📔설명
데이터베이스 아키텍처, SQL 처리 과정, 데이터베이스 I/O 메커니즘을 알아보자
🥡데이터베이스 아키텍처
1. 데이터베이스 구조
Oracle 구조
데이터베이스(Database) : 디스크에 저장된 데이터 집합(Datafile, Redo Log File, Control File 등)
인스턴스(Instance) : SGA 공유 메모리 영역과 이를 액세스 하는 프로세스 집합을 합쳐서 부름
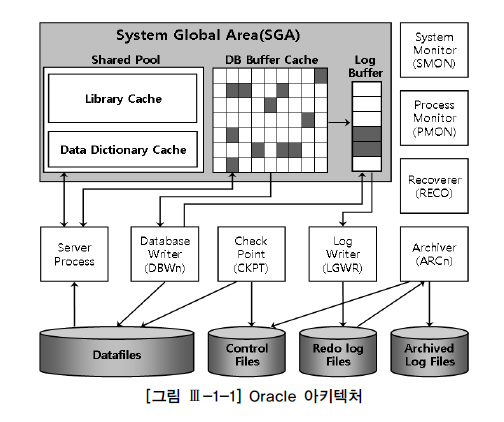
하나의 인스턴스가 하나의 데이터베이스만 액세스하지만, RAC(Real Application Cluster) 환경에선 여러 인스턴스가 하나의 데이터베이스를 액세스 가능
=> 하나의 인스턴스가 여러 데이터베이스를 액세스X
SQL Server 구조
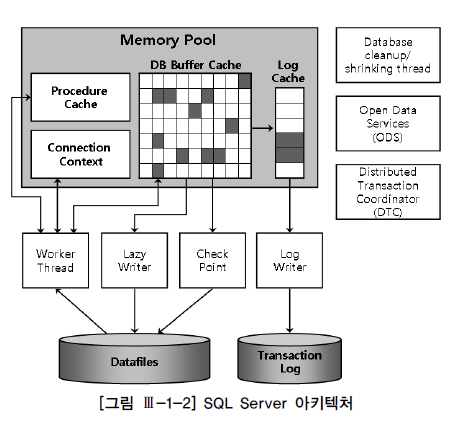
하나의 인스턴스당 최고 3만 2767개의 데이터베이스 정의해 사용 가능
기본적으로 master, model, msdb, tempdb 등의 시스템 데이터베이스가 만들어지며, 여기에 사용자 데이터베이스를 추가로 생성하는 구조
데이터베이스 하나를 만들 때마다 주 데이터 파일(main)과 트랜잭션 로그 파일이 하나씩 생김
=> 확장자는 각각 mdf, ldf, 보조 데이터 파일은 데이터가 많을 경우 추가 가능하며 확장자는 ndf
2. 프로세스
SQL Server는 쓰레드(Thread) 기반 아키텍처이므로 프로세스 대신 쓰레드라는 표현 사용
프로세스는 서버 프로세스와 백그라운드 프로세스 집합으로 나뉨
=> 서버 프로세스 : 전면에서 사용자로부터 전달받은 각종 명령 처리
=> 백그라운드 프로세스 : 뒤에서 묵묵히 할당받은 역할 수행
서버 프로세스
서버 프로세스 : 사용자 프로세스와 통신하면서 사용자의 각종 명령을 처리
=> SQL Server에선 Worker 쓰레드가 같은 역할 담당
=> SQL을 파싱하고 필요하면 최적화 수행
=> 커서를 열어 SQL을 실행하면서 블록을 읽어 이 데이터를 정렬해 클라이언트가 요청한 결과 집합을 만들어 네트워크를 통해 전송하는 작업 처리
=> 스스로 처리하도록 구현되지 않은 기능(ex. 데이터 파일로부터 DB 버퍼 캐시로 블록 적재, Dirty블록을 캐시에서 밀어냄으로써 Free블록 확보, Redo 로그 버퍼를 비우는 일)은 OS와 I/O 서브시스템, 백그라운드 프로세스가 대신 처리하도록 시스템 Call을 통해 요청
클라이언트가 서버 프로세스와 연결하는 방식
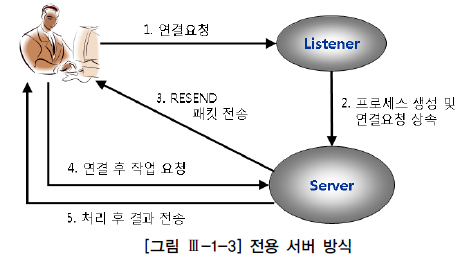
전용 서버 방식
: 처음 연결 요청을 받는리스너가서버 프로세스(쓰레드)를생성해주고, 이서버 프로세스가단 하나의사용자 프로세스를 위해전용 서비스를 제공
=>SQL을 수행할 때마다연결 요청시서버 프로세스의생성과 해제도 반복하므로 DBMS에 큰 부담과 성능 저하
=> 전용 서버 방식을 사용하는OLTP성 애플리케이션에선Connection Pooling 기법을 필수적으로 사용해야 함 (ex.50개 서버 프로세스와 연결된 50개사용자 프로세스를 공유해 반복 재사용)
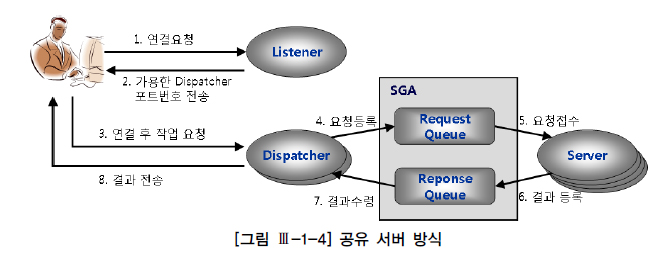
공유 서버 방식
:하나의 서버 프로세스를여러 사용자 세션이공유
=>Connection Pooling 기법을 DBMS 내부에 구현해 놓은 것으로 생각하면 쉬움
=> 미리여러 개의서버 프로세스를 띄어 놓고 이를공유해 반복 재사용
=>사용자 프로세스는서버 프로세스와직접 통신X,Dispatcher 프로세스를 거침
=>사용자 명령이Dispatcher에게 전달되면,Dispatcher는 이를SGA에 있는요청 큐(Request Queue)에 등록
=> 가장 먼저 가용한서버 프로세스가요청 큐에 있는사용자 명령을 꺼내서 처리하고, 그 결과를응답 큐(Response Queue)에 등록
=>응답 큐를모니터링하던Dispatcher가 응답 결과를 발견하면사용자 프로세스에게 전송
백그라운드 프로세스
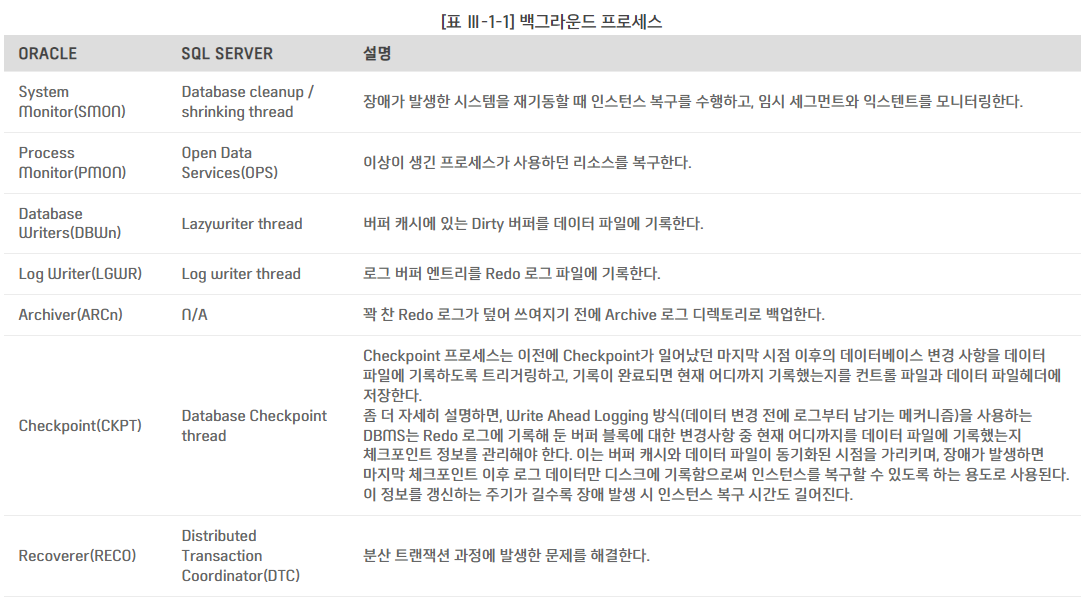
3. 데이터 저장 구조
데이터 파일

블록(=페이지) : DBMS에서 I/O 단위
=> 데이터를 읽고 쓸 때의 논리적인 단위
=> Oracle은 2KB, 4KB, 8KB, 16KB, 32KB 등 다양한 블록 크기 사용 가능
=> SQL Server는 8KB 사용
=> 블록 단위 I/O는 하나의 레코드에서 한 칼럼만 읽을 때도 레코드가 속한 블록 전체를 읽게 됨을 뜻함
=> 가장 중요한 성능지표는 액세스하는 블록 개수이며, 옵티마이저의 판단에 가장 큰 영향을 미치는 것도 액세스해야 할 블록 개수
익스텐트 : 테이블스페이스로부터 공간을 할당하는 단위
=> 테이블이나 인덱스에 데이터를 입력하다가 공간이 부족해지면 해당 오브젝트가 속한 테이블스페이스(물리적으론 데이터파일)로부터 추가적인 공간 할당
=> 정해진 익스텐트 크기의 연속된 블록 할당 (ex. 블록 크기가 8KB인 상태에서 64KB 단위로 익스텐트 할당하도록 정의시, 공간 부족할 때마다 테이블스페이스로부터 8개의 연속된 블록을 찾아(찾지 못하면 새로운 익스텐트 추가) 세그먼트에 할당
=> 익스텐트 내 블록은 논리적으로 인접, 익스텐트끼리는 서로 인접X
=> SQL Server의 익스텐트는 항상 64KB, 2개 이상의 오브젝트가 나누어 사용 가능
=> Oracle은 한 익스텐트에 속한 모든 블록을 단일 오브젝트가 사용
=> SQL Server의 2가지 타입 익스텐트
균일(Uniform) 익스텐트: 64KB이상의 공간을 필요로 하는 테이블이나 인덱스를 위해 사용, 8개의 페이지 단위로 할당된 익스텐트를단일 오브젝트가 모두 사용혼합(Mixed) 익스텐트: 한 익스텐트에 할당된 8개의 페이지를여러 오브젝트가 나누어 사용, 모든 테이블이 처음에는혼합 익스텐트로 시작하지만 64KB를 넘으면서 2번째부터균일 익스텐트를 사용하게 됨
세그먼트 : 테이블, 인덱스, Undo 처럼 저장공간을 필요로 하는 데이터베이스 오브젝트
=> SQL Server의 힙 구조/인덱스 구조 오브젝트가 여기 속함
=> 저장공간을 필요로 한다는 것은 한 개 이상의 익스텐트를 사용함을 뜻함
=> 테이블 생성시 내부적으로는 테이블 세그먼트가 생성
=> 인덱스 생성시 내부적으로는 인덱스 세그먼트가 생성
=> 다른 오브젝트는 세그먼트와 1:1 관계, 파티션은 1:M 관계 (파티션 테이블(또는 인덱스) 생성시, 내부적으로 여러 개의 세그먼트가 만들어짐)
=> 한 세그먼트는 자신이 속한 테이블스페이스 내 여러 데이터 파일에 걸쳐 저장 가능, 즉 세그먼트에 할당된 익스텐트가 여러 데이터 파일에 흩어져 저장되며 그래야 디스크 경합을 줄이고 I/O 분산 효과를 얻음
테이블스페이스(=파일 그룹) : 세그먼트를 담는 컨테이너
=> 여러 데이터 파일로 구성
=> 데이터는 물리적으로 데이터 파일에 저장 (사용자가 직접 데이터 파일 선택X)
=> 사용자는 세그먼트를 위한 테이블스페이스를 지정할 뿐, 실제 값을 저장할 데이터파일을 선택하고 익스텐트를 할당하는 것은 DBMS 몫
=> 각 세그먼트는 정확히 한 테이블스페이스에만 속함, 한 테이블스페이스에는 여러 세그먼트가 존재
=> 특정 세그먼트에 할당된 모든 익스텐트는 해당 세그먼트와 관련된 테이블스페이스 내에서만 찾아짐 ( 한 세그먼트가 여러 테이블스페이스에 걸쳐 저장X)
=> 한 세그먼트가 여러 데이터 파일에 걸쳐 저장O (한 테이블스페이스가 여러 데이터 파일로 구성되기 때문)
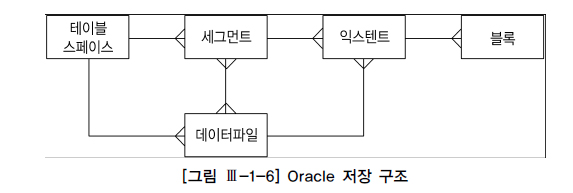
SQL Server는 한 익스텐트에 속한 모든 페이지를 2개 이상 오브젝트가 나누어 사용 가능
임시 데이터 파일
임시(Temporary) 데이터 파일 : 대량의 정렬이나 해시 작업을 수행하다가 메모리 공간 부족으로 인해 중간 결과 집합을 저장하는 용도
=> 임시로 저장했다가 자동으로 삭제됨
=> Redo 정보 생성X로 나중에 파일에 문제 발생 시 복구X, 백업 필요X
=> Oracle은 임시 테이블스페이스를 여러 개 생성해두고, 사용자마다 별도로 지정 가능
=> SQL Server는 단 하나의 tempdb 데이터베이스 사용, tempdb는 전역 리소스로서 시스템에 연결된 모든 사용자의 임시 데이터 저장
로그 파일
Redo로그/트랜잭션 로그 : DB 버퍼 캐시에 가해지는 모든 변경사항을 기록하는 파일
=> 변경된 메모리 버퍼 블록을 디스크상의 데이터 블록에 기록하는 작업은 Random I/O방식이므로 느림
=> 로그 기록은 Append 방식으로 이뤄지므로 빠름
=> 버퍼 블록에 대한 변경사항을 데이터 파일에 건건이 기록하기보다, 로그 파일에 Append방식으로 기록하는 방식 사용, 버퍼 블록과 데이터 파일간 동기화는 적절한 수단(DBWR, Checkpoint)을 이용해 나중에 배치(Batch) 방식으로 일괄 처리
=> Fast Commit : 사용자의 갱신 내용이 메모리상의 버퍼 블록에만 기록된 채 아직 디스크에 기록되지 않았더라도 Redo 로그를 믿고 빠르게 커밋을 완료
=> 인스턴스 장애가 발생하더라도, 로그 파일을 이용해 언제든 복구 가능하므로 안심하고 커밋 완료
-
Online Redo 로그:마지막 체크포인트이후부터사고 발생 직전까지 수행됐던 트랜잭션들을Redo 로그를 이용해재현(캐시 복구)
=>캐시에 저장된 변경사항이 아직데이터 파일에 기록되지 않은 상태에서 정전 등인스턴스가 비정상 종료되면, 작업내용을 모두 잃게 되는데, 유실에 대비하기 위해Online Redo 로그사용
=>최소 두 개 이상의 파일로 구성
=> 현재 사용중인 파일이꽉차면다음 파일로로그 스위칭(log switching)발생
=> 계속 로그를 쓰다가모든 파일이 꽉 차면다시 첫 번째 파일부터 재사용하는라운드 로빈(round-robin) 방식사용 -
트랜잭션 로그: Oracle의Online Redo 로그와 대응
=>주 데이터 파일마다(데이터베이스마다)트랜잭션 로그 파일이하나씩 생김
=> 확장자는ldf
=> 내부적으로가상 로그 파일이라는 더 작은 단위의세그먼트로 나뉘며,가상 로그 파일의 개수가너무 많아지지 않도록(즉조각화가 발생하지 않도록) 옵션 지정 (ex. 로그 파일을 애초에 넉넉한 크기로 만들어 자동 증가가 발생하지 않도록 하거나, 증가하는 단위를 크게 지정) -
Archived(=Offline) Redo 로그:Online Redo 로그가재사용되기 전에다른 위치로백업해 둔파일
=>디스크가 깨지는 등물리적인 저장 매체에 문제가 생긴 경우,데이터베이스(또는 미디어) 복구를 위해 사용
4. 메모리 구조
메모리 구조는 시스템 공유 메모리 영역과 프로세스 전용 메모리 영역으로 구분
-
시스템 공유 메모리 영역:여러 프로세스(쓰레드)가동시에액세스할 수 있는메모리 영역
=>Oracle-System Global Area(SGA),SQL Server-Memory Pool
=>공유 메모리를 구성하는캐시 영역에는DB 버퍼 캐시,공유 풀,로그 버퍼가 있음
=> 그 외에Large 풀,자바 풀등 포함,시스템 구조와제어 구조를캐싱하는영역포함
=>여러 프로세스와 공유되므로 내부적으로래치(Latch),버퍼 Lock,라이브러리 캐시 Lock/Pin같은액세스 직렬화 메커니즘사용 -
프로세스 전용 메모리 영역:서버 프로세스가 자신만의전용 메모리 영역을 가짐
=>Process Global Area(PGA)
=>데이터를정렬하고,세션과커서에 대한상태 정보 저장용도
=>SQL Server는쓰레드기반이라 프로세스 전용 메모리 영역 갖지X (쓰레드는전용 메모리 영역을 가질 수없고,부모 프로세스의메모리 영역을사용하기 때문)
DB 버퍼 캐시
DB 버퍼 캐시(DB Buffer Cache) : 데이터 파일로부터 읽어 들인 데이터 블록을 담는 캐시 영역
=> 인스턴스에 접속한 모든 사용자 프로세스는 서버 프로세스를 통해 DB 버퍼 캐시의 버퍼 블록을 동시에 액세스 가능 (버퍼 Lock을 통해 직렬화)
=> Direct Path Read 메커니즘이 작동하는 경우 제외, 모든 블록 읽기는 버퍼 캐시를 통함
=> 읽고자 하는 블록을 먼저 버퍼 캐시에서 찾아보고 없을 때 디스크에서 읽음
=> 디스크에서 읽을 때도 먼저 버퍼 캐시에 적재한 후에 읽음
=> 데이터 변경도 버퍼 캐시에 적재된 블록을 통해 이뤄지며, 변경된 블록(Dirty 버퍼 블록)을 주기적으로 데이터 파일에 기록하는 것은 DBWR 프로세스의 몫
=> 디스크 I/O : 물리적으로 액세스 암(Arm)이 움직이면서 헤드를 통해 이뤄짐
=> 메모리 I/O : 전기적 신호, 디스크 I/O에 비교할 수 없을 정도로 빠름
-
버퍼 블록의 상태
-Free 버퍼: 인스턴스 기동 후 아직 데이터가 읽히지 않아비어 있는 상태(Unused 버퍼)이거나, 데이터가 담겼지만데이터파일과동기화돼 있는 상태여서언제든지 덮어 써도 무방한 버퍼(Clean 버퍼)블록.데이터 파일로부터새로운 데이터 블록을 로딩하려면 먼저Free 버퍼를 확보해야 함.Free 상태인 버퍼에변경이 발생하면 그 순간Dirty 버퍼로 상태 변경
-Dirty 버퍼: 버퍼에 캐시된 이후변경이 발생했으나, 아직디스크에 기록되지 않아 데이터 파일 블록과동기화가 필요한 버퍼 블록. 이 블록이 다른 데이터 블록을 위해재사용되려면디스크에 먼저 기록돼야 하며,디스크에 기록하는 순간Free 버퍼로 상태 변경
-Pinned 버퍼:읽기또는쓰기작업이현재 진행 중인 버퍼 블록 -
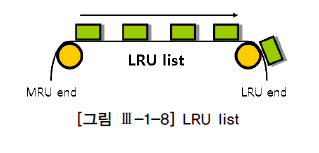
LRU 알고리즘: 버퍼 캐시는 유한한 자원으로, 모든 데이터를 캐싱할 수 없음.사용 빈도가 높은 데이터 블록 위주로버퍼 캐시가 구성되도록LRU(Least Recently Used)알고리즘 사용.모든 버퍼 블록 헤더를LRU 체인에 연결해서 사용빈도 순으로 위치를 옮겨가다가,Free 버퍼필요시액세스 빈도가 낮은 쪽부터 데이터 블록에서밀어냄
공유 풀
공유 풀(Shared Pool)은 딕셔너리 캐시와 라이브러리 캐시로 구성, LRU 알고리즘 사용
=> SQL Server에서는 프로시저 캐시(Procedure Cache)라고 함
-
딕셔너리 캐시
=>데이터베이스 딕셔너리(Dictionary): 테이블, 인덱스 같은오브젝트,테이블스페이스,데이터 파일,세그먼트,익스텐트,사용자,제약에 관한메타 정보를 저장하는 곳
=>딕셔너리 캐시:딕셔너리 정보를캐싱하는 메모리 영역
=> ex. 주문 테이블을 예로, 입력한주문 데이터는데이터 파일에 저장됐다가버퍼 캐시를 경유해 읽히지만,테이블 메타 정보는딕셔너리에 저장됐다가딕셔너리 캐시를 경유해 읽힘 -
라이브러리 캐시
=>라이브러리 캐시(Library Cache): 사용자가 수행한SQL문과실행계획,저장 프로시저를 저장해 두는 캐시영역
=>실행계획(Execution Plan): 사용자가SQL 명령어를 통해 결과 집합 요청시, 이를최적으로 수행하기 위한 처리 루틴 ( 빠른 쿼리 수행을 위해 내부적으로 생성한 일종의 프로시저 같은 것)
=>하드 파싱(Hard Parsing):쿼리 구문을 분석해서문법 오류및실행 권한체크,최적화(Optimization) 과정을 거쳐실행계획 생성,SQL 실행엔진이 이해할 수 있는 형태로포맷팅등의 전 과정
=> 특히최적화과정은하드 파싱을 무겁게 만드는 가장 결정적 요인이므로, 같은 SQL 처리시 해당 작업 반복 수행은매우 비효율적
=>같은 SQL에 대한반복적인 하드파싱을최소화하기 위한캐시 공간이 바로라이브러리 캐시 영역
로그 버퍼(=로그 캐시)
DB 버퍼 캐시에 가해지는 모든 변경사항을 로그파일에 기록하는데, 로그 엔트리도 파일에 곧바로 기록하는 것이 아니라 먼저 로그 버퍼(Log Buffer)에 기록
=> 일정량을 모았다가 기록하면 훨씬 빠르기 때문
서버 프로세스가 데이터 블록 버퍼에 변경을 가하기 전, Redo 로그 버퍼에 먼저 기록해두면 주기적으로 LGWR 프로세스가 Redo 로그 파일에 기록
변경이 가해진 Dirty 버퍼를 데이터 파일에 기록하기 전에 항상 로그 버퍼를 먼저 로그 파일에 기록해야만 함
=> 인스턴스 장애가 발생시 로그 파일에 기록된 내용을 재현해 캐시 블록을 복구하고, 최종적으로 커밋되지 않은 트랜잭션은 롤백해야 함
=> 로그 파일에 없는 변경내역이 이미 데이터 파일에 기록돼 있으면 사용자가 최종 커밋하지 않은 트랜잭션이 커밋되는 결과를 초래
=> Write Ahead Logging : 버퍼 캐시 블록을 갱신하기 전에 변경사항을 먼저 로그 버퍼에 기록해야 함. Dirty 버퍼를 디스크에 기록하기 전에 해당 로그 엔트리를 먼저 로그 파일에 기록하는 것
=> Log Force at Commit : 로그 버퍼를 주기적으로 로그 파일에 기록해야 하는데, 늦어도 커밋 시점에는 로그 파일에 기록해야 함. 메모리 상의 로그 버퍼는 언제든 유실될 가능성이 있기 때문
=> 로그를 이용한 Fast Commit이 가능한 이유는 로그를 이용해 언제든 복구 가능하기 때문이므로, 로그 파일에 기록했음이 보장돼야 안심하고 커밋 완료 가능
PGA
PGA : 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용
=> 래치 메커니즘이 필요 없어 SGA보다 훨씬 빠름
-
User Global Area(UGA)
=>전용 서버방식으로 연결하면프로세스와세션이1:1관계를 갖지만,공유 서버방식으로 연결하면1:M관계를 가짐. 즉,세션이프로세스개수보다많아질 수있는 구조로,하나의 프로세스가여러 세션을 위해 일함. 이때,각 세션을 위한독립적인 메모리 공간이 필요한데 이를UGA(User Global Area)라고 함
=>전용 서버 방식이라고 해서UGA를 사용하지 않는 것은 아니며,전용 서버 방식으로 연결시UGA는PGA에할당되고,공유 서버 방식으로 연결시SGA에할당 -
Call Global Area(CGA)
=>하나의 데이터베이스 Call을 넘어서다음 Call까지계속 참조돼야 하는 정보는UGA에 담고,Call이 진행되는 동안만 필요한데이터는CGA에 담는다
=>CGA는Parse Call,Execute Call,Fetch Call마다매번 할당
=>Call이 진행되는 동안Recursive Call이 발생시 그 안에서도Parse, Execute, Fetch단계별로CGA가추가 할당
=>CGA에 할당된 공간은하나의 Call이 끝나자마자해제돼PGA로 반환 -
Sort Area
=>데이터 정렬을 위해 사용
=>소트 오퍼레이션이 진행되는 동안공간이 부족해질 때마다청크(Chunk) 단위로 조금씩 할당
=>workarea_size_policy를auto로 설정 시 오라클이 내부적으로크기결정
=>PGA내에서Sort Area가 할당되는 위치는SQL 문 종류와소트 수행 단계에 따라 다름
=>DML 문장: 하나의execute call내에서모든 데이터 처리를완료하므로 sort Area가CGA에 할당
=>SELECT 문장:수행 중간 단계에 필요한 Sort Area는CGA에 할당,최종 결과 집합을 출력하기 직전 단계에 필요한 Sort Area는UGA에 할당
=>SQL Server는데이터 정렬을Memory Pool안에 있는버퍼 캐시에서 수행,세션 관련 정보는Memory Pool안에 있는Connection Context 영역에 저장
🍱SQL 처리 과정
1. 구조적, 집합적, 선언적 질의 언어
SQL(Structured Query Language) : 구조적 질의 언어
=> 구조적(Structured)이고 집합적(set-based)이고 선언적(declarative)인 질의 언어
=> 원하는 결과 집합을 구조적/집합적으로 선언하지만, 그 결과 집합을 만드는 과정은 절차적일 수 밖에 없어 프로시저가 필요한데, 이 프로시저를 만들어내는 DBMS 내부 엔진이 바로 SQL 옵티마이저
2. SQL 처리 과정
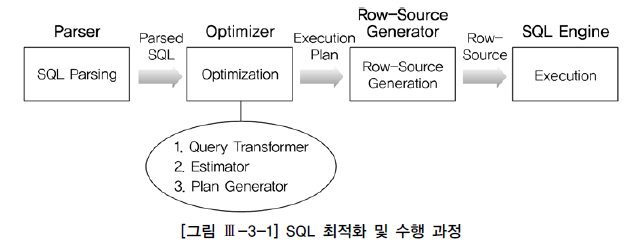
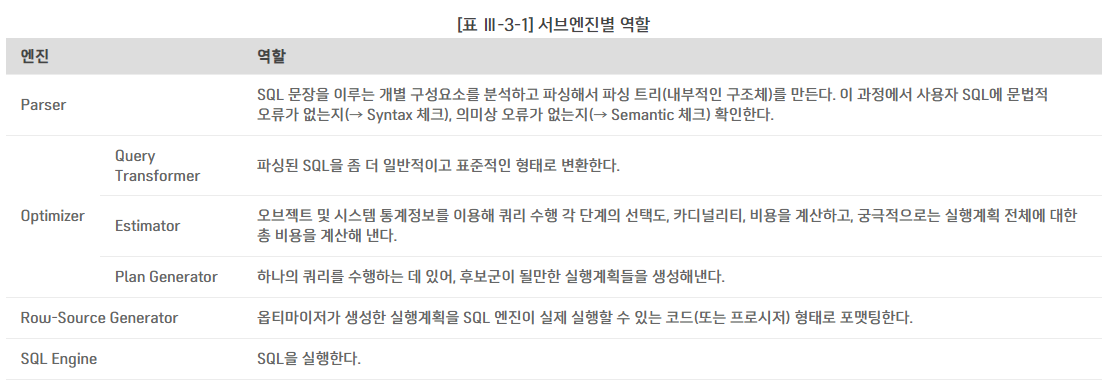
3. SQL 옵티마이저
SQL 옵티마이저(Optimizer) : 사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해주는 DBMS 핵심 엔진
옵티마이저 최적화 단계
- 사용자로부터 전달받은
쿼리를 수행하는 데후보군이 될만한실행계획들을 찾아냄 데이터 딕셔너리(Data Dictionary)에 미리 수집해둔오브젝트 통계및시스템 통계정보를 이용해 각실행계획의예상비용을 산정최저 비용을 나타내는실행계획 선택
4. 실행계획과 비용

옵티마이저가 특정 실행계획을 선택하는 근거를 알아보자
--테스트용 테이블
create table t
as
select d.no, e.*
from scott.emp e, (select rownum no from dual connect by level<=1000) d;
--인덱스 생성
create index t_x01 on t(deptno, no);
create index t_x02 on t(deptno, job, no);통계정보를 수집
exec dbms_stats.gather_table_stats(user,'t');-- 실행계획 확인
select /*+ gather_plan_statistics */ * from t
where deptno=10
and no=1;
select * from table(dbms_xplan.display_cursor(null,null,'ALL'));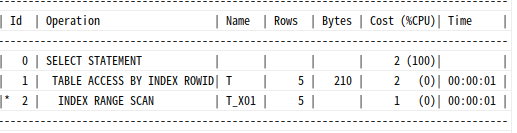
t_x01 인덱스를 선택했을 땐 cost가 2이다.
select /*+ gather_plan_statistics index(t t_x02) */ * from t
where deptno=10
and no=1;
select * from table(dbms_xplan.display_cursor(null,null,'ALL'));
t_x02 인덱스를 사용하니 cost가 7가 됐다.
select /*+ gather_plan_statistics full(t) */ * from t
where deptno=10
and no=1;
select * from table(dbms_xplan.display_cursor(null,null,'ALL'));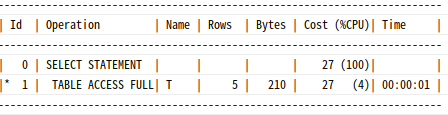
Table Full Scan을 하니 Cost가 27이 됐다.
즉, 옵티마이저가 인덱스를 선택하는 근거는 비용이며, 비용(Cost)은 쿼리를 수행하는 동안 발생할 것으로 예상되는 I/O 횟수 또는 예상 소요시간을 표현한 것
=> 실행경로를 선택하기 위해 옵티마이저가 여러 통계정보를 활용해 계산해 낸 값
5. 옵티마이저 힌트
옵티마이저 힌트 : 통계정보가 정확X 또는 기타 다른 이유로 옵티마이저가 잘못된 판단을 할 수 있어, 직접 인덱스를 지정하거나 조인 방식을 변경함으로써 더 좋은 실행계획으로 유도
Oracle 힌트
힌트 기술 방법
SELECT /*+ LEADING(e2 e1) USE_NL(e1) INDEX(e1 emp_emp_id_pk) USE_MERGE(j) FULL(j) */
e1.first_name, e1.last_name, j.job_id, sum(e2.salary) total_sal
FROM employees e1, employees e2, job_history j
WHERE e1.employee_id = e2.manager_id
AND e1.employee_id = j.employee_id
AND e1.hire_date = j.start_date
GROUP BY e1.first_name, e1.last_name, j.job_id
ORDER BY total_sal;index 힌트에는인덱스명대신칼럼명지정 가능
select /*+ leading(e2 e1) use_nl(e1) index(e1 (employee_id)) ... */힌트가 무시되는 경우
문법적으로 안 맞게 힌트 기술의미적으로 안 맞게 힌트 기술 (ex. 서브쿼리에 unnest와 push_subq 같이 기술)잘못된 참조사용 :없는 테이블, 별칭(Alias)사용,없는 인덱스명지정논리적으로불가능한 액세스 경로 : 조인절에등치 조건이 하나도 없는데해시 조인으로 유도하거나null 허용 컬럼에인덱스를 이용해전체 건수를 세려고 시도하는 등
select /*+ index(e emp_ename_idx) */ count(*) from emp e;버그
=> 옵티마이저는 힌트를 선택 가능한 옵션 정도가 아닌, 사용자로부터 주어진 명령어로 인식
=> Oracle은 힌트 잘못 기술하거나 잘못된 참조시 에러 발생 X
=> SQL Server는 에러 발생
힌트 종류
SQL Server 힌트
테이블 힌트:테이블명다음에WITH절을 통해 지정
ex.fastfirstrow,holdlock,nolock등조인 힌트:FROM절에 지정하며 두 테이블 간 조인 전략에 영향
ex.loop,hash,merge,remote등쿼리 힌트:쿼리당맨 마지막에한번만 지정할 수 있는 쿼리 힌트,OPTION 절이용
🍘데이터베이스 I/O 메커니즘
1. 블록 단위 I/O
모든 DBMS에서 I/O는 블록(페이지) 단위로 이뤄짐
=> 하나의 레코드를 읽더라도 레코드가 속한 블록 전체를 읽음
=> 블록 단위 I/O는 버퍼 캐시와 데이터 파일 I/O에 모두 적용
데이터 파일에서DB 버퍼 캐시로블록을적재할 때데이터 파일에서블록을직접읽고 쓸 때버퍼 캐시에서블록을 읽고 쓸 때버퍼 캐시에서변경된 블록을 다시데이터 파일에 쓸 때
2. 메모리 I/O vs. 디스크 I/O
I/O 효율화 튜닝의 중요성
디스크를 경유한 데이터 입출력 : 디스크의 액세스 암(Arm)이 움직이면서 헤드를 톨해 데이터 읽고 쓰므로 느림
메모리를 통한 입출력 : 전기적 신호에 불과하므로 빠름
모든 DBMS는 읽고자 하는 블록을 먼저 버퍼 캐시에서 찾아보고, 없을 경우에만 디스크에서 읽어 버퍼 캐시에 적재한 후 읽기/쓰기 작업 수행
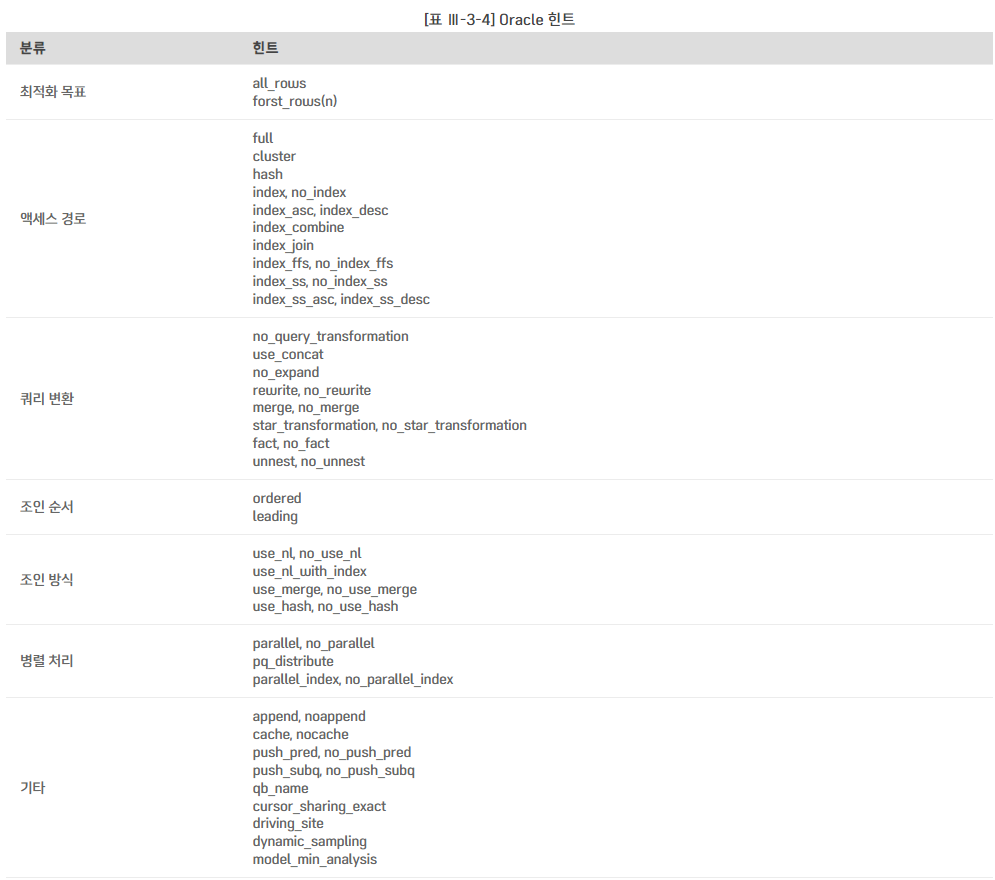
물리적인 디스크 I/O가 필요할 때면, 서버 프로세스는 시스템에 I/O Call을 하고 잠시 대기 상태에 빠지며, 디스크 I/O 경합이 심할수록 대기 시간도 길어짐
메모리는 한정된 자원이므로, 디스크 I/O를 최소화하고 버퍼 캐시 효율을 높이는 것이 I/O 튜닝의 목표
버퍼 캐시 히트율
버퍼 캐시 히트율(BCHR, Buffer Cache Hit Ration) : 버퍼 캐시 효율을 측정하는 지표로, 전체 읽은 블록 중에서 메모리 버퍼 캐시에서 찾은 비율
=> 물리적인 디스크 읽기를 수반하지 않고 곧바로 메모리에서 블록을 찾은 비율
BCHR= (버퍼 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) x 100call count cpu elapsed disk query current rows
------ ---- ----- ------ ---- ----- ------ ----
Parse 15 0.00 0.08 0 0 0 0
Execute 44 0.03 0.03 0 0 0 0
Fetch 44 0.01 0.13 18 822 0 44
------ ---- ----- ------ ---- ----- ------ ----
total 103 0.04 0.25 18 822 0 44disk 항목 : 디스크를 경유한 블록 수
Query+ Current : 버퍼 캐시에서 읽은 블록 수
- 총 읽은 블록 수 : 822
- 버퍼 캐시에서 곧바로 찾은 블록 수 = 822-18=804
- BCHR=(822-18)/822=97.8%
총 읽은 블록 수(Query+Current가 이미 디스크로부터 읽은 블록 수를 포함
같은 블록을 반복적으로 액세스하는 형태의 SQL은 논리적인 I/O요청이 많이 발생함에도 불구하고 BCHR이 높게 나타남
=> BCHR의 한계점
=> ex. NL 조인에서 Inner 테이블을 반복적으로 룩업하는 경우, 작은 테이블을 반복 액세스하면 모든 블록이 메모리에서 찾아져 BCHR은 높지만, 일량이 작지 않고, 블록을 찾는 과정에서 래치 경합과 버퍼 Lock 경합까지 발생하면 메모리 I/O 비용이 디스크 I/O 비용보다 커짐
=> 논리적인 블록 읽기를 최소화
네트워크, 파일시스템 캐시가 I/O 효율에 미치는 영향
네트워크 속도도 SQL 성능에 영향
=> 네트워크 전송량이 많도록 SQL 작성하면, 결코 좋은 성능 X
=> 네트워크 전송량을 줄이려고 노력
RAC에선 인스턴스 간 캐시 된 블록을 공유하므로 메모리 I/O 성능에도 네트워크 속도가 영향
파일 시스템 버퍼 캐시는 최소화해야 함
=> 데이터베이스 자체적으로 캐시 영역을 갖고 있으므로 이를 위한 공간을 크게 할당하는 것이 더 효과적
근본적인 해결책은 논리적인 블록 요청 횟수를 최소화 하는 것
3. Sequential I/O vs. Random I/O
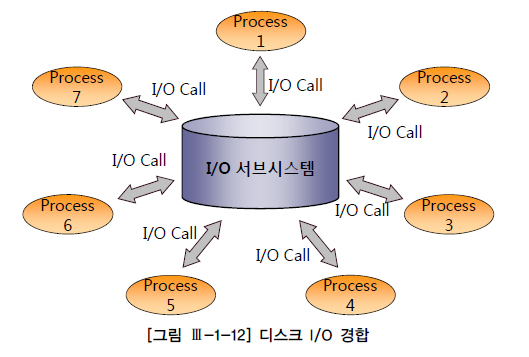
시퀀셜 액세스 : 레코드간 논리적 또는 물리적인 순서를 따라 차례대로 읽어 나가는 방식
=> 인덱스 리프 블록에 위치한 모든 레코드는 포인터를 따라 논리적으로 연결돼 있고, 이 포인터를 따라 스캔하는 것(ex. ⑤번)
=> 테이블 레코드 간에는 포인터로 연결되지는 않으나 테이블을 스캔할 때는 물리적으로 저장된 순서대로 읽어 나가므로 이것 또한 시퀀셜 액세스 방식
랜덤 액세스 : 레코드간 논리적, 물리적인 순서를 따르지 않고, 한 건을 읽기 위해 한 블록씩 접근하는 방식(ex. ④번, ⑥번)
블록 단위 I/O를 하더라도 한번 액세스할 때 시퀀셜 방식으로 그 안에 저장된 모든 레코드를 읽는다면 비효율X
하나의 레코드를 읽으려고 한 블록씩 랜덤 액세스하면 매우 비효율
I/O 튜닝의 핵심 원리
시퀀셜 액세스에 의한선택 비중을 높임랜덤 액세스 발생량을 줄임
시퀀셜 액세스에 의한 선택 비중 높이기
시퀀스 액세스 효율성을 높이려면, 읽은 총 건수 중 결과 집합으로 선택되는 비중을 높여야 함
=> 같은 결과를 얻기 위해 얼마나 적은 레코드를 읽느냐로 판단
-- drop table t
create table t
as
select * from all_objects
order by dbms_random.value;
select count(*) from t;
select /*+ gather_plan_statistics */
count(*)
from t where owner like 'SYS%';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));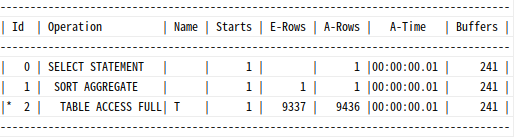
9337 레코드를 읽기 위해 17754 레코드를 읽어 52%가 선택되었다. 읽은 블록 수는 241개다.
select count(*) from t where owner like 'SYS%' and object_name = 'ALL_OBJECTS';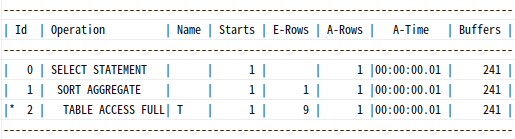
17754의 레코드를 읽고 1개의 레코드를 선택했다.(위 사진은 두번째 실행해서 1로 나옴)
Table Full Scan 비효율이 높다.
읽은 블록 수도 똑같이 241개다.
=> 테이블 스캔하면서 읽은 레코드가 대부분 필터링되고 일부만 선택된다면 인덱스 이용
create index t_idx on t(owner, object_name);
select /*+ index(t t_idx) */ count(*)
from t where owner like 'SYS%'
and object_name = 'ALL_OBJECTS';
1개의 레코드를 구하기 위해 45개의 블록을 읽었다.
인덱스 구성 칼럼 순서를 바꾸고 테스트 해보자
drop index t_idx;
create index t_idx on t(object_name, owner);
select /*+ index(t t_idx) */ count(*)
from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS' ;
단 2개의 인덱스 블록(루트와 리프)만 읽었다.
랜덤 액세스 발생량 줄이기
drop index t_idx;
create index t_idx on t(owner);
select object_id from t where owner = 'SYS' and object_name = 'ALL_OBJECTS';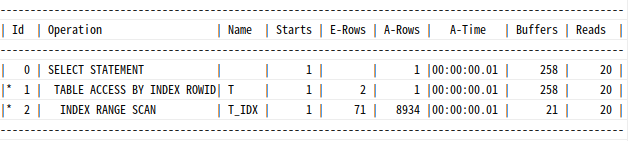
8934건을 읽어 그 횟수만큼 테이블 랜덤 액세스 했다. 최종적으로 한 건이 선택된 것에 비해 너무 많은 랜덤 액세스가 발생
drop index t_idx;
create index t_idx on t(owner, object_name);
select object_id from t
where owner = 'SYS'
and object_name = 'ALL_OBJECTS'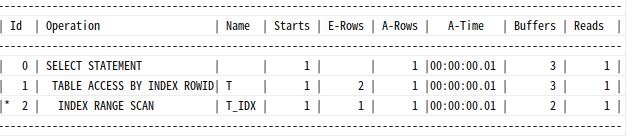
인덱스로부터 1건을 출력했으므로, 테이블도 1번 방문한다.
실제 발생한 테이블 랜덤 액세스는 (3-2) 1번이다.
4. Single Block I/O vs. MultiBlock I/O
Single Block I/O : 한 번의 I/O Call에 하나의 데이터 블록만 읽어 메모리에 적재
=> 인덱스를 통해 테이블 액세스시, 기본적으로 인덱스와 테이블 모두 이 방식 사용
MultiBlock I/O : I/O Call이 필요한 시점에, 인접한 블록들을 같이 읽어 메모리에 적재
=> Table Full Scan 처럼 물리적으로 저장된 순서에 따라 읽을 때는 인접한 블록들을 같이 읽는 것이 유리
=> 익스텐트 범위를 넘어서까지 읽지는 않음
=> 인접한 블록 : 한 익스텐트 내에 속한 블록들
인덱스 스캔 시에는 Single Block I/O 방식이 효율적
=> 인덱스 블록간 논리적 순서(이중 연결 리스트 구조)는 데이터 파일에 저장된 물리적인 순서와 다르기 때문
=> 물리적으로 한 익스텐트에 속한 블록들을 메모리에 올렸는데, 그 블록들이 논리적 순서로는 한참 뒤쪽에 위치해 사용되지 못한 채 버퍼 상에서 밀려나는 일이 발생
대량의 데이터를 MultiBlock I/O 방식으로 읽을 때 Single Block I/O보다 유리한 이유
=> I/O Call 발생 횟수를 줄여주기 때문
--single block I/O
alter system flush buffer_cache; -- 디스크 I/O 발생하도록 버퍼 캐시 Flushing
create table t
as select * from all_objects;
alter table t add constraint t_pk primary key(object_id);
select /*+ index(t) */ count(*) from t where object_id > 0;
37개의 인덱스 블록을 디스크에서 읽으면서 37번의 I/O Call(db file sequential read 대기 이벤트) 발생
--Multiblock I/O
alter system flush buffer_cache; -- 디스크 I/O 발생하도록 버퍼 캐시 Flushing
select /*+ index_ffs(t) */ count(*) from t where object_id > 0;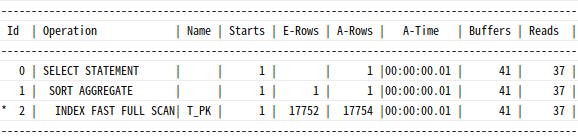
똑같이 37개의 블록을 디스크에서 읽었는데 I/O Call이 9번(db file scattered read 대기 이벤트)에 그침
Single Block I/O 방식으로 읽은 블록들은 LRU 리스트 상 MRU 쪽(end)으로 위치하므로 한 번 적재되면 버퍼 캐시에 비교적 오래 머뭄
MultiBlock I/O 방식으로 읽은 블록들은 LRU 리스트 상 LRU 쪽(end)로 연결되므로 적재된 지 얼마 지나지 않아 1순위로 버퍼캐시에서 밀려남
5. I/O 효율화 원리
논리적인 I/O 요청 횟수를 최소화하는 것이 I/O 효율화 튜닝 핵심
애플리케이션 측면에서의 I/O 효율화 원리
- 필요한
최소 블록만 읽도록 SQL 작성 최적의 옵티마이징 팩터제공- 필요하다면,
옵티마이저 힌트를 사용해최적의 액세스 경로로 유도
필요한 최소 블록만 읽도록 SQL 작성
동일한 데이터를 중복 액세스 하지 않고 필요한 최소 블록만 읽도록 작성
select a.카드번호 , a.거래금액 전일_거래금액 , b.거래금액 주간_거래금액 ,
c.거래금액 전월_거래금액 , d.거래금액 연중_거래금액
from ( -- 전일거래실적
select 카드번호, 거래금액
from 일별카드거래내역
where 거래일자 = to_char(sysdate-1,'yyyymmdd') ) a ,
( -- 전주거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(sysdate-7,'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd')
group by 카드번호 ) b ,
( -- 전월거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(add_months(sysdate,-1),'yyyymm') || '01'
and to_char(last_day(add_months(sysdate,-1)),'yyyymmdd')
group by 카드번호 ) c ,
( -- 연중거래실적
select 카드번호, sum(거래금액) 거래금액
from 일별카드거래내역
where 거래일자 between to_char(add_months(sysdate,-12),'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd')
group by 카드번호 ) d
where b.카드번호 (+) = a.카드번호
and c.카드번호 (+) = a.카드번호
and d.카드번호 (+) = a.카드번호전일 데이터를 총 4번 액세스 한 셈이 되는 SQL문이다.
select 카드번호 ,
sum( case when 거래일자 = to_char(sysdate-1,'yyyymmdd') then 거래금액 end ) 전일_거래금액 ,
sum( case when 거래일자 between to_char(sysdate-7,'yyyymmdd') and to_char(sysdate-1,'yyyymmdd') then 거래금액 end ) 주간_거래금액 ,
sum( case when 거래일자 between to_char(add_months(sysdate,-1),'yyyymm') || '01'
and to_char(last_day(add_months(sysdate,-1)),'yyyymmdd') then 거래금액 end ) 전월_거래금액 ,
sum( 거래금액 )연중_거래금액
from 일별카드거래내역
where 거래일자 between to_char(add_months(sysdate,-12),'yyyymmdd')
and to_char(sysdate-1,'yyyymmdd')
group by 카드번호
having sum( case when 거래일자 = to_char(sysdate-1,'yyyymmdd') then 거래금액 end ) > 0과거 1년치 데이터를 한 번만 읽고 모두 구할 수 있다.
최적의 옵티마이징 팩터 제공
- 전략적인
인덱스 구성: 가장 기본적인 옵티마이징 팩터 DBMS가 제공하는기능활용 :인덱스, 파티션, 클러스터, 윈도우 함수등을 적극 활용해 옵티마이저가 최적으로 선택할 수 있도록 함옵티마이저 모드 설정: 옵티마이저 모드(전체 처리속도 최적화,최초 응답속도 최적화)와 그 외 옵티마이저 행동에 영향을 미치는일부 파라미터를 변경해 주는 것이 도움이 될 수 있음통계정보: 옵티마이저에게정확한 정보를 제공
필요하다면 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도
-- Oracle
select /*+ leading(d) use_nl(e) index(d dept_loc_idx) */ *
from emp e, dept d
where e.deptno = d.deptno
and d.loc = 'CHICAGO';
--SQL Server
select *
from dept d with (index(dept_loc_idx)), emp e
where e.deptno = d.deptno
and d.loc = 'CHICAGO'
option (force order, loop join)