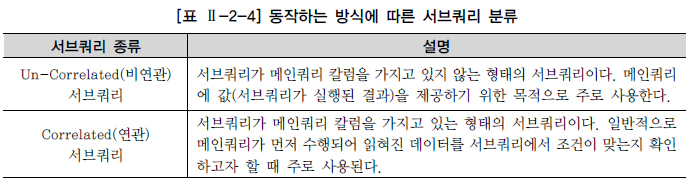
서브쿼리는 메인 쿼리 안 종속적인 관계이므로, 논리적인 실행 순서는 항상 메인쿼리에서 읽힌 데이터를 서브 쿼리에서 해당 조건이 만족하는지 확인하는 방식으로 수행
=> 실제 서브 쿼리 실행순서는 상황에 따라 달라짐

1. 단일 행 서브 쿼리
서브 쿼리가 단일 행 비교 연산자(=, >, >=, ..) 와 사용될 때는 서브쿼리 결과 건수가 반드시 1건 이하
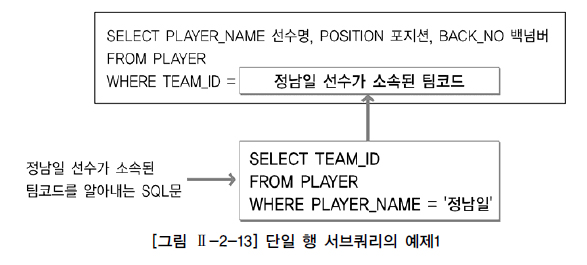
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버
FROM PLAYER
WHERE TEAM_ID = (SELECT TEAM_ID
FROM PLAYER
WHERE PLAYER_NAME = '정남일')
ORDER BY PLAYER_NAME;
소속팀을 알아내는 서브쿼리가 먼저 수행돼 정남일 선수의 team_id가 반환
메인쿼리는 반환된 결과를 이용해 조건을 만족하는 선수들의 정보를 출력
만약, 같은 이름을 가진 동명이인이 있다면, 2건 이상의 결과가 반환되어 오류가 발생
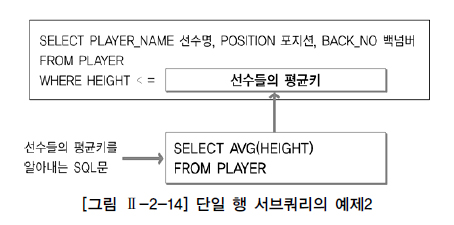
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버
FROM PLAYER
WHERE HEIGHT <= (SELECT AVG(HEIGHT) FROM PLAYER)
ORDER BY PLAYER_NAME;
테이블 전체에 집계함수 적용 시 결과는 단 1건만 생성되어, 단일 행 서브 쿼리 사용 가능
2. 다중 행 서브 쿼리
서브 쿼리 결과가 2건 이상 반환될 수 있다면, 반드시 다중 행 비교 연산자(IN, ALL, ANY, SOME)과 함께 사용

SELECT REGION_NAME 연고지명, TEAM_NAME 팀명, E_TEAM_NAME 영문팀명
FROM TEAM
WHERE TEAM_ID = (SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME = '정현수')
ORDER BY TEAM_NAME;
정현수란 이름을 가진 선수가 2명 이상이기 때문에, 단일 행 비교 연산자인 =로 처리 불가능
SELECT REGION_NAME 연고지명, TEAM_NAME 팀명, E_TEAM_NAME 영문팀명
FROM TEAM
WHERE TEAM_ID IN (SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME = '정현수')
ORDER BY TEAM_NAME;
3. 다중 칼럼 서브 쿼리
다중 칼럼 서브 쿼리 : 서브 쿼리의 결과로 여러 개의 칼럼이 반환되어, 메인 쿼리 조건과 동시에 비교
=> SQL Server에서 지원 X
-- 소속팀별 키가 가장 작은 사람들 출력
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE (TEAM_ID, HEIGHT) IN (SELECT TEAM_ID, MIN(HEIGHT)
FROM PLAYER
GROUP BY TEAM_ID)
ORDER BY TEAM_ID, PLAYER_NAME;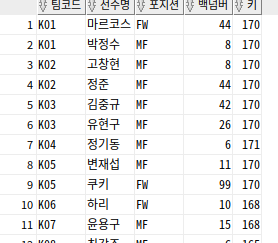
한 소속팀에서 키가 작은 사람이 여러 명이 반환되었는데, 동일 팀 내에서 조건을 만족하는 선수가 여러 명 존재하기 때문
4. 연관 서브 쿼리
연관 서브 쿼리(Correlated Subquery) : 서브쿼리 내에 메인 쿼리 칼럼이 사용
--자신이 속한 팀의 평균키보다 작은 선수들 출력
SELECT T.TEAM_NAME 팀명, M.PLAYER_NAME 선수명, M.POSITION 포지션,
M.BACK_NO 백넘버, M.HEIGHT 키
FROM PLAYER M, TEAM T
WHERE M.TEAM_ID = T.TEAM_ID
AND M.HEIGHT < ( SELECT AVG(S.HEIGHT)
FROM PLAYER S
WHERE S.TEAM_ID = M.TEAM_ID
GROUP BY S.TEAM_ID )
ORDER BY 선수명;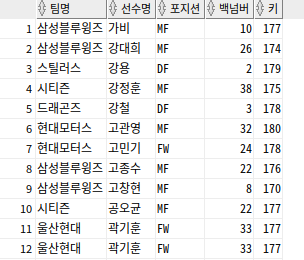
자신이 속한 팀의 소속 선수들 평균키를 구한 후, 자신의 키가 그 평균키보다 작으면 선수의 정보를 출력
이 작업을 메인 쿼리에 존재하는 모든 행에 대해서 반복 수행
SELECT STADIUM_ID ID, STADIUM_NAME 경기장명
FROM STADIUM A
WHERE EXISTS (SELECT 1
FROM SCHEDULE X
WHERE X.STADIUM_ID = A.STADIUM_ID
AND X.SCHE_DATE BETWEEN '20120501' AND '20120502');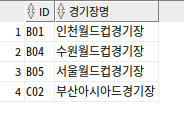
EXITS 서브 쿼리는 항상 연관 서브 쿼리, 아무리 조건을 만족하는 건이 여러 건이라도 조건을 만족하는 1건만 찾으면 추가적인 검색 X
5. 그 밖의 위치에서 사용하는 서브 쿼리
SELECT 절에 서브 쿼리 사용하기
스칼라 서브 쿼리(Scalar Subquery) : 한 행, 한 컬럼만을 반환하는 서브 쿼리
=> 칼럼을 쓸 수 있는 대부분의 곳에 사용 가능
=> SELECT절에서 사용
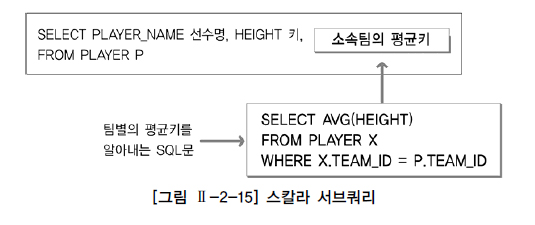
--선수 정보와 선수가 속한 팀의 평균키 출력
SELECT PLAYER_NAME 선수명, HEIGHT 키,
(SELECT AVG(HEIGHT)
FROM PLAYER X
WHERE X.TEAM_ID = P.TEAM_ID) 팀평균키
FROM PLAYER P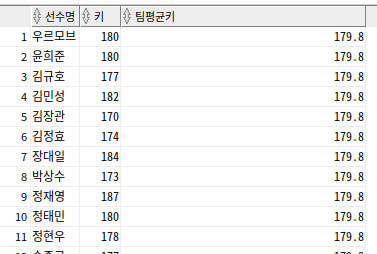
스칼라 서브 쿼리는 메인 쿼리의 결과 건수만큼 반복수행
스칼라 서브 쿼리도 단일행 서브 쿼리 이므로 2건 이상 반환시 오류 반환
FROM 절에서 서브 쿼리 사용하기
인라인 뷰(Inline View) : 서브 쿼리의 결과를 마치 테이블처럼 사용 가능
=> FROM절에서 사용
=> 객체로서 저장해 테이블처럼 사용하는 뷰와 달리, 인라인 뷰는 쿼리 내에서 즉시 처리
--모든 선수들 중 키가 큰 순서대로 5명 추출
--oracle
SELECT PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM (SELECT PLAYER_NAME, POSITION, BACK_NO, HEIGHT
FROM PLAYER
WHERE HEIGHT IS NOT NULL
ORDER BY HEIGHT DESC)
WHERE ROWNUM <= 5;
--sql server
SELECT TOP(5) PLAYER_NAME AS 선수명, POSITION AS 포지션, BACK_NO AS 백넘버, HEIGHT AS 키
FROM PLAYER
WHERE HEIGHT IS NOT NULL
ORDER BY HEIGHT DESC;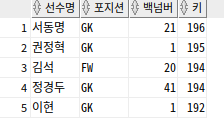
인라인 뷰에서는 ORDER BY절 사용 가능
=> 인라인 뷰에서 먼저 정렬을 수행하고, 정렬된 결과 중 일부 데이터를 추출
HAVING 절에서 서브 쿼리 사용하기
HAVING절은 집계함수와 함께 사용될 때 그룹핑 된 결과에 대해 부가적인 조건을 주기 위해 사용
--평균키가 삼성 팀의 평균키보다 작은 팀에 대한 쿼리
SELECT P.TEAM_ID 팀코드, T.TEAM_NAME 팀명, AVG(P.HEIGHT) 평균키
FROM PLAYER P, TEAM T WHERE P.TEAM_ID = T.TEAM_ID
GROUP BY P.TEAM_ID, T.TEAM_NAME
HAVING AVG(P.HEIGHT) < (SELECT AVG(HEIGHT)
FROM PLAYER
WHERE TEAM_ID ='K02');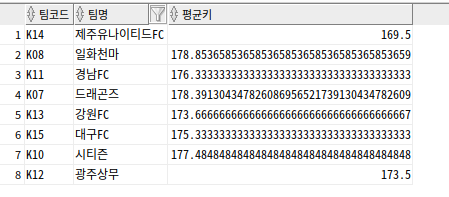
6. 뷰
뷰(View) : 실제 데이터 가지지 X
=> 단지 뷰 정의만 가짐
=> 질의에서 뷰가 사용되면, 뷰 정의를 참조해 DBMS 내부적으로 질의 재작성해 질의 수행
=> CREATE VIEW문으로 생성
=> DROP VIEW문으로 제거

--선수 정보와 선수 팀명 추출
CREATE VIEW V_PLAYER_TEAM AS
SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID;--포지션이 골키퍼, 미드필더인 선수만 추출
CREATE VIEW V_PLAYER_TEAM_FILTER AS
SELECT PLAYER_NAME, POSITION, BACK_NO, TEAM_NAME
FROM V_PLAYER_TEAM
WHERE POSITION IN ('GK', 'MF');V_PLAYER_TEAM 뷰를 기반으로 생성한 뷰이다
SELECT PLAYER_NAME, POSITION, BACK_NO, TEAM_ID, TEAM_NAME
FROM V_PLAYER_TEAM
WHERE PLAYER_NAME LIKE '황%';
--DBMS 내부
SELECT PLAYER_NAME, POSITION, BACK_NO, TEAM_ID, TEAM_NAME
FROM (SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID)
WHERE PLAYER_NAME LIKE '황%';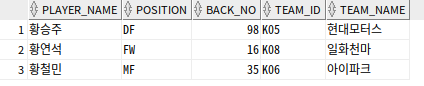
--DROP VIEW로 뷰 제거
DROP VIEW V_PLAYER_TEAM;
DROP VIEW V_PLAYER_TEAM_FILTER;🥙집합 연산자
집합 연산자 : 여러 개의 결과 집합 간의 연산을 통해 결합하는 방식
=> 2개 이상의 질의 결과를 하나의 결과로 만들어 줌
=> 서로 다른 테이블에서 유사한 형태의 결과를 반환하는 것을 하나의 결과로 합치고자 할 때
=> 동일 테이블에서 서로 다른 질의를 수행해 결과를 합치고자 할 때 사용
집합 연산자 사용을 위해 만족해야 할 조건
SELECT절의칼럼 수,데이터 타입이 동일

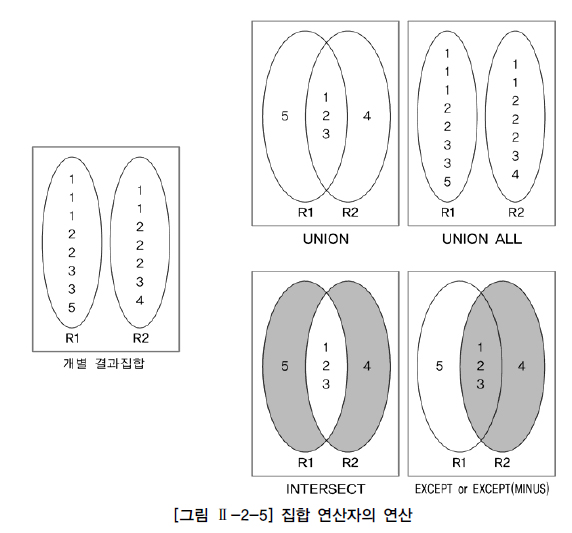
UNION ALL을 제외한 다른 집합 연산자는 해당 집합 연산을 수행한 후, 결과에서 중복된 건을 배제
EXCEPT는 집합의 순서에 따라 결과가 달라질 수 있음
ORDER BY절은 집합 연산을 적용한 최종 결과에 대해 정렬을 수행하므로, 마지막에 한 번만 기술
--소속이 K02와 K07인 선수 모두 출력
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE TEAM_ID = 'K02'
UNION
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE TEAM_ID = 'K07';
-- 두 집합의 조건이 모두 동일 테이블에 있으므로
-- where team_id='k02' or team_id='k07'
-- 또는 where team_id in ('k02', 'k07') 가능
-- UNION은 중복 제외하므로 SELECT절에 DISTINCT 기술 필요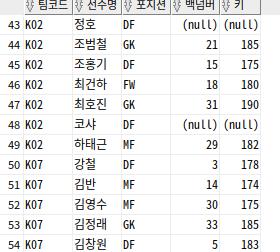
--포지션별 평균키와 팀별 평균키
SELECT 'P' 구분코드, POSITION 포지션, ROUND(AVG(HEIGHT),3) 평균키
FROM PLAYER
GROUP BY POSITION
UNION ALL
SELECT 'T' 구분코드, TEAM_ID 팀명, ROUND(AVG(HEIGHT),3) 평균키
FROM PLAYER
GROUP BY TEAM_ID
ORDER BY 1;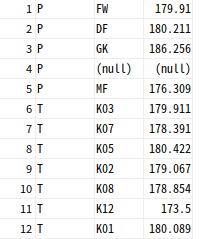
집합 연산자의 결과를 표시할 경우, 첫 번째 SQL문에서 사용한 alias를 적용
--삼성 팀 중 포지션이 미드필더가 아닌 선수
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE TEAM_ID = 'K02'
MINUS
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE POSITION = 'MF'
ORDER BY 1, 2, 3, 4, 5;
-- not exists 또는 not in 서브쿼리로 변경 가능
NOT EXISTS (SELECT 1
FROM PLAYER Y
WHERE Y.PLAYER_ID = X.PLAYER_ID
AND POSITION = 'MF')
PLAYER_ID NOT IN (SELECT PLAYER_ID
FROM PLAYER
WHERE POSITION = 'MF') 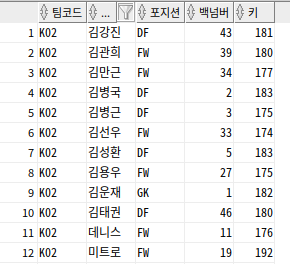
-- 삼성 팀이면서 포지션이 골키퍼인 선수
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE TEAM_ID = 'K02'
INTERSECT
SELECT TEAM_ID 팀코드, PLAYER_NAME 선수명, POSITION 포지션, BACK_NO 백넘버, HEIGHT 키
FROM PLAYER
WHERE POSITION = 'GK'
ORDER BY 1, 2, 3, 4, 5;
-- EXISTS 또는 IN으로 변경 가능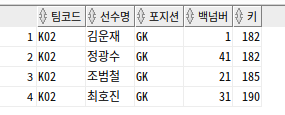
🥪그룹 함수
1. 데이터 분석 개요
데이터 분석을 위해 세 가지 함수를 정의'
AGGREGATE FUNCTION
count, sum, avg, max, min 등 집계 함수
GROUP FUNCTION
집계 함수를 제외하고, 소그룹 간의 소계를 계산하는 rollup 함수
=> group by의 확장된 형태로, 사용이 쉬우며 병렬 수행 가능함
group by 항목 간 다차원적인 소계를 계산하는 cube 함수
=> 결합 가능한 모든 값에 집계를 생성하므로 시스템 부하가 큼
특정 항목에 대한 소계를 계산하는 grouping sets 함수
=> 원하는 부분의 소계만 손쉽게 추출 가능
WINDOW FUNCTION
분석 함수나 순위 함수라고도 알려짐
2. ROLLUP 함수
ROLLUP( , )
=> 기술된 칼럼의 수가 N일 때, N+1 레벨의 소계가 생성
=> 인수는 계층 구조 이므로, 순서가 바뀌면 결과가 바뀜
-- 부서, 업무별 정렬
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
ORDER BY DNAME, JOB;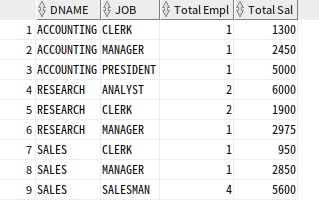
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB)
ORDER BY DNAME, JOB;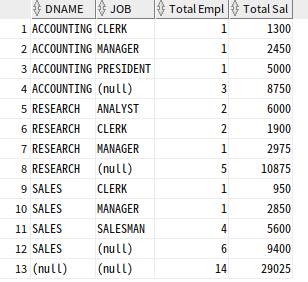
ROLLUP (DNAME, JOB)에 의해 추가 LEVEL 집계가 생성
GROUP BY수행 시 생성되는 표준 집계DNAME별 모든 JOB의 SUBTOTALGRAND TOTAL
GROUPING 함수
ROLLUP이나CUBE에 의한소계가 계산된 결과는GROUPING(EXPR)=1표시- 그 외의 결과에는
GROUPING(EXPR)=0표시
-- 부서별, 업무별과 전체 집계를 표시한 레코드에서는 grouping 함수가 1 반환
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);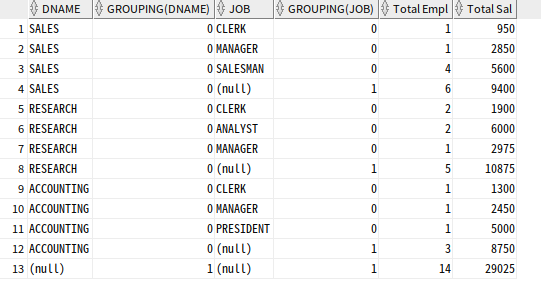
--grouping + case
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, JOB);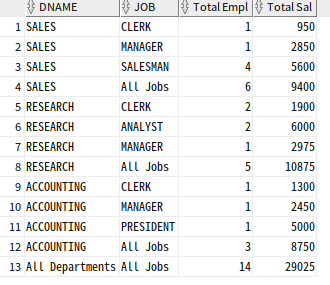
-- rollup 함수 일부 사용 group by dname, rollup(job)
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, ROLLUP(JOB)
ORDER BY DNAME, JOB;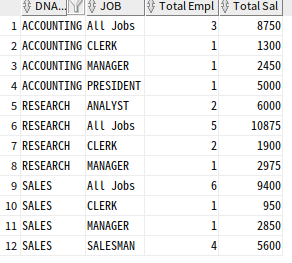
ROLLUP이 JOB 칼럼에만 사용되어, DNAME에 대한 집계는 필요하지 않기 때문에 마지막 All Departments & All Jobs 줄만 사라짐
SELECT DNAME, JOB, MGR, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP (DNAME, (JOB, MGR))
ORDER BY DNAME, JOB, MGR;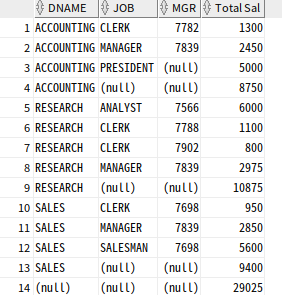
JOB+MGR을 하나의 집합으로 간주
3. CUBE 함수
CUBE : 결합 가능한 모든 값에 대해 다차원 집계를 생성
=> 시스템에 많은 부담
=> 표시된 인수 간 평등한 관계 이므로 순서 바뀌어도 결과 같음
--cube 함수 이용
SELECT
CASE GROUPING(DNAME) WHEN 1 THEN 'All Departments' ELSE DNAME END AS DNAME,
CASE GROUPING(JOB) WHEN 1 THEN 'All Jobs' ELSE JOB END AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE (DNAME, JOB)
ORDER BY DEPT.DNAME, EMP.JOB;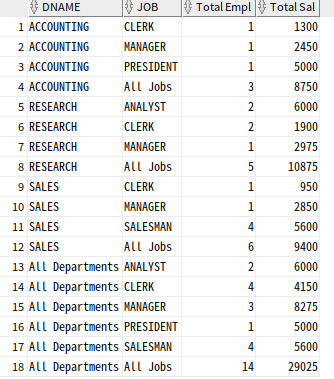
CUBE는 모든 경우의 수에 대한 subtotal을 생성하므로 columns 수가 N인 경우 2의 N승 레벨의 subtotal 생성
SELECT DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME, JOB
UNION ALL
SELECT DNAME, 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments', JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB
UNION ALL
SELECT 'All Departments', 'All Jobs', COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO ;UNION ALL과 위의 CUBE SQL은 같은 결과
=> 테이블 네 번 반복 액세스, 가독성 및 수행속도, 자원 사용률 등 cube함수 사용해 개선
4. GROUPING SETS 함수
GROUPING SETS : group by 문장을 여러번 반복하지 않아도 원하는 결과 얻음
=> 표시된 인수 간에는 평등한 관계이므로 순서 바뀌어도 결과 가틍ㅁ
-- 부서별, job별 인원수와 급여 합
SELECT DNAME, 'All Jobs' JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME
UNION ALL
SELECT 'All Departments' DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal" FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY JOB ;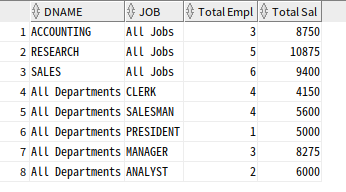
-- grouping sets 함수 사용
SELECT
DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB)
ORDER BY DEPT.DNAME, EMP.JOB;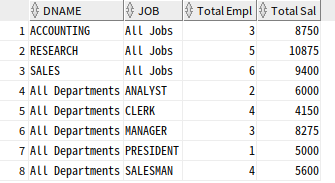
SELECT DNAME, JOB, MGR, COUNT(*) AS EMP_CNT, SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS ((DNAME, JOB, MGR), (DNAME, JOB), (JOB, MGR));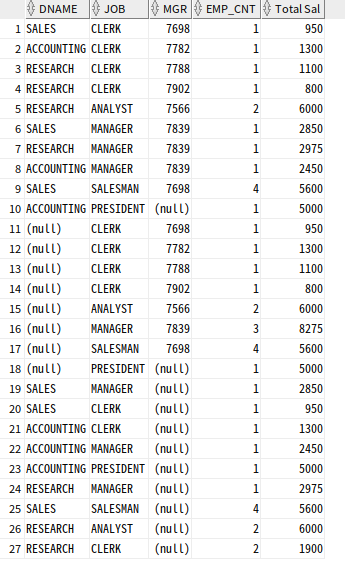
(DNAME+JOB+MGR) 기준 집계, (DNAME+JOB) 기준 집계, (JOB+MGR) 기준 집계가 나옴
🌮윈도우 함수
1. 윈도우 함수 개요
WINDOW FUNCTION : 행과 행간의 관계를 쉽게 정의하기 위해 만든 함수
=> 다른 함수와 달리 중첩해서 사용 불가
=> 서브쿼리에 사용 가능
윈도우 함수 종류
순위(RANK) 함수
: rank, dense_rank, row_number
집계(AGGREGATE) 함수
: sum, max, min, avg, count
(sql server는 집계함수 내 order by 지원 X)
그룹 내 행 순서 함수
: first_value, last_value, lag, lead
그룹 내 비율 함수
: cume_dist, percent_rank, ntile, ratio_to_report
통계 분석 함수
: stddev, corr, variance
WINDOW FUNCTION SYNTAX
윈도우 함수에는 OVER 키워드로 필수
select
window_function(arguments) over ([partition by 칼럼] [order by 절] [windowing 절])
from 테이블명;window_function: window 함수용으로 추가된 함수와 기존에 사용하던 함수arguments(인수):0~N개의 인수 지정partition by 절: 전체 집합을기준에 따라소그룹으로 나눌 수 있음order by 절: 어떤항목에 대해순위를 지정할지 기술windowing 절: 함수의 대상이 되는행 기준의범위지정
Rows
: 행 자체가 기준
ex. rows between current row and unbounded following; -- 현재 행부터 끝까지
Range
: 행이 가진 데이터 기준
ex. range between 10 preceding and current row; -- 현재 행이 가진 값보다 10만큼 작은 행부터 현재 행까지 (≒ range 10 preceding)
[BETWEEN 사용 타입]
ROWS | RANGE BETWEEN UNBOUNDED PRECEDING | CURRENT ROW | VALUE_EXPR PRECEDING/FOLLOWING
AND UNBOUNDED FOLLOWING | CURRENT ROW | VALUE_EXPR PRECEDING/FOLLOWING
[BETWEEN 미사용 타입]
ROWS | RANGE UNBOUNDED PRECEDING | CURRENT ROW | VALUE_EXPR PRECEDINGunbounded following : 아래쪽 끝 행
n preceding / n following : 현재 행에서 위로 n / 아래로 n
2. 그룹 내 순위 함수
RANK 함수
RANK : order by를 포함한 쿼리 문에서 특정 항목(칼럼)에 대한 순위를 구하는 함수
=> 동일한 값은 동일한 순위
--전체 급여 순서, job별 급여 순서
SELECT JOB, ENAME, SAL,
RANK( ) OVER (ORDER BY SAL DESC) ALL_RANK,
RANK( ) OVER (PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK
FROM EMP;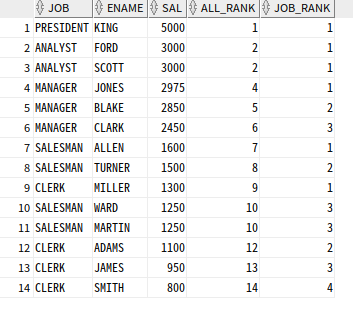
DENSE_RANK 함수
DENSE_RANK : 동일한 순위를 하나의 건수로 취급
SELECT JOB, ENAME, SAL,
RANK( ) OVER (ORDER BY SAL DESC) RANK,
DENSE_RANK( ) OVER (ORDER BY SAL DESC) DENSE_RANK
FROM EMP;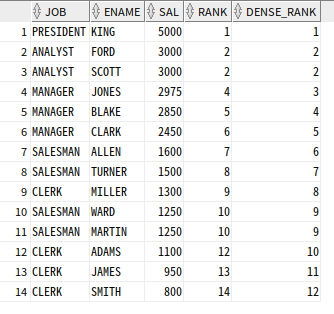
ROW_NUMBER 함수
ROW_NUMBER : 동일한 값이라도 고유한 순위 부여
SELECT JOB, ENAME, SAL,
RANK( ) OVER (ORDER BY SAL DESC) RANK,
ROW_NUMBER() OVER (ORDER BY SAL DESC) ROW_NUMBER
FROM EMP;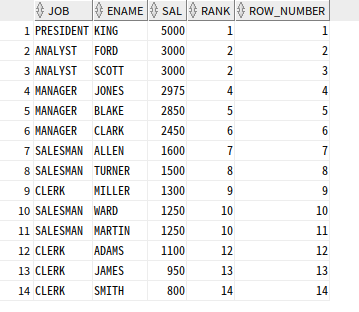
3. 일반 집계함수
SUM 함수
SUM함수 : 파티션별 윈도우 합
--mgr별 합계
SELECT MGR, ENAME, SAL,
SUM(SAL) OVER (PARTITION BY MGR) MGR_SUM
FROM EMP;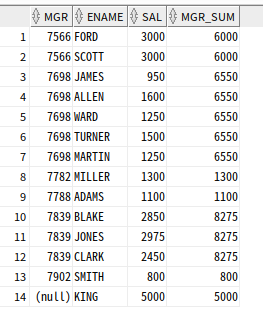
--누적 합계
SELECT MGR, ENAME, SAL,
SUM(SAL) OVER (PARTITION BY MGR ORDER BY SAL RANGE UNBOUNDED PRECEDING) as MGR_SUM
FROM EMP; range unbounded preceding : 현재 행 기준으로 파티션 내의 첫 번째 행 까지 범위 지정
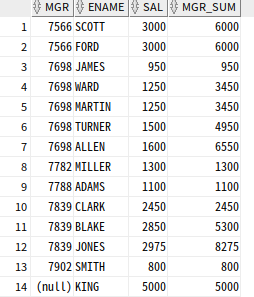
sal이 같은 것은 같은 order로 취급해 950+1250+1250으로 3450이 표시
MAX 함수
MAX함수 : 파티션별 윈도우 최댓값
SELECT MGR, ENAME, SAL, MAX(SAL) OVER (PARTITION BY MGR) as MGR_MAX
FROM EMP;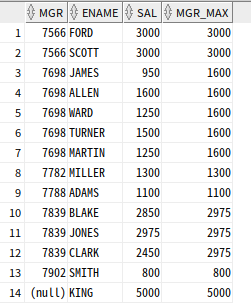
-- 파티션별 최댓값을 가진 행 추출
select mgr, ename, sal
from (select mgr, ename, sal
, rank() over(partition by mgr order by sal desc) as sal_rk
from emp)
where sal_rk=1;
-- where sal=max_sal로 max(sal) over()을 통해 구할 수 있으나 성능 저하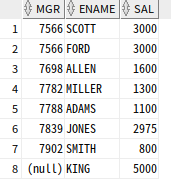
MIN 함수
MIN함수 : 파티션별 윈도우 최솟값
SELECT MGR, ENAME, HIREDATE, SAL,
MIN(SAL) OVER(PARTITION BY MGR ORDER BY HIREDATE) as MGR_MIN
FROM EMP;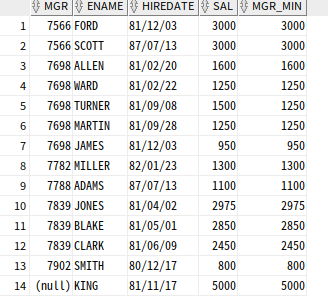
order by 때문에 hiredate 기준으로 정렬이 되어 범위가 없기 때문에 본인이 min(sal)로 나옴
AVG 함수
AVG함수 : 파티션별 ROWS 윈도우로 통곗값
--앞의 한건, 본인, 뒤의 한 건 범위
SELECT MGR, ENAME, HIREDATE, SAL,
ROUND (AVG(SAL) OVER (PARTITION BY MGR
ORDER BY HIREDATE ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) as MGR_AVG
FROM EMP;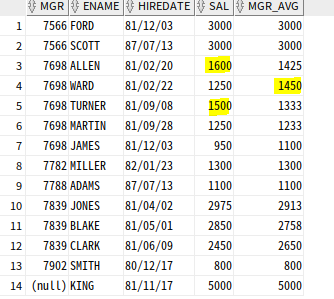
COUNT 함수
COUNT함수 : 파티션별 ROWS 윈도우로 통곗값
-- 급여가 -50~ +150 사이인 것의 개수
SELECT ENAME, SAL,
COUNT(*) OVER
(ORDER BY SAL RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) as SIM_CNT
FROM EMP;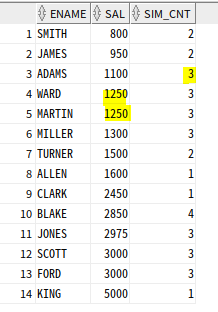
ADAMS는 1100인데 1050~1250까지의 개수를 구하는데, 이때 자신을 포함해서 개수를 구함
4. 그룹 내 행 순서 함수
FIRST_VALUE 함수
FIRST_VALUE : 파티션별 윈도우에서 가장 먼저 나온 값
=> SQL server에서 지원 X
=> MIN 함수로 같은 결과 얻기 가능
SELECT DEPTNO, ENAME, SAL,
FIRST_VALUE(ENAME)
OVER (PARTITION BY DEPTNO ORDER BY SAL DESC ROWS UNBOUNDED PRECEDING) as DEPT_RICH
FROM EMP;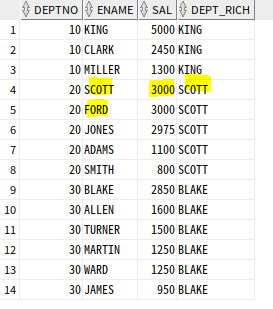
최고 급여를 받는 사람이 두 명인 경우, 누가 최고 급여자로 선택될 지는 SQL문만 갖고는 판단 불가
FIRST_VALUE는 공동 등수 인정X, 처음 나온 행만 처리
LAST_VALUE 함수
LAST_VALUE : 파티션별 윈도우에서 가장 나중에 나온 값
=> SQL server에서 지원 X
=> MAX 함수로 같은 결과 얻기 가능
-- 현재 행부터 마지막 행까지 범위로 연봉 높은 순 정렬 중 가장 마지막 나온 값 출력
SELECT DEPTNO, ENAME, SAL,
LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) as DEPT_POOR
FROM EMP;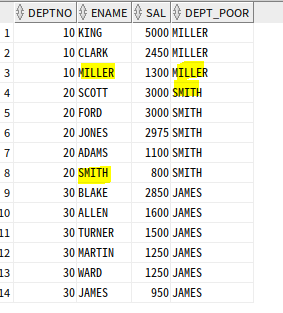
LAST_VALUE는 공동 등수 인정X, 가장 나중에 나온 행만 처리
LAG 함수
LAG : 파티션별 윈도우에서 이전 몇 번째 행의 값 가져옴
--자신보다 입사일자가 한명 앞선 사원의 급여
SELECT ENAME, HIREDATE, SAL,
LAG(SAL) OVER (ORDER BY HIREDATE) as PREV_SAL
FROM EMP
WHERE JOB = 'SALESMAN' ;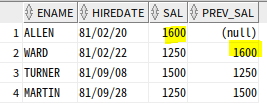
LAG함수의 인자는 3개까지 있다.
두번째는 몇 번째 앞의 행을 가져올지 정하는 것이며(기본값 1), 세 번째 인자는 NULL값일 경우 다른 값으로 바꾸는 기능이다.
SELECT ENAME, HIREDATE, SAL,
LAG(SAL,2,0) OVER (ORDER BY HIREDATE) as PREV_SAL
FROM EMP
WHERE JOB = 'SALESMAN' ;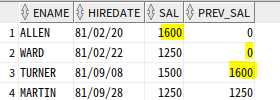
LEAD 함수
LEAD : 파티션별 윈도우에서 이후 몇 번째 행의 값 가져옴
-- 바로 다음에 입사한 인력의 입사일자 구함
SELECT ENAME, HIREDATE,
LEAD(HIREDATE, 1) OVER (ORDER BY HIREDATE) as "NEXTHIRED"
FROM EMP;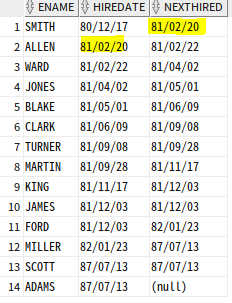
LEAD함수도 LAG와 똑같이 인자가 3개까지 가능함
5. 그룹 내 비율 함수
RATIO_TO_REPORT 함수
RATIO_TO_REPORT : 파티션 내 전체 SUM(칼럼) 값에 대한 행별 칼럼 값의 백분율을 소수점으로 구함
=> >0 & <=1의 범위
=> 개별 ratio의 합은 1
=> SQL server 지원 X
SELECT ENAME, SAL,
ROUND(RATIO_TO_REPORT(SAL) OVER (), 2) as R_R
FROM EMP
WHERE JOB = 'SALESMAN';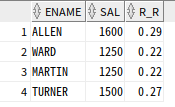
각각 SAL 총합인 5600으로 자신의 급여를 나눈 것과 같다. (ex. 1600/5600=0.29)
PERCENT_RANK 함수
PERCENT_RANK : 파티션별 윈도우에서 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 해, 값이 아닌 행의 순서별 백분율
=> >=0 & <=1의 범위
=> SQL Server 지원 X
SELECT DEPTNO, ENAME, SAL,
PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) as P_R
FROM EMP;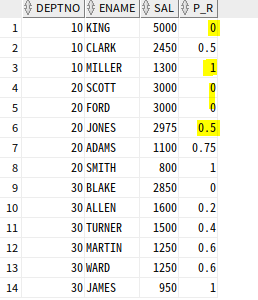
0과 1을 4구간으로 나누면 0,0.25,0.5,0.75,1인데 scott과 ford는 같으므로 둘다 0 0 으로 하고 0.25가 없고 0.5로 바로 넘어간다
즉, 급여가 같으면 같은 order로 취급
CUME_DIST 함수
CUME_DIST : 파티션별 윈도우의 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율
=> >0 & <=1의 범위
=> SQL Server 지원 X
--본인 급여가 누적 순서상 몇 번째 위치하는지
SELECT DEPTNO, ENAME, SAL,
CUME_DIST() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) as CUME_DIST
FROM EMP;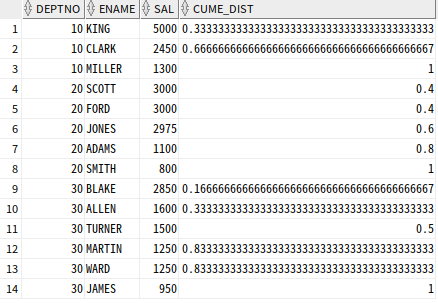
deptno가 20인 경우, 윈도우가 전체 5건 이므로 0.2 단위의 간격을 가진다.
scott과 ford는 같은 order로 취급한다
다른 window 함수는 동일 순서면 앞 행의 결과 값을 따르지만, cume_dist는 동일 순서면 뒤 행의 함수 결과 값을 기준으로 함
NTILE 함수
NTILE : 파티션별 전체 건수를 argument값으로 n등분한 결과를 구함
SELECT ENAME, SAL,
NTILE(4) OVER (ORDER BY SAL DESC) as QUAR_TILE
FROM EMP;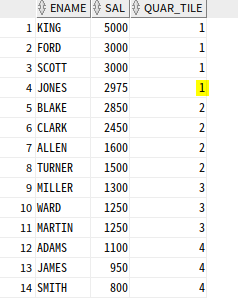
14명을 4개 조로 나누면 몫이 3명, 나머지가 2명인데 나머지 두명은 앞 조부터 할당
🌯Top N 쿼리
1. ROWNUM 슈도 칼럼
ROWNUM : SQL 처리 결과 집합의 각 행에 임시로 부여되는 일련번호
=> rownum=n처럼 사용 불가
-- 급여가 높은 3명만 추출
select ename, sal
from (select ename, sal
from emp
order by sal desc)
where rownum<=3;
--급여가 많은 순으로 정렬한 후, 앞에서부터 상위 3건을 출력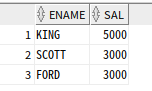
2. TOP 절
SQL Server는 TOP 절을 사용해 행의 수 제한 가능
TOP (Expression) [PERCENT] [WITH TIES]Expression: 반환할행 수PERCENT: 쿼리 결과 집합에서처음 expression%의 행만 반환WITH TIES:order by절이 지정된 경우만 사용 가능,top n(percent)의마지막 행과같은 값이 있는 경우추가 행 출력 가능 지정
select top(2) ename, sal
from emp
order by sal desc;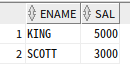
select top(2) with ties ename, sal
from emp
order by sal desc;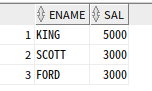
3. ROW LIMITING 절
ROW LIMITING
=> ORDER BY절 다음에 기술
=> order by절과 함께 수행
=> row와 rows는 구분 X
=> 오라클 12.1 이상, sql server 2012버전부터 지원
[OFFSET offset {row|rows}]
[fetch {first|next} [{rowcount|percent PERCENT}] {row|rows} {only | with ties}]OFFSET offset:건너뛸 행의개수지정 (ex. offset 5)FETCH:반환할 행의 개수나백분율ONLY: 지정된 행의 개수나 백분율만큼행을 반환WITH TIES: 마지막 행에 대한동순위 포함해 반환
select empno, sal
from emp
order by sal, empno
fetch first 5 rows only;-- 건너뛴 행 이후의 전체 행 반환 (5개 행 건너뜀)
select empno, sal
from emp
order by sal, empno
offset 5 rows;🥫계층형 질의와 셀프 조인
1. 개요
계층형 데이터 : 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터
=> 계층형 질의(Hierarchical Query)를 사용해 조회
=> 셀프 조인을 사용해 조회
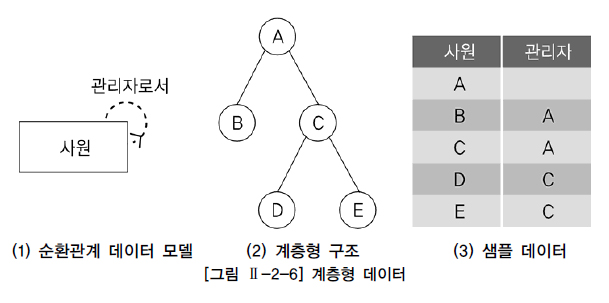
2. 셀프 조인
셀프 조인(Self Join) : 동일 테이블 사이의 조인
=> from절에 동일 테이블이 두 번 이상 나타남
=> 테이블과 칼럼 이름이 동일하므로 반드시 테이블 alias를 사용해야 함
SELECT ALIAS명1.칼럼명, ALIAS명2.칼럼명, ...
FROM 테이블1 ALIAS명1, 테이블2 ALIAS명2
WHERE ALIAS명1.칼럼명2 = ALIAS명2.칼럼명1;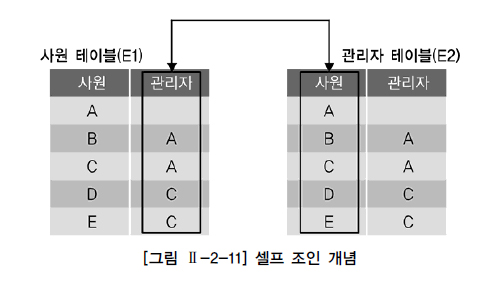
자신과 상위, 차상위 관리자를 같은 줄에 표시하기 위해선 from절에 사원 테이블이 두 번 나와야 함
SELECT WORKER.ID 사원번호, WORKER.NAME 사원명, MANAGER.NAME 관리자명
FROM EMP WORKER, EMP MANAGER
WHERE WORKER.MGR = MANAGER.EMPNO --매니저 사원번호가 사원의 매니저번호;-- JONES의 자식노드(7788, 7902), 자식노드의 자식노드 조회
select c.empno, c.ename, c.mgr
from emp a, emp b, emp c
where a.ename='JONES'
and b.mgr=a.empno
and c.mgr=b.empno;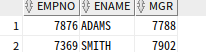
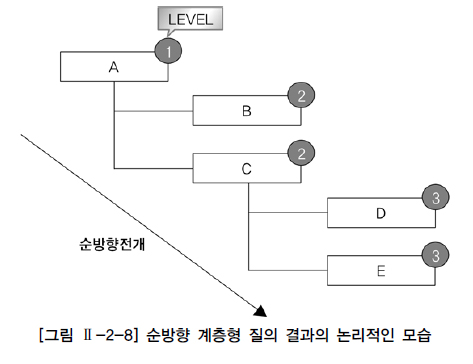
순방향 전개 : 자식 노드의 자식 노드를 조회하는 전개 방식
--SMITH의 부모 노드(7902, 매니저 번호 7566)의 부모 노드 조회
select c.empno, c.ename, c.mgr
from emp a, emp b, emp c
where a.ename='SMITH'
and b.empno=a.mgr
and c.empno=b.mgr;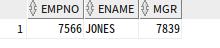
역방향 전개 : 부모 노드의 부모 노드를 조회하는 전개 방식
3. 계층형 질의
Oracle 계층형 질의

START WITH 절: 계층 구조 전개의시작 위치지정,루트 데이터지정CONNECT BY 절: 다음에 전개될자식 데이터지정, 자식 데이터는connect by절에 주어진 조건을 만족해야 함 (조인)PRIOR:connect by절에 사용
=>순방향 전개:prior 자식 = 부모이면부모 데이터에서자식 데이터방향으로 전개
=>역방향 전개:prior 부모 = 자식이면자식 데이터에서부모 데이터방향으로 전개NOCYCLE: 데이터를 전개하면서이미 나타났던 동일한 데이터가 전개 중 다시 나타나는 경우를CYCLE이라고 하는데, 발생하면 런타임 오류가 발생하여 nocycle을 추가해주면사이클 발생 이후데이터 전개 XORDER SIBLINGS BY:형제 노드사이에정렬수행WHERE:모든 전개를 수행한 후에 지정된 조건 만족 데이터만 추출

SELECT LEVEL, LPAD(' ', 4 * (LEVEL-1)) || empno, mgr,
CONNECT_BY_ISLEAF ISLEAF
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno= mgr;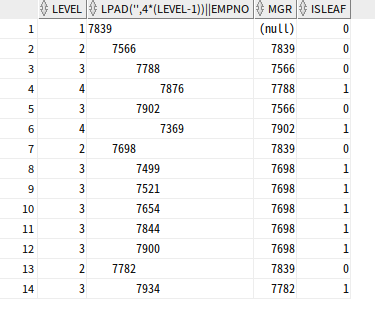
7839는 루트 데이터 이므로 레벨 1이며, 관리자->사원으로 전개하므로 순방향 전개
-- 사원 7876부터 자신의 상위 관리자를 찾는 역방향 전개
SELECT LEVEL, LPAD(' ', 4 * (LEVEL-1)) || empno, mgr,
CONNECT_BY_ISLEAF ISLEAF
FROM emp
START WITH empno=7876
CONNECT BY PRIOR mgr=empno;
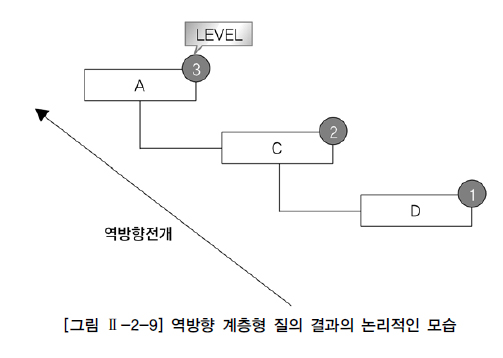
7876은 루트 데이터 이므로 레벨 1이며, 하위 데이터에서 상위 데이터로 전개하므로 역방향 전개

SELECT
CONNECT_BY_ROOT (empno) as root_empno,
SYS_CONNECT_BY_PATH(empno, ',') 경로, empno, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;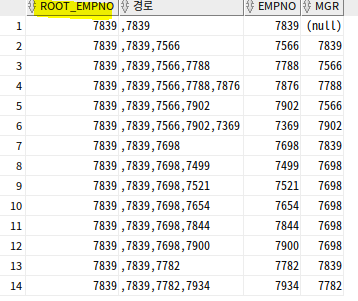
SQL Server 계층형 질의
USE NORTHWIND
GO
SELECT EMPLOYEEID, LASTNAME, FIRSTNAME, REPORTSTO
FROM EMPLOYEES
GO
**************************************************************************
EmployeeID LastName FirstName ReportsTo
--------- -------- ------- --------
1 Davolio Nancy 2
2 Fulle Andrew NULL -- 최상위
3 Leverling Janet 2
4 Peacock Margaret 2
5 Buchanan Steven 2
6 Suyama Michael 5
7 King Robert 5
8 Callahan Laura 2
9 Dodsworth Anne 5ReportsTo 칼럼이 상위 사원에 해당
-- CTE(Common Table Expression)를 재귀호출해 순방향 전개
WITH EMPLOYEES_ANCHOR AS (
SELECT EMPLOYEEID, LASTNAME, FIRSTNAME, REPORTSTO, 0 AS LEVEL
FROM EMPLOYEES
WHERE REPORTSTO IS NULL /* 재귀 호출의 시작점 */
UNION ALL
SELECT R.EMPLOYEEID, R.LASTNAME, R.FIRSTNAME, R.REPORTSTO, A.LEVEL + 1
FROM EMPLOYEES_ANCHOR A, EMPLOYEES R
WHERE A.EMPLOYEEID = R.REPORTSTO )
SELECT LEVEL, EMPLOYEEID, LASTNAME, FIRSTNAME, REPORTSTO
FROM EMPLOYEES_ANCHOR
GO
**************************************************************************
Level EmployeeID LastName FirstName ReportsTo
---- -------- ------- ----- --------
0 2 Fuller Andrew NULL
1 1 Davolio Nancy 2
1 3 Leverling Janet 2
1 4 Peacock Margaret 2
1 5 Buchanan Steven 2
1 8 Callahan Laura 2
2 6 Suyama Michael 5
2 7 King Robert 5
2 9 Dodsworth Anne 5
(9개 행 적용됨)UNION ALL로 쿼리 두 개를 결합했는데, 위에 있는 쿼리를 앵커 멤버(Anchor Member), 아래에 있는 쿼리를 재귀 멤버(Recursive Member)라고 함
재귀적 쿼리의 처리 과정
CTE식을앵커 멤버와재귀 멤버로 분할앵커 멤버를 실행해첫 번째 호출또는기본 결과 집합(T0)을 생성Ti는 입력으로 사용하고,Ti+1은 출력으로 사용해재귀 멤버실행빈 집합이 반환될 때 까지 반복결과 집합을 반환,T0에서Tn까지의UNION ALL
CTE 정렬을 위해선 정렬용 칼럼 sort를 추가하고, 쿼리 마지막에 order by를 추가하자
WITH T_EMP_ANCHOR AS (
SELECT EMPLOYEEID, MANAGERID, 0 AS LEVEL,
CONVERT(VARCHAR(1000), EMPLOYEEID) AS SORT
FROM T_EMP
WHERE MANAGERID IS NULL /* 재귀 호출의 시작점 */
UNION ALL
SELECT R.EMPLOYEEID, R.MANAGERID, A.LEVEL + 1
CONVERT(VARCHAR(1000), A.SORT + '/' + R.EMPLOYEEID) AS SORT
FROM T_EMP_ANCHOR A, T_EMP R
WHERE A.EMPLOYEEID = R.MANAGERID )
SELECT LEVEL, REPLICATE(' ', LEVEL) + EMPLOYEEID AS EMPLOYEEID, MANAGERID, SORT
FROM T_EMP_ANCHOR
ORDER BY SORT GO
Level EmployeeID ManagerID Sort
---- -------- -------- -------------
0 1000 NULL 1000
1 1100 1000 1000/1100
2 1110 1100 1000/1100/1110
...🍖PIVOT 절과 UNPIVOT 절
1. 개요
PIVOT : 행을 열로 회전
UNPIVOT : 열을 행으로 회전
2. PIVOT 절
PIVOT : 행을 열로 전환
PIVOT [XML]
(aggregate_function (expr) [[AS] alias]
[, (aggregate_function (expr) [[AS] alias]] ...
FOR {column | (column[, column]...)}
IN ({{{expr|expr[,expr]...)} [[AS] alias]} ...
| subquery
| ANY [, ANY] ...
})
)aggregate_function: 집계할열FOR절:PIVOT할열지정IN절:PIVOT할열 값지정
PIVOT절은 집계함수와 FOR절에 지정되지 않은 열을 기준으로 집계되므로 인라인 뷰를 통해 사용할 열 지정해야 함
SELECT *
FROM (SELECT JOB, DEPTNO, SAL FROM EMP)
PIVOT (SUM(SAL) FOR DEPTNO IN (10,20,30))
ORDER BY 1;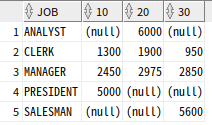
deptno가 열로 간 것을 확인
-- in절에 별칭을 지정시 열 명이 변경
select *
from (select job, deptno, sal from emp)
pivot (sum(sal) as sal for deptno in (10 as d10, 20 as d20, 30 as d30))
order by 1;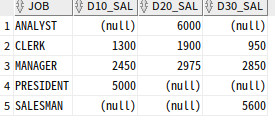
집계함수와 IN절 별칭 규칙
| 10 | 10 AS d10 | |
|---|---|---|
| sum(sal) | 10 | d10 |
| sum(sal) as sal | 10_sal | d10_sal |
select *
from (select to_char(hiredate,'YYYY') as YYYY, job, deptno, sal from emp)
pivot(sum(sal) as sal, count(*) as cnt
for (deptno, job) in ((10,'ANALYST') as d10a, (10,'CLERK') as d10c,
(20,'ANALYST') as d20a, (20,'CLERK') as d20c))
order by 1;
PIVOT절을 사용할 수 없는 경우 집계함수와 CASE표현식으로 PIVOT 가능
SELECT JOB
,SUM(CASE DEPTNO WHEN 10 THEN SAL END) AS D10_S
,SUM(CASE DEPTNO WHEN 20 THEN SAL END) AS D20_S
,SUM(CASE DEPTNO WHEN 30 THEN SAL END) AS D30_S
FROM EMP
GROUP BY JOB
ORDER BY JOB;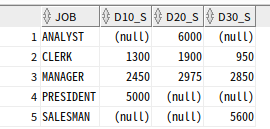
2. UNPIVOT 절
UNPIVOT : 열이 행으로 전환
UNPIVOT [{INCLUDE | EXCLUDE} nulls]
( {column|column[,col] ...)}
FOR {column|column[,col] ...)}
IN {column|column[,col] ...)} [AS {literal | (literal [, literal] ... )}]
[, {column|column[,col] ...)} [AS {literal | (literal [, literal] ... )}]]...
)
)unpivot column절:unpivot된값이 들어갈열지정for절:unpivot된값을설명할 값이 들어갈열지정IN절:unpivot할열과설명할 값의리터럴 값지정
--테이블 생성
create table t1 as
select job, d10_sal, d20_sal, d10_cnt, d20_cnt
from (select job, deptno, sal from emp where job in ('ANALYST', 'CLERK'))
pivot (sum(sal) as sal, count(*) as cnt for deptno in (10 as d10, 20 as d20));
SELECT JOB
,DEPTNO
,SAL
FROM T1
UNPIVOT(SAL FOR DEPTNO IN (D10_SAL, D20_SAL))
ORDER BY 1,2;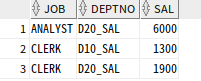
d10_sal, d20_sal 열이 행으로 전환
SELECT JOB
,DEPTNO
,SAL
FROM T1
UNPIVOT(SAL FOR DEPTNO IN (D10_SAL as 10, D20_SAL as 20))
ORDER BY 1,2;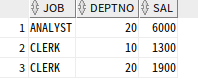
IN절에 별칭을 지정하면 열의 값을 변경 가능
SELECT JOB
,DEPTNO
,SAL
FROM T1
UNPIVOT include nulls (SAL FOR DEPTNO IN (D10_SAL as 10, D20_SAL as 20))
ORDER BY 1,2;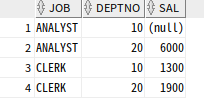
include nulls : unpivot된 열의 값이 널인 행도 결과에 포함
SELECT *
FROM T1
UNPIVOT ((sal, cnt) for (deptno, dname) in ((d10_sal, d10_cnt) as (10, 'ACCOUNTING'),
(d20_sal, d20_cnt) as (20, 'RESEARCH')))
ORDER BY 1,2;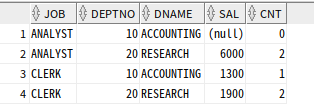
UNPIVOT을 사용할 수 없는 경우 카티션 곱을 이용해 unpivot 수행 가능
=> unpivot할 열 개수 만큼 행 복제하고, case 표현식으로 unpivot할 열 선택
select a.job,
case b.lv when 1 then 10 when 2 then 20 end as deptno,
case b.lv when 1 then a.d10_sal when 2 then a.d20_sal end as sal,
case b.lv when 1 then a.d10_cnt when 2 then a.d20_cnt end as cnt
from t1 a, (select level as lv from dual connect by level<=2) b
order by 1,2;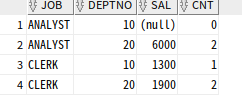
🍗정규 표현식
1. 개요
정규 표현식(regular expression) : 문자열의 규칙을 표현하는 검색 패턴
2. 기본 문법
POSIX 연산자
정규 표현식의 기본 연산자

REGEXP_SUBSTR : 문자열에서 일치하는 패턴 반환
select regexp_substr('aab','a.b') as c1,
regexp_substr('abb','a.b') as c2,
regexp_substr('acb','a.b') as c3,
regexp_substr('adc','a.b') as c4
from dual;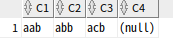
c4는 세번째 c가 세번째 b와 일치하지 않기 때문에 null 반환
select regexp_substr('a','a|b') as c1,
regexp_substr('b','a|b') as c2,
regexp_substr('c','a|b') as c3,
regexp_substr('ab','ab|cd') as c4,
regexp_substr('cd','ab|cd') as c5,
regexp_substr('bc','ab|cd') as c6,
regexp_substr('aa','a|aa') as c7,
regexp_substr('aa','aa|a') as c8
from dual;
or연산자는 기술 순서에 따라 패턴 일치
select regexp_substr('a|b','a|b') as c1,
regexp_substr('a|b','a\|b') as c2
from dual;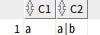
\로 인해 일반 문자로 처리됨
앵커(anchor) : 검색 패턴의 시작과 끝을 지정
| 연산자 | 영문 | 설명 |
|---|---|---|
| ^ | carrot | 문자열의 시작 |
| $ | dollar | 문자열의 끝 |
select regexp_substr('ab' || chr(10) || 'cd', '^.', 1, 1) as c1, -- 전체 문자열의 시작인 a
regexp_substr('ab' || chr(10) || 'cd', '^.', 1, 2) as c2, -- 전체 문자의 두 번째 시작 문자 존재 X
regexp_substr('ab' || chr(10) || 'cd', '.$', 1, 1) as c3, -- 전체 문자열의 끝 문자
regexp_substr('ab' || chr(10) || 'cd', '.$', 1, 2) as c4 -- 전체 문자열의 두 번째 끝 문자 존재 X
from dual;
-- regexp_substr( .. , .., 검색 위치, 패턴의 발생 횟수)
-- ex. 패턴의 발생횟수가 2라면, 두번째 발생위치 검색
-- 시작이 a인데, 시작이 2개일 수 없으므로 null
수량사(quantifier) : 선행 표현식의 일치 횟수 지정
=> 패턴을 최대로 일치시키는 탐욕적(greedy) 방식으로 동작

select regexp_substr('ac','ab?c') as c1, --ac 또는 abc 일치 가능
regexp_substr('abc','ab?c') as c2,
regexp_substr('abbc','ab?c') as c3,
regexp_substr('ac','ab*c') as c4, --ac, abc, abbc, abbbc, ...
regexp_substr('abc','ab*c') as c5,
regexp_substr('abbc','ab*c') as c6,
regexp_substr('ac','ab+c') as c7, -- abc, abbc, ...
regexp_substr('abc','ab+c') as c8,
regexp_substr('abbc','ab+c') as c9
from dual;
select regexp_substr('ab','a{2}') as c1, --aa
regexp_substr('aab','a{2}') as c2,
regexp_substr('aab','a{3,}') as c3, --aaa, aaaa,...
regexp_substr('aaab','a{3,}') as c4,
regexp_substr('aaab','a{4,5}') as c5, --aaaa, aaaaa
regexp_substr('aaaab','a{4,5}') as c6
from dual;
| 연산자 | 설명 |
|---|---|
| (expr) | 괄호 안의 표현식을 하나의 단위로 취급 |
select regexp_substr('ababc','(ab)+c') as c1, --abc, ababc,...
regexp_substr('ababc','ab+c') as c2, -- abc, abbc, ..
regexp_substr('abd','a(b|c)d') as c3, --abd, acd
regexp_substr('abd','ab|cd') as c4 --ab, cd
from dual;
역 참조(back reference) : 일치한 서브 표현식을 다시 참조 가능
=> 반복되는 패턴 검색 or 서브 표현식의 위치 변경 용도로 사용

select regexp_substr('abxab','(ab|cd)x\1') as c1, --abxab, cdxcd (cd 기준 시작 시 cd가 1번째 서브 표현식)
regexp_substr('cdxcd','(ab|cd)x\1') as c2,
regexp_substr('abxef','(ab|cd)x\1') as c3,
regexp_substr('ababab','(.*)\1+') as c4, -- 동일한 문자열이 1회 이상 반복되는 패턴 검색
regexp_substr('abcabc','(.*)\1+') as c5,
regexp_substr('adcabd','(.*)\1+') as c6
from dual;
문자 리스트(character list) : 문자를 대괄호로 묶은 표현식
=> 문자 리스트 중 한 문자만 일치하면 패턴 일치로 처리
=> 하이픈(-)은 범위 연산자로 동작

select regexp_substr('ac','[ab]c') as c1, --ac, bc
regexp_substr('bc','[ab]c') as c2,
regexp_substr('cc','[ab]c') as c3,
regexp_substr('ac','[^ab]c') as c4, --ac, bc가 아닌 문자열
regexp_substr('bc','[^ab]c') as c5,
regexp_substr('cc','[^ab]c') as c6
from dual;
select regexp_substr('1a','[0-9][a-z]') as c1, --ac, bc
regexp_substr('9z','[0-9][a-z]') as c2,
regexp_substr('aA','[^0-9][^a-z]') as c3,
regexp_substr('Aa','[^0-9][^a-z]') as c4
from dual;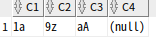
POSIX 문자 클래스

SELECT REGEXP_SUBSTR('gF1,','[[:digit:]]')AS C1
,REGEXP_SUBSTR('gF1,','[[:alpha:]]')AS C2
,REGEXP_SUBSTR('gF1,','[[:lower:]]')AS C3
,REGEXP_SUBSTR('gF1,','[[:upper:]]')AS C4
,REGEXP_SUBSTR('gF1,','[[:alnum:]]')AS C5
,REGEXP_SUBSTR('gF1,','[[:xdigit:]]')AS C6
,REGEXP_SUBSTR('gF1,','[[:punct:]]')AS C7
FROM DUAL;
PERL 정규 표현식 연산자

SELECT REGEXP_SUBSTR('(650) 555-0100','^\(\d{3}\) \d{3}-\d{4}$')AS C1
,REGEXP_SUBSTR('650-555-0100','^\(\d{3}\) \d{3}-\d{4}$')AS C2
,REGEXP_SUBSTR('b2b','\w\d\D')AS C3
,REGEXP_SUBSTR('b2_','\w\d\D')AS C4
,REGEXP_SUBSTR('b22','\w\d\D')AS C5
FROM DUAL;

패턴을 최소로 일치시키는 비탐욕적 방식으로 동작
select regexp_substr('aaaa','a??aa') as c1, --nongreedy
regexp_substr('aaaa','a?aa') as c2, --greedy
regexp_substr('xaxbxc','\w*?x\w') as c3, --\w*?를 0회로 측정
regexp_substr('xaxbxc','\w*x\w') as c4,
regexp_substr('abxcxd','\w+?x\w') as c5,
regexp_substr('abxcxd','\w+x\w') as c6
from dual;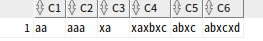
3. 정규 표현식 조건과 함수
REGEXP_LIKE 조건
REGEXP_LIKE : source_char이 pattern과 일치하면 true, 아니면 false 반환
REGEXP_LIKE(source_char, pattern [, match_param])source_char: 검색문자열지정pattern: 검색패턴지정match_param:일치 옵션지정
=> (i: 대소문자 무시,c: 대소문자 구분,n:dot(.)를 개행 문자와 일치,m: 다중 행 모드,x: 검색 패턴의 공백 문자 무시, 기본 값c)
select first_name, last_name
from HR.EMPLOYEES
where regexp_like (first_name,'^Ste(v|ph)en$');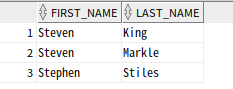
REGEXP_REPLACE 함수
REGEXP_REPLACE : source_char에서 일치한 pattern을 replace_string으로 변경한 문자값 반환
REGEXP_REPLACE(source_char, pattern[, replace_string[, position [, occurrence [, match_param]]]])replace_string:변경 문자열지정position: 검색시작 위치지정 (기본값 1)occurence: 패턴일치 횟수지정 (기본값 1)
-- 숫자3자리.숫자3자리.숫자4자리 패턴을 (첫 번째 일치) 두 번째 일치-세 번째 일치 형식으로 변경
select phone_number, regexp_replace(phone_number,
'([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})',
'(\1) \2-\3') as c1
from HR.employees
where employee_id in (144,145);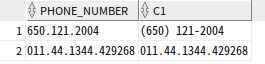
REGEXP_SUBSTR 함수
REGEXP_SUBSTR : source_char에서 일치한 pattern 반환
REGEXP_SUBSTR(source_char, pattern, [, position[, occurrence [, match_param [, subexpr]]]])subexpr:서브 표현식지정
=> (0: 전체 패턴,1이상: 서브 표현식, 기본값 0)
select regexp_substr('1234567890', '(123)(4(56)(78))', 1,1,'i',1) as c1,
regexp_substr('1234567890', '(123)(4(56)(78))', 1,1,'i',4) as c2 -- (78) 매칭
from dual;
REGEXP_INSTR 함수
REGEXP_INSTR : source_char에서 일치한 pattern의 시작 위치를 정수로 반환
REGEXP_INSTR(source_char, pattern [,position[, occurrence[, return_opt [, match_param [,subexpr]]]]])return_opt: 반환 옵션을 지정
=> (0: 시작 위치,1: 다음 위치, 기본값 0)
select regexp_instr('1234567890', '(123)(4(56)(78))', 1,1,0,'i',1) as c1,
regexp_instr('1234567890', '(123)(4(56)(78))', 1,1,0,'i',2) as c2,
regexp_instr('1234567890', '(123)(4(56)(78))', 1,1,0,'i',4) as c3
from dual;
REGEXP_COUNT 함수
REGEXP_COUNT : source_char에서 일치한 pattern의 횟수 반환
REGEXP_COUNT(source_char, pattern [, position [, match_param]])SELECT REGEXP_COUNT('123123123123123', '123',1) as c1,
REGEXP_COUNT('123123123123', '123',3) as c2 --3번째 부터 시작
FROM DUAL;
