📔설명
복제 아키텍처, 타입, 포맷, 등등에 대해 알아보자
🍀개요
복제 : 한 서버에서 다른 서버로 데이터 동기화되는 것
=> 소스(Source) 서버 : 원본 데이터 가진 서버
=> 레플리카(Replica) 서버 : 복제된 데이터 가진 서버
레플리카 서버 구축 목적
스케일 아웃(Scale-out): 동일한 데이터를 가진DB 서버를 한 대 이상 더 사용해쿼리 분산
=>스케일 업(Scale-up): 서버의사양업그레이드데이터 백업:레플리카 서버에서 주로데이터 백업을 실행하며, 소스 서버 문제 발생시대체 서버 역할데이터 분석:레플리카 서버에서분석용 쿼리전용으로만 실행되도록 구성데이터의 지리적 분산: DB 서버 위치를 이동하지 못한다면,복제를 이용해애플리케이션 서버가 위치한 곳에 기존 DB 서버 대신레플리카 서버를 구축해 사용함으로써응답 속도개선
🍁복제 아키텍처
바이너리 로그(Binary Log) : MySQL 서버에서 발생하는 모든 변경 사항이 기록되는 곳
=> 데이터 변경 내역, 계정이나 권한 변경, 테이블 구조 변경 등 모두 저장
=> 이벤트(Event) : 바이너리 로그에 기록된 각 변경 정보
=> 복제는 바이너리 로그 기반 구현 (소스 서버의 바이너리 로그가 레플리카 서버로 전송되고, 레플리카 서버에서는 해당 내용을 로컬 디스크에 저장 후 데이터 반영하여 동기화)
=> 릴레이 로그(Relay Log) : 레플리카 서버에서 소스 서버의 바이너리 로그를 읽어 들여 로컬 디스크에 저장해둔 파일
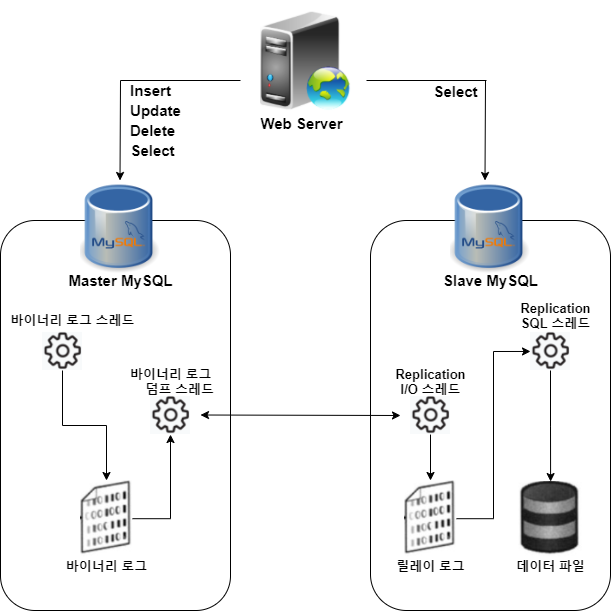
바이너리 로그 덤프 스레드(Binary Log Dump Thread) : 소스 서버에서 레플리카 서버 연결 시 내부적으로 해당 스레드 생성 후 바이너리 로그 내용을 레플리카 서버로 전송
레플리케이션 I/O 스레드(Replication I/O Thread) : 소스 서버의 바이너리 로그 덤프 스레드로부터 바이너리 로그 이벤트를 가져와 로컬 서버 파일(릴레이 로그)로 저장
레플리케이션 SQL 스레드(Replication SQL Thread) : 릴레이 로그 파일의 이벤트들을 읽고 실행
복제 시작시 관련 데이터
릴레이 로그:바이너리 로그에서 읽어온이벤트(트랜잭션)정보 저장커넥션 메타데이터:레플리케이션 I/O 스레드에서소스 서버에 연결할 때 사용하는DB 계정 정보및 현재 읽고 있는 소스 서버바이너리 파일명과파일 내 위치 값등이 담겨 있음어플라이어 메타데이터: (어플라이어(Applier): 레플리케이션 SQL 스레드에서릴레이 로그에 저장된소스 서버의 이벤트들을 레플리카 서버에적용하는 컴포넌트) 최근 적용된 이벤트에 대해 해당 이벤트가 저장돼 있는릴레이 로그 파일명과파일 내 위치 정보등을 가짐
크래시 세이프 복제(Crash-safe replication) : TABLE 형태로 메타데이터를 관리하면, 예기치 않게 MySQL이 갑자기 종료되어도 다시 구동시 문제없이 복제 진행
🍂복제 타입
소스 서버의 바이너리 로그에 기록된 변경 내역들을 식별하는 방식에 따라 바이너리 로그 파일 위치 기반 복제와 글로벌 트랜잭션 ID 기반 복제로 나뉨
1. 바이너리 로그 파일 위치 기반 복제
- 레플리카 서버에서 소스 서버의
바이너리 로그 파일명과 파일 내에서의위치(Offset)로개별 바이너리 로그 이벤트를 식별해서복제진행 - 복제 처음 구축시 레플리카 서버에서 소스 서버의
어떤 이벤트부터 동기화를 수행할 것인지에 대한 정보 설정 필요 복제가 설정된 레플리카 서버는 소스 서버의어느 이벤트까지로컬 디스크로 가져왔고또적용했는지 정보 관리
=> 소스 서버에 위의 정보를전달해그 이후의 바이너리 로그 이벤트들을 가져옴이벤트를소스 서버의 바이너리 로그 파일명과파일 내에서위치 값의조합으로 식별- 복제에 참여한
MySQL 서버들이 모두고유한 server_id 값을 가지고 있어야 함
=>바이너리 로그에는 각 이벤트별로 이벤트 최초 발생 MySQL 서버 식별을 위해server_id 값을 함께 저장 바이너리 로그 파일에 기록된 이벤트가레플리카 서버에 설정된server_id 값과동일하다면,해당 이벤트 적용X
=> 자신의 서버에서 발생한 이벤트로 간주
바이너리 로그 파일 위치 기반의 복제 구축
설정 준비
-소스 서버에 반드시 바이너리 로그가 활성화
-복제 구성원이 되는 MySQL 서버가 고유한 server_id 값 가짐
## 소스 서버 설정
[mysqld]
server_id=1
log_bin=/binary-log-dir-path/binary-log-name
...#바이너리 로그 기록 확인
show master status;
Position은 위치 값으로, 실제 파일의 바이트 수를 의미
## 레플리카 서버 설정
[mysqld]
server_id=2
relay_log=/relay-log-dir-path/relay-log-name
replay_log_purge=ON #레플리카 서버에 적용된 릴레이 로그 파일 자동 삭제
log_slave_updates #데이터 변경 내용 기록
read_only #읽기 전용
...복제 계정 준비
레플리카 서버에서 소스 서버로 접속할 DB 계정 필요
=> 복제용 계정
=> 소스 서버에 미리 복제용 계정을 준비해야 함
=> 반드시 replication slave 권한 가져야 함
#소스 서버에서
create user 'rep'@'%' identified by '비밀번호';
grant replication slave on *.* to 'rep'@'%';데이터 복사
소스 서버의 데이터를 레플리카 서버로 적재하기 위해 mysqldump로 데이터 복사
=> --single-transaction : 데이터 덤프시 하나의 트랜잭션을 사용해 잠금을 걸지않고 일관된 데이터 덤프 받음
=> --master-data : 덤프 시작 시점의 소스 서버의 바이너리 로그 파일명과 위치 정보를 포함하는 복제 설정 구문이 덤프 파일 헤더에 기록될 수 있게 하는 옵션
#소스서버 linux
mysqldump -uroot -p --single-transaction --master-data=2 \
--opt --routines --triggers --hex-blob --all-databases > source_data.sqlsource_data.sql을 레플리카 서버로 옮겨 데이터 적재 진행
#레플리카 서버
source D:\source_data.sql#서버에 로그인 안하고 데이터 적재
mysql -uroot -p< D:\source_data.sql
cat /tmp/source_data.sql | mysql -uroot -p복제 시작
mysqldump로 소스 서버 데이터를 백업한 시간이 9시 59분이고, 레플리카 서버에 적재된 시간이 10시 11분이다.
복제 설정 명령어 : change replication source to(또는 change master to)
#less 명령 사용(윈도우 more)
more D:\source_data.sql
change로 시작하는 부분만 복사
#8.0.23이상
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='root',
SOURCE_PORT=3306,
SOURCE_USER='rep',
SOURCE_PASSWORD='비밀번호',
SOURCE_LOG_FILE='binlog.000037',
SOURCE_LOG_POS=693,
GET_SOURCE_PUBLIC_KEY=1;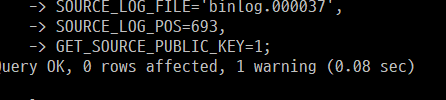
show replica status \G
start replica 실행하면, 위 두 칼럼의 yes로 변경됨
start replica
Seconds_Behind_Source 값이 0이 되면, 소스 서버와 레플리카 서버 데이터 완전히 동기화 됨
바이너리 로그 파일 위치 기반의 복제에서 트랜잭션 건너뛰기
문제되는 소스 서버의 트랜잭션을 무시하고 넘어가도록 처리
=> sql_slave_skip_counter 시스템 변수 이용
#INSERT 실패한 상태로 복제 멈췄다고 가정
stop replica sql_thread;
#스레드 재시작하면서 INSERT 건너뜀
#1로 설정시 해당 이벤트 포함 그룹을 무시
set global sql_slave_skip_counter=1;
start replica sql_thread;2. 글로벌 트랜잭션 아이디(GTID) 기반 복제
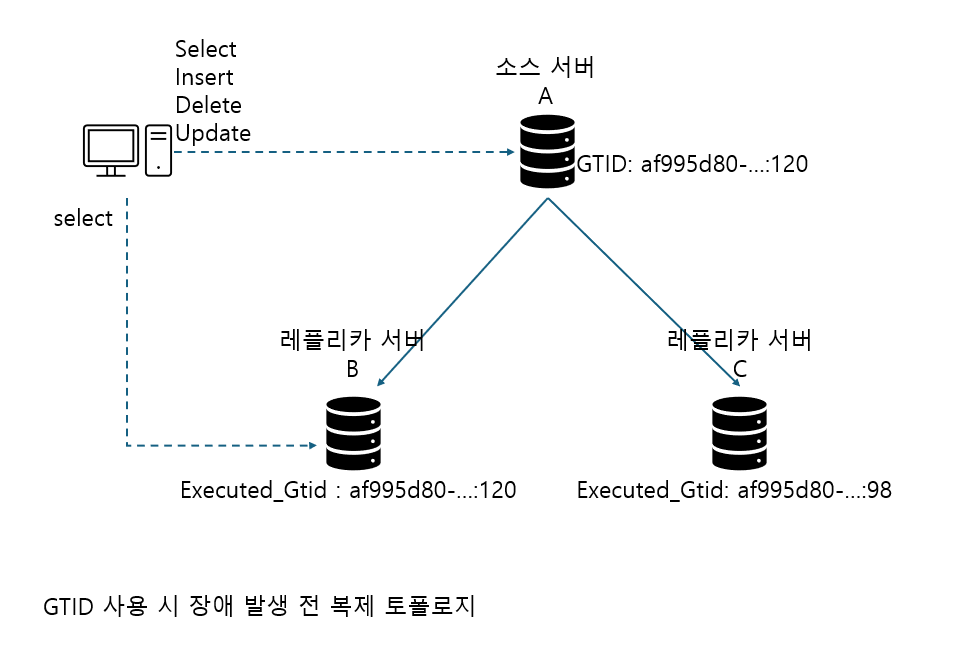
글로벌 트랜잭션 아이디(GTID) : 소스 서버에서만 유효한 고유 식별 값이 아닌, 복제에 참여한 전체 MySQL 서버들에서 고유하도록 각 이벤트에 부여된 식별 값
GTID의 필요성
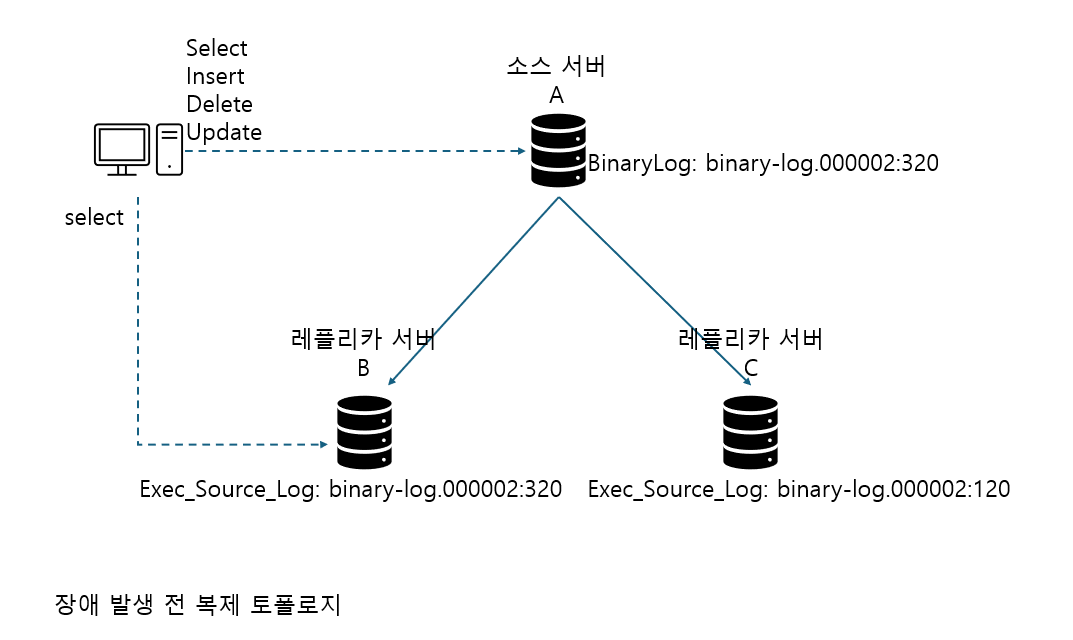
B는 쿼리 분산용, C는 배치나 통계용
위 경우 소스 서버 A가 장애가 발생하면서, 종료될 경우 레플리카 서버를 소스 서버로 승격하고, A 서버로 연결돼 있던 클라이언트 커넥션을 새로 승격된 소스 서버로 교체해야 함
=> 완전히 동기화돼 있던 서버 B를 소스 서버로 승격
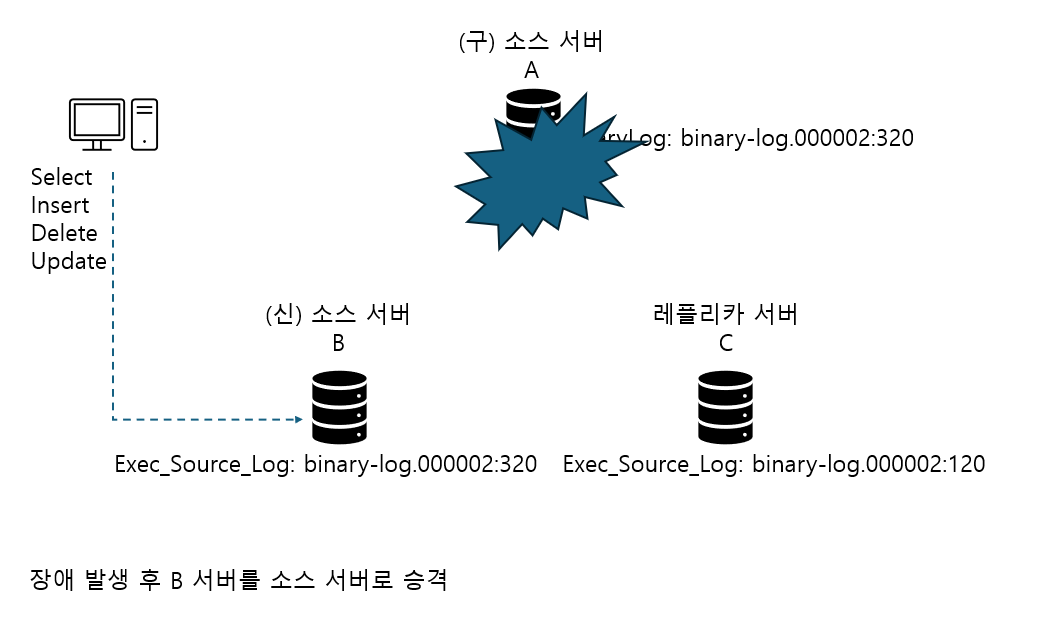
C 서버는 동기화가 되지 않은 상태에서 A 서버가 종료돼 버렸으므로 최종 시점까지 동기화할 방법 없음
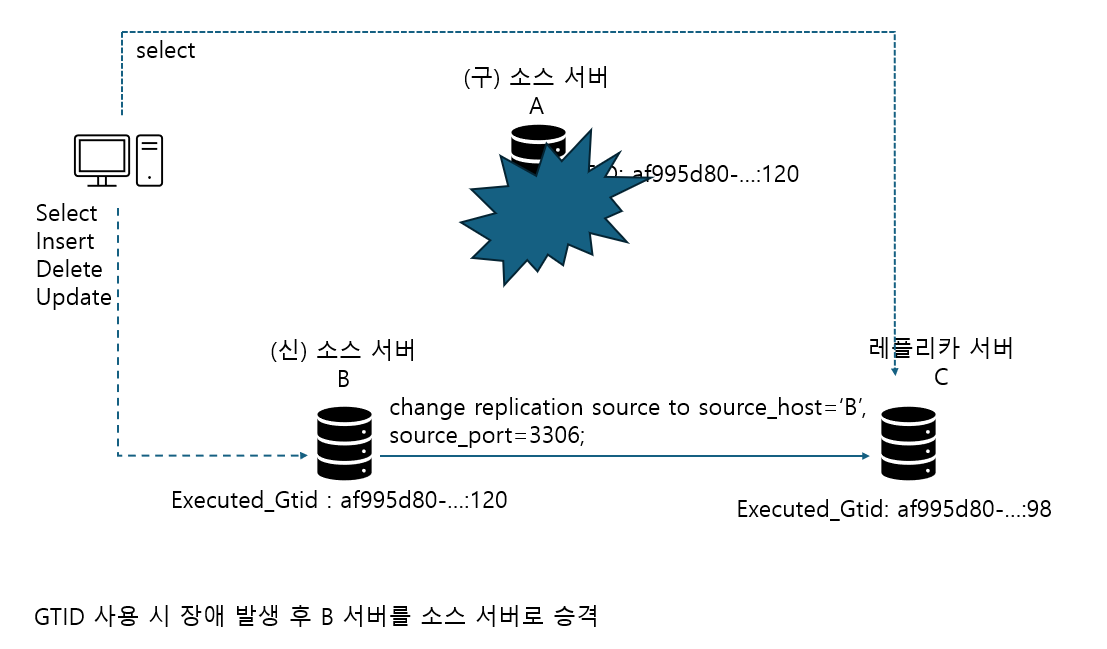
소스 서버 A에 장애 발생하면, B 서버를 C 서버의 소스 서버가 되도록 C 서버에서 change replication source to source_host='B', source_port=3306; 명령을 실행
=> B 서버의 바이너리 로그 파일명과 어느 위치부터 이벤트 가져와야 하는지 입력할 필요X
=> A 서버의 GTID가 af995d80-...인 트랜잭션은 B 서버에서도 똑같기 때문
=> C 서버는 B 서버에서 98 이후 바이너리 로그 이벤트를 가져와서 동기화하면 됨
글로벌 트랜잭션 아이디
GTID는 서버에서 커밋된 각 트랜잭션과 연결된 고유 식별자로, 해당 트랜잭션이 발생한 서버에서 고유하며, 복제 토폴로지 내 모든 서버에서 고유
=> 소스 아이디와 트랜잭션 아이디 값의 조합으로 생성
=> :으로 구분
GTID=[source_id]:[transaction_id]source_id : 트랜잭션이 발생된 소스 서버를 식별하는 값
=> server_uuid 값 사용
=> MySQL 서버가 시작되면서 자동으로 부여
transaction_id : 서버에서 커밋된 트랜잭션 순서대로 부여되는 값
#gtid 값 확인
select * from mysql.gtid_executed;GTID 셋 : 하나 이상의 GTID 값으로 구성돼 있는 것
여러 서버에서 데이터를 복제해오는 등 서로 다른 UUID를 가질 수 있는데, 이때 서로 다른 UUID는 ,로 구분
mysql.gtid_executed 테이블은 레플리카 서버에서 바이너리 로그가 비활성화돼 있는 상태에서 GTID 기반 복제를 사용할 수 있게 하며, 예기치 못한 문제로 바이너리 로그 손실시 GTID 값 보존되도록 함
=> 실행된 모든 트랜잭션에 대해 GTID 값 저장
글로벌 트랜잭션 아이디 기반의 복제 구축
설정 준비
-GTID 활성화
-server_id 및 server_uuid 고유
## 소스 서버
[mysqld]
gtid_mode=ON
enforce_gtid_consistency=ON
server_id=1111
## 레플리카 서버
gtid_mode=ON
enforce_gtid_consistency=ON
server_id=2222데이터 복사
위 명령 후 systemctl restart mysqld로 서버 재시작
## 소스서버 linux
mysqldump -uroot -p --single-transaction --master-data=2 --set-gtid-purged=ON \
--opt --routines --triggers --hex-blob --all-databases > source_data.sqlmysqldump로 데이터를 덤프받아 레플리카 서버 구축시, 시스템 변수 설정 필요
gtid_executed: MySQL 서버에서 실행되어바이너리 로그 파일에 기록된모든 트랜잭션들의GTID 셋gtid_purged: MySQL 서버의 바이너리 로그 파일에존재하지 않는 모든 트랜잭션들의GTID 셋
GTID 기반 복제에서 레플리카 서버는 gtid_executed 값을 기반으로 다음 복제 이벤트를 소스 서버로부터 가져옴
=> 복제 시작을 위해선 소스 서버에서 데이터 덤프가 시작된 시점의 소스 서버의 GTID 값을 레플리카 서버의 gtid_purged 시스템 변수에 지정해 gtid_executed 시스템 변수에도 그 값이 설정되게 해야함
more D:\source_data.sql
#복제
show global variables like 'gtid_executed';
#복제
source D:\source_data.sql#복제
show global variables like 'gtid_executed';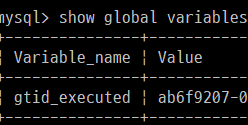
복제 시작
reset replica;
#백업 시점부터 지금까지 변경된 데이터와 이후 변경될 데이터 실시간 적용
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='root',
SOURCE_PORT=3306,
SOURCE_USER='rep',
SOURCE_PASSWORD='비밀번호',
SOURCE_AUTO_POSITION=1,
GET_SOURCE_PUBLIC_KEY=1;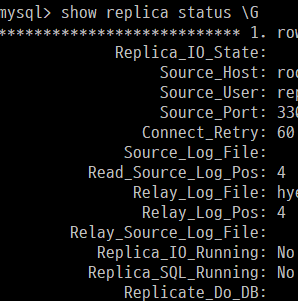
글로벌 트랜잭션 아이디 기반 복제에서 트랜잭션 건너뛰기
레플리카 서버에서 소스 서버로부터 넘어온 트랜잭션을 무시하고 싶다면, 수동으로 빈 트랜잭션을 생성해 GTID 값을 만들어야 함
Non-GTID 기반 복제에서 GTID 기반 복제로 온라인 변경
https://dev.mysql.com/doc/refman/8.4/en/replication-mode-change-online-enable-gtids.html
GTID 기반 복제 제약 사항
GTID 일관성을 해칠 수 있는 일부 유형 쿼리 실행 불가능sql_slave_skip_counter사용해서건너뛰기 불가능
🍃복제 데이터 포맷
바이너리 로그에 어떤 형태로 저장되는지를 나타내는 바이너리 로그 로깅 포맷 타입을 알아보자
Statement 방식 : SQL 문을 바이너리 로그에 기록
Row 방식 : 변경된 데이터 자체를 기록
1. Statement 기반 바이너리 로그 포맷
SQL문을 바이너리 로그에 기록하는 방식
=> 감사에 용이
=> 용량이 작아짐
mysqlbinlog mysql-bin.000001 > mysql-bin.000001.sql #사람이 읽을 수 있는 형태로 변환
less mysql-bin.000001.sql비확정적(Non-Deterministic)으로 처리되는 쿼리 실행된 경우 소스 서버와 레플리카 서버 간에 데이터가 달라질 수 있음
데이터에 락을 더 많이 검
REPEATABLE-READ 이상의 트랜잭션 격리 수준이어야 함
2. Row 기반 바이너리 로그 포맷
변경된 값 자체가 바이너리 로그에 기록
=> 복제시 소스 서버와 레플리카 서버의 데이터를 일관되게 하는 가장 안전한 방식
=> SQL문 확인하려면, 릴레이 로그를 봐야 함(-v 옵션 반드시 설정)
=> 사용자 계정 생성, 권한 부여 및 회수, 테이블, 뷰, 트리거 생성 등 DDL은 모두 Statement 포맷 으로 기록
3. Mixed 포맷
두 가지 바이너리 포맷을 혼합해서 사용
=> 기본적으로 Statement 포맷 사용
=> 필요시 자동으로 Row 포맷으로 전환해서 로그에 기록
4. Row 포맷의 용량 최적화
바이너리 로그 Row 이미지
저장되는 변경 데이터의 칼럼 구성을 제어하는 binlog_row_image라는 시스템 변수 제공
Row 포맷 사용시 각 변경 데이터마다 변경 전 레코드(Before-Image)와 변경 후 레코드(After-Image)가 함께 저장
=> binlog_row_image : 각 변경 전후 레코드들에 대해 테이블의 어떤 칼럼들을 기록할지 결정
full: 발생한 레코드의모든 칼럼들의 값을 바이너리 로그에 기록minimal:변경 데이터에 대해 꼭필요한 칼럼들의 값만 바이너리 로그에 기록noblob:blob이나text에 변경 발생X시 해당 칼럼은 기록X
PKE : 프라이머리 키
바이너리 로그 트랜잭션 압축
시점 복구(Point-In-Time Recovery)를 고려하는 경우 원격 스토리지 서버에 바이너리 로그 백업
트랜잭션에서 변경한 데이터를 압축해서 바이너리 로그에 기록할 수 있게 기능 도입
=> zstd 알고리즘을 사용해 압축
🎈복제 동기화 방식
1. 비동기 복제(Asynchronous replication)
비동기 방식 : 소스 서버가 레플리카 서버에서 변경 이벤트가 정상적으로 전달되어 적용됐는지 확인X
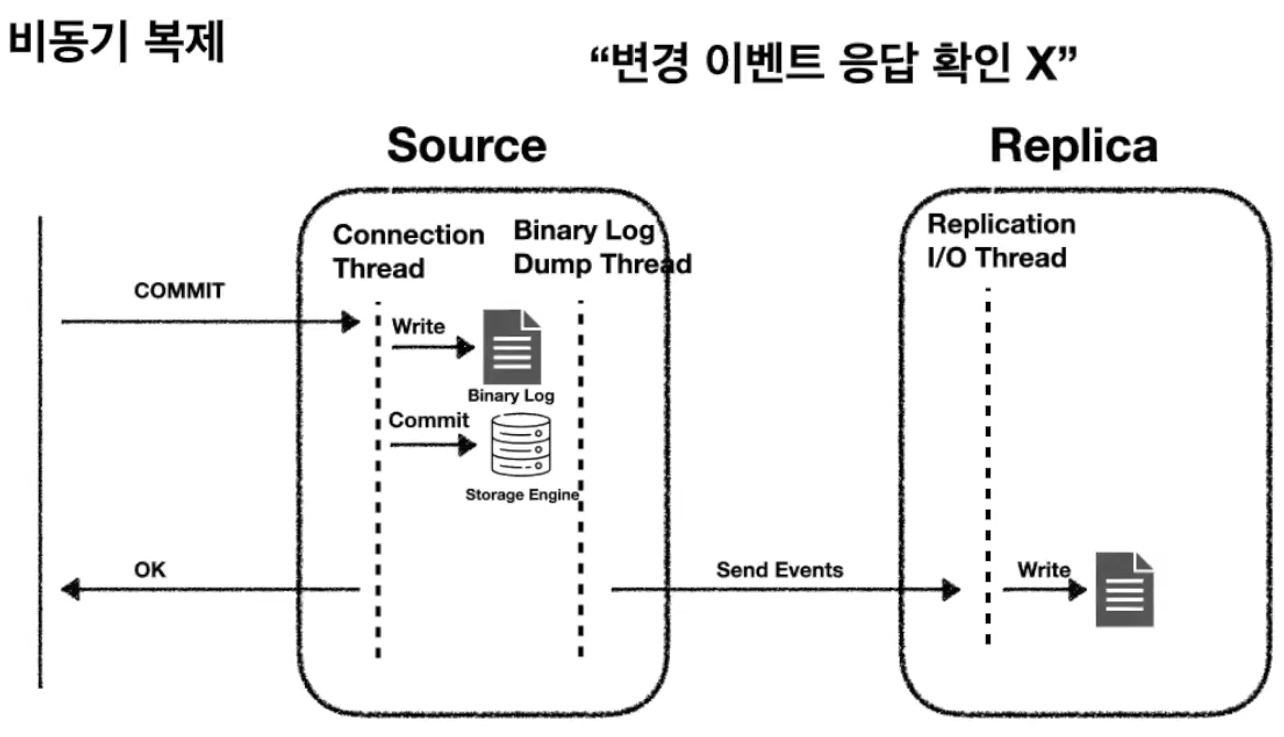
소스 서버 장애로 인해 레플리카 서버를 새로운 소스 서버로 승격시킬 경우, 레플리카 서버가 소스 서버로부터 전달받지 못한 트랜잭션이 있는지 직접 확인하고 수동으로 다시 적용해야 함
레플리카 서버에 문제 생겨도 소스 서버는 아무런 영향X
=> 트래픽 분산 및 분석 용도로 적합
2. 반동기 복제(Semi-synchronous replication)
반동기 방식 : 소스 서버는 레플리카 서버가 소스 서버로부터 전달받은 변경 이벤트를 릴레이 로그에 기록 후 응답(ACK)를 보내면 그때 트랜잭션 완전히 커밋 후 클라이언트에 결과 반환
=> 소스 서버에서 정상적으로 결과가 반환된 모든 트랜잭션들에 대해 적어도 하나의 레플리카 서버에는 해당 트랜잭션이 전송됐음을 보장
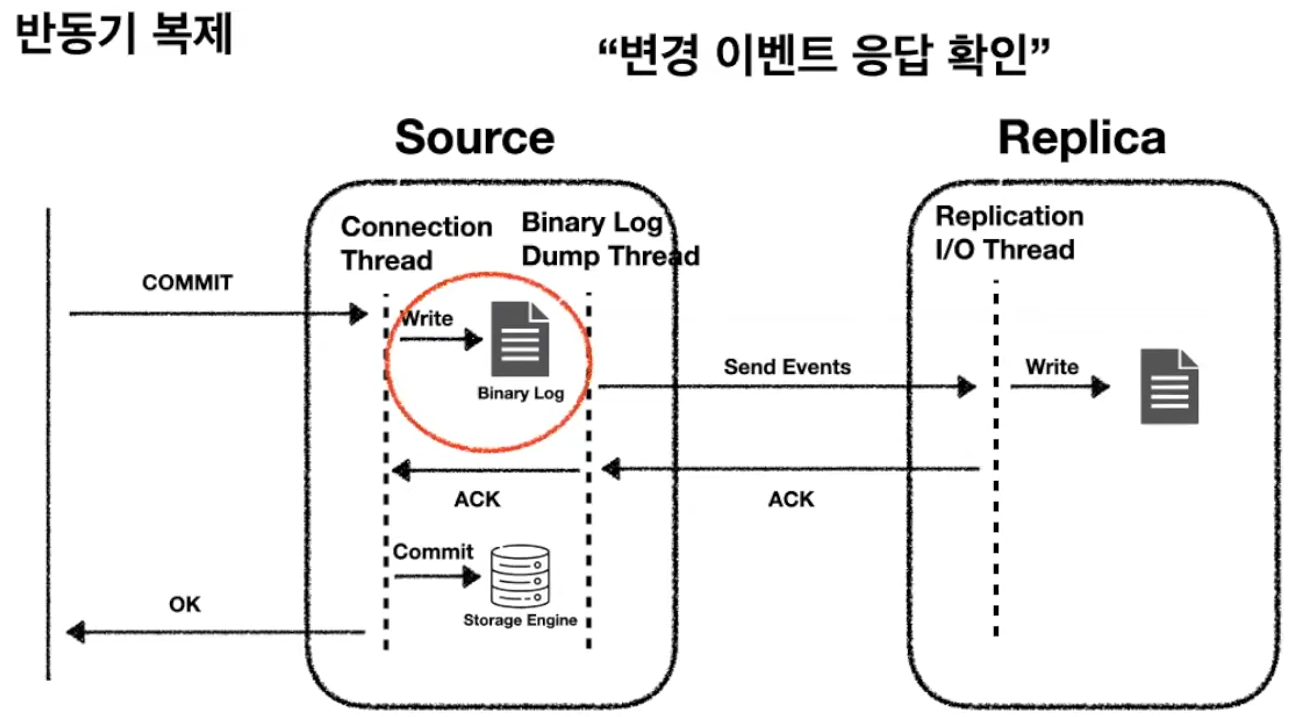
after_sync 반동기 복제 방식은 소스 서버에서 각 트랜잭션을 바이너리 로그에 기록한 후, 커밋 전에 레플리카 서버의 응답을 기다림
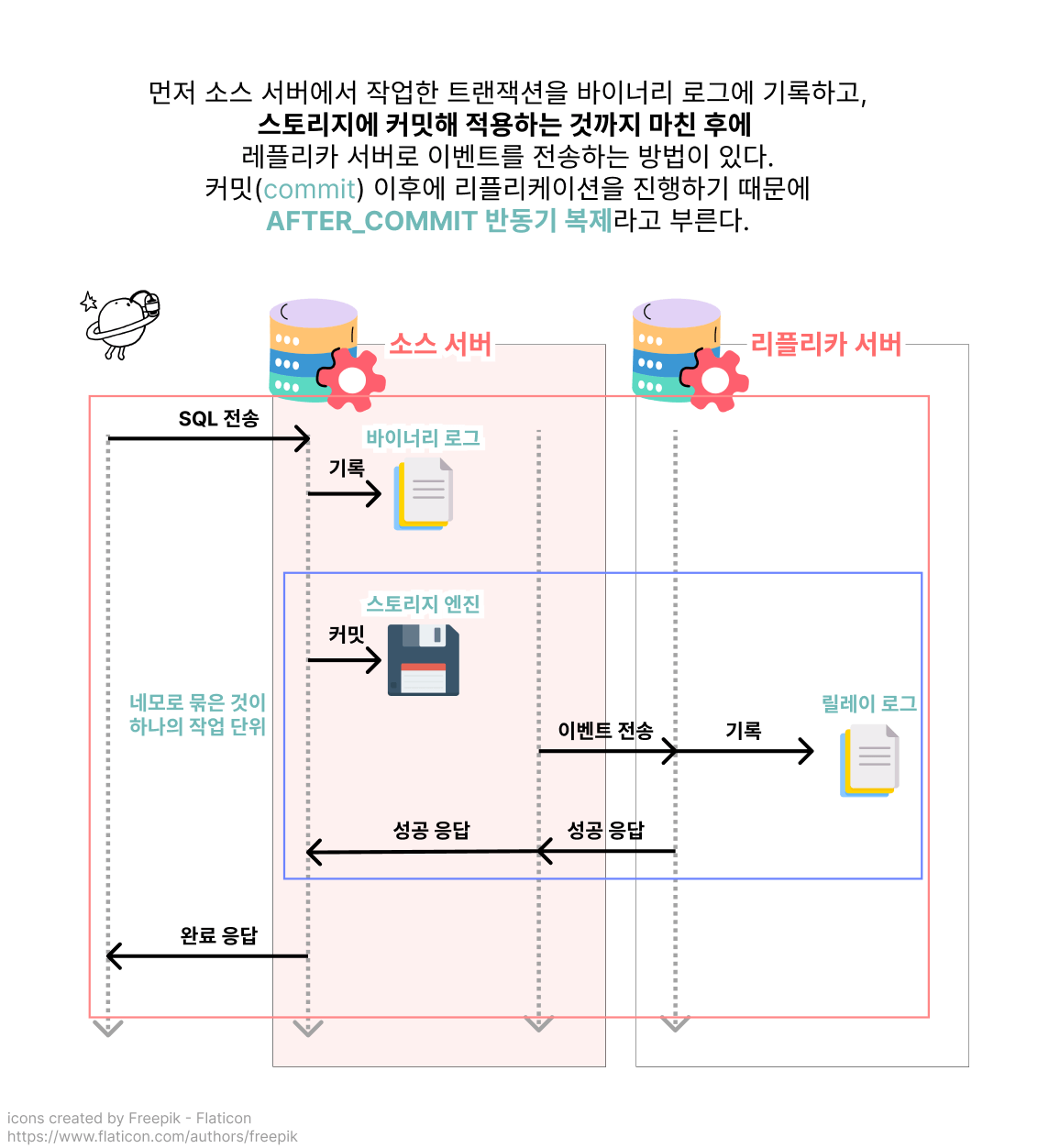
after_commit은 소스 서버에서 트랜잭션을 바이너리 로그에 기록한 후, 커밋을 진행한 후 최종적으로 클라이언트 반환 전에 레플리카 서버의 응답 기다림
after_sync는 after_commit에 비해 소스 서버 장애 발생시 팬텀 리드가 발생하지 않고,
소스 서버에 대해 좀 더 수월하게 복구 처리가 가능
반동기 복제 설정 방법
플러그인 설치 필요
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
INSTALL PLUGIN rpl_semi_sync_replica SONAME 'semisync_replica.dll'; #윈도우#플러그인 설치 확인
show plugins;

set global rpl_semi_sync_master_enabled=1;
set global rpl_semi_sync_master_timeout=5000;
set global rpl_semi_sync_replica_enabled=1;#I/O 스레드 재시작
#레플리카
stop replica IO_THREAD;
start replica IO_THREAD;🎆복제 토폴로지
1. 싱글 레플리카 복제 구성
싱글 레플리카 복제 : 하나의 소스 서버에 하나의 레플리카 서버만 연결
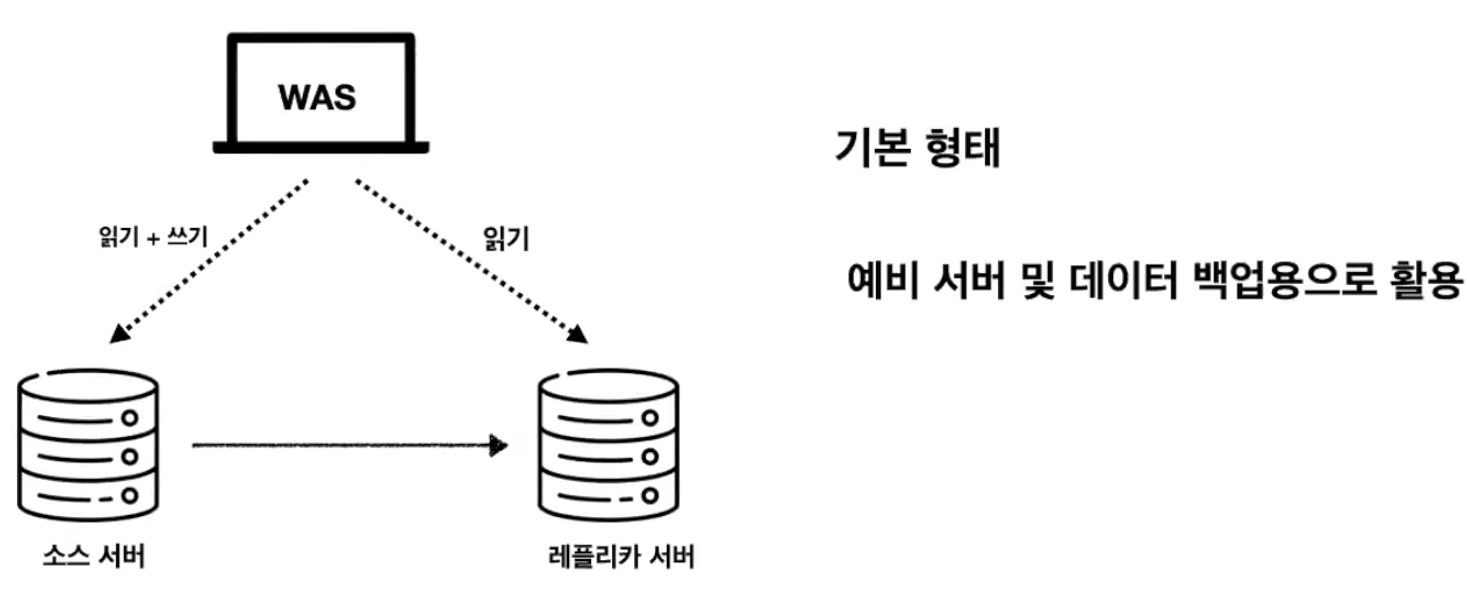
애플리케이션 서버는 보통소스 서버에만 직접적으로 접근레플리카 서버는소스 서버에장애발생시 사용
2. 멀티 레플리카 복제 구성
멀티 레플리카 복제 : 하나의 소스 서버에 2개 이상의 레플리카 서버를 연결
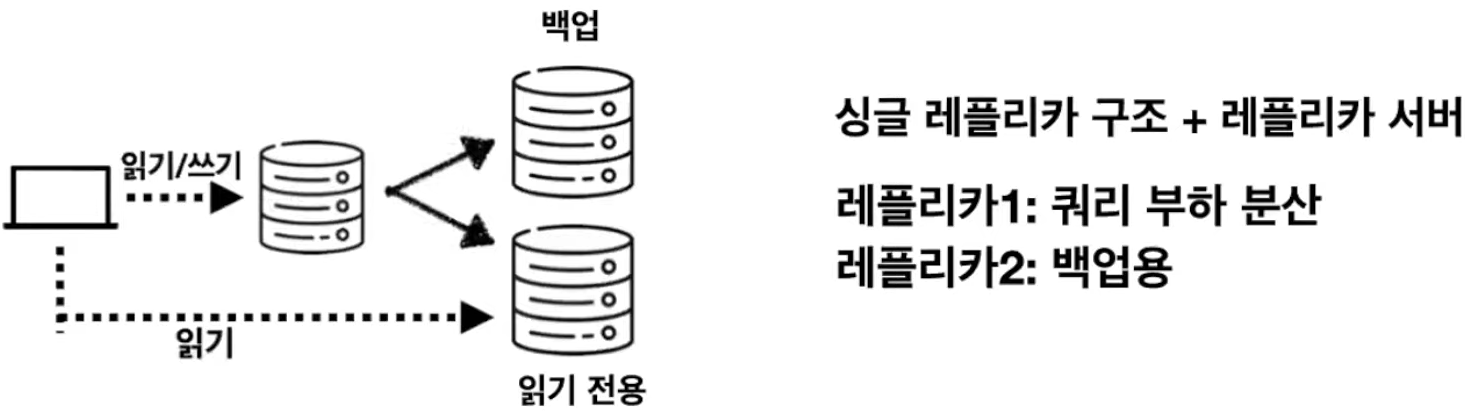
읽기 요청 처리분산 또는배치나통계,분석- 예비용
3. 체인 복제 구성
체인 복제 구성 : 1:M:M 구조
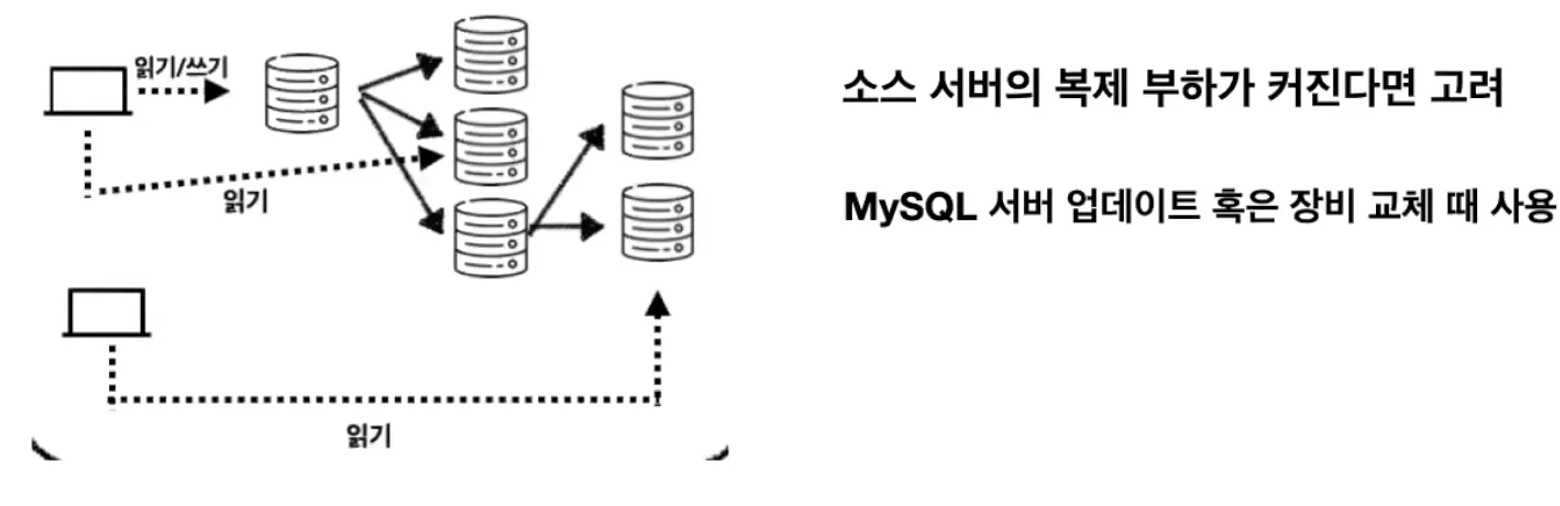
바이너리 로그를 읽어서 전달해야 할 레플리카 서버 수가 많다면, 부하가 될 수 있어 레플리카 서버가 소스 서버가 해야 할 바이너리 로그 배포 역할을 담당
- MySQL 서버
업그레이드또는 장비일괄 교체시 사용
4. 듀얼 소스 복제 구성
듀얼 소스 복제 구성 : 두 개의 MySQL 서버가 서로 소스 서버이자 레플리카 서버로 구성
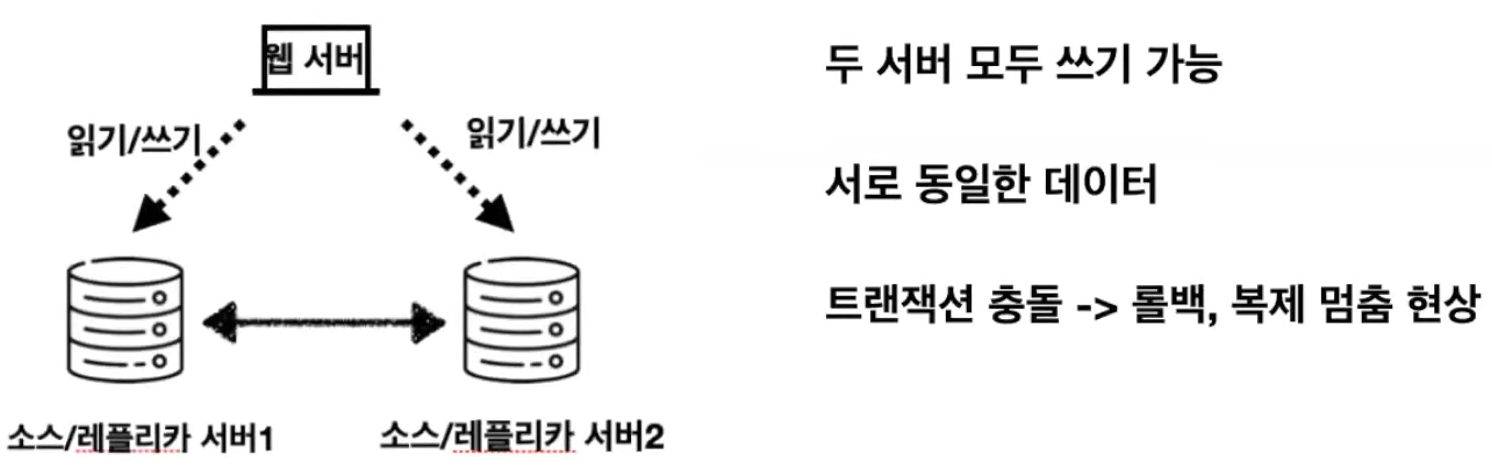
- 서버 모두
쓰기가능 - 각 서버의
변경데이터는복제를 통해각 서버에적용 ACTIVE-PASSIVE: 하나의 서버에만 쓰기작업ACTIVE-ACTIVE: 두 서버 모두에 쓰기작업
문제 발생 가능 부분
동일한 데이터를각 서버에서 변경테이블에서Auto-Increment 키 사용
5. 멀티 소스 복제 구성
멀티 소스 복제 구성 : 하나의 레플리카 서버가 둘 이상의 소스 서버를 갖는 형태

- 여러 MySQL 서버에 존재하는
각기 다른 데이터를통합 샤딩돼 있는 테이블 데이터를하나의 테이블로통합- 데이터들을 모아
하나의 서버에서백업수행
멀티 소스 복제 동작
레플리카 서버는 소스 서버들의 변경 이벤트들을 동시점에 병렬로 동기화
=> 복제가 독립적으로 처리되는 것 의미
=> 채널(Channel) : 독립된 복제 처리
각 복제 채널은 개별적인 레플리케이션 I/O 스레드, 릴레이 로그, 레플리케이션 SQL 스레드를 가지며, 어느 소스 서버와의 복제 연결인지 구별할 수 있는 식별자 역할
FOR CHANNEL 구문을 사용해 복제 채널명 지정
멀티 소스 복제 구축
mysqldump이용 :병합관련 문제XXtraBackup이용 :시스템 테이블 스페이스를 포함해서 그대로 복사해서 복구
🎇복제 고급 설정
1. 지연된 복제(Delayed Replication)
소스 서버에서 실수로 중요한 테이블이나 데이터 삭제시 지연된 복제를 사용해 바로 데이터 복구 가능
source_delay 옵션을 통해 얼마나 지연시킬 것인지 지정
change replication source to source_dealy=86400;지연된 복제를 사용하더라도 소스 서버의 바이너리 로그는 즉시 레플리카 서버의 릴레이 로그 파일로 복사
2. 멀티 스레드 복제(Multi-threaded Replication)
멀티 스레드 복제 : 레플리카 서버에서 소스 서버로부터 복제된 트랜잭션들을 하나의 스레드가 아닌 여러 스레드로 처리할 수 있게 하는 기능
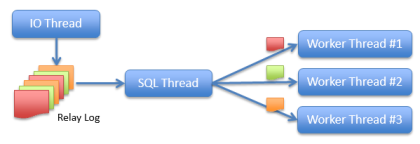
SQL 스레드는 코디네이터 스레드로 불리며, 실제로 이벤트 실행하는 스레드인 워커 스레드(Worker Thread)와 협업해서 동기화 진행
코디네이터 스레드는 릴레이 로그 파일에서 이벤트 읽은 후, 스케줄링해서 워커 스레드에 각 이벤트 할당
이벤트들은 워커 스레드들의 큐에 적재되며, 워커 스레드는 큐에서 이벤트를 꺼내 순차적으로 레플리카 서버에 적용
어떻게 병렬로 처리할 것인가에 따라 데이터베이스 기반과 LOGICAL CLOCK 기반으로 나뉨
데이터베이스 기반 멀티 스레드 복제
데이터베이스 단위로 병렬 처리 수행
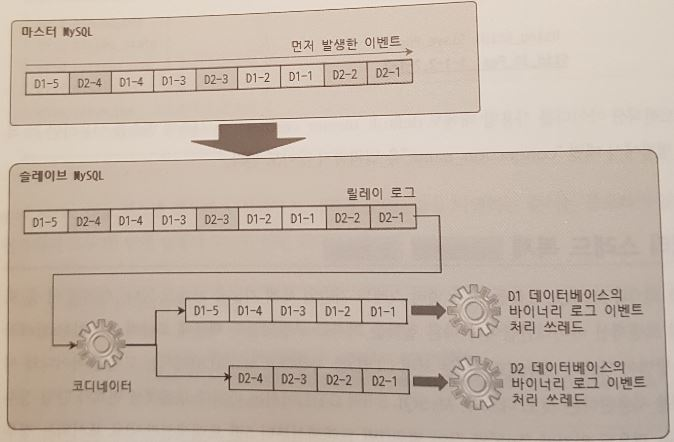
코디네이터 스레드는 로그 파일에서 이벤트를 읽어 데이터베이스 단위로 분리하고, 각 워커 스레드에게 이벤트 할당
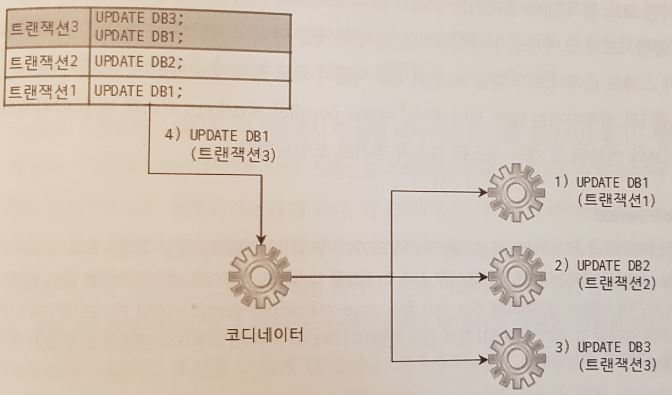
DB3은 3번째 워커 스레드가 변경 후 DB1을 변경하는 것은 첫 번째 스레드가 이전 DB1 업데이트 끝날 때 까지 기다림
LOGICAL CLOCK 기반 멀티 스레드 복제
데이터베이스에 종속X이며 멀티 스레드로 처리하는, 즉 같은 데이터베이스 내에서도 멀티 스레드 동기화 처리가 가능한 방식
=> 소스 서버에서 트랜잭션들이 바이너리 로그로 기록될 때 각 트랜잭션 별로 논리적인 순번 값을 부여해 레플리카 서버에서 순번 값을 바탕으로 병렬로 실행
Commit-parent기반 방식 :이전에 커밋된트랜잭션의 순번 값을 바탕으로 처리 여부 판단WriteSet
바이너리 로그 그룹 커밋
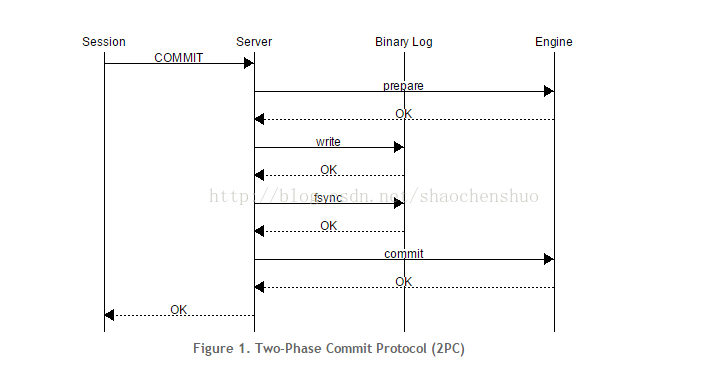
분산 트랜잭션(XA, Two-Phase Commit) : 클라이언트로부터 커밋 요청이 들어오면 Prepare과 Commit 두 단계를 거쳐 커밋 처리
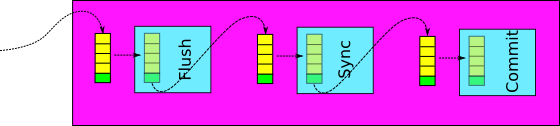
바이너리 로그 그룹 커밋 : 바이너리 로그 단의 처리 또한 여러 트랜잭션을 함께 처리할 수 있도록 도입
Flush:대기 큐에 등록된 각 트랜잭션들을순서대로 바이너리 로그에 기록Sync: 바이너리 로그 내용들을디스크와동기화하는fsync() 시스템 콜수행Commit: 대기 큐에 등록된트랜잭션들에 대해스토리지 엔진 커밋진행
Commit-parent 기반 LOGICAL CLOCK 방식
동일 시점에 커밋된 트랜잭션들은 레플리카 서버에서 병렬로 실행 가능
잠금(Lock) 기반 LOGICAL CLOCK 방식
커밋 처리 시점이 겹친다면 그 트랜잭션들은 레플리카 서버에서 병렬로 처리
WriteSet 기반 LOGICAL CLOCK 방식
트랜잭션이 변경한 데이터 기준으로 병렬 처리 가능 여부 결정
=> 동일한 데이터를 변경하지 않는 트랜잭션들은 레플리카 서버에서 병렬로 처리
멀티 스레드 복제와 복제 포지션 정보
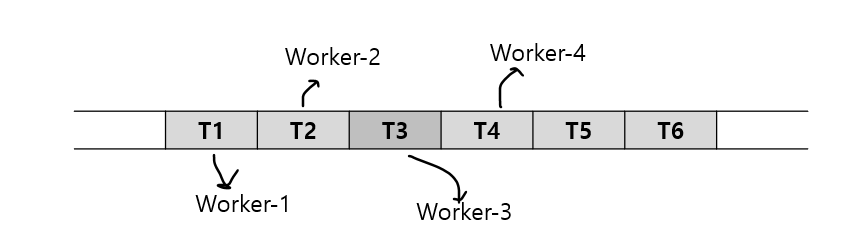
T3이 처리가 오래 걸리고, 다른 이벤트들은 T3보다 먼저 실행 완료됐더라도, 코디네이터 스레드에서 체크 포인트를 수행하면, T4가 완료됐다 해도 T3가 안끝나서 T2가 로우 워터마크 이벤트가 되고 어플라이어 메타데이터에서 포지션 값이 T2에 해당하는 값으로 업데이트
갭(Gap) : T3로 인해 이미 처리 완료된 T2와 T4 사이에 생겨난 포지션 간격
3. 크래시 세이프 복제(Crash-safe Replication)
레플리카 서버가 비정상 종료 된 후, 또다른 레플리카 서버가 존재하지 않는다면, 소스 서버는 레플리카 서버가 복구될 때까지 예비 서버 없이 운영
크래시 세이프 복제 : 서버 장애 이후에도 MySQL에서 문제없이 복제가 진행되도록 하는 것
서버 장애와 복제 실패
FILE 형태로 관리하는 경우
=> 비정상 종료시 처리한 내역과 포지션 정보 간 불일치
I/O 스레드가릴레이 로그에 이벤트 기록 후,포지션 정보 파일에 업데이트 하지 않은 상태에서 비정상 종료시,릴레이 로그에동일한 이벤트기록될 수 있음SQL 스레드가릴레이 로그에 기록된 트랜잭션을커밋한 후, 아직포지션 정보 파일에 업데이트 하지 않은 상태에서 비정상 종료시,동일한 트랜잭션 재실행
TABLE 형태로 관리하는 경우
=> 트랜잭션 적용과 포지션 정보 업데이트를 한 트랜잭션으로 묶어 처리하므로 SQL 스레드가 동일한 쿼리 재실행하는 문제 방지
I/O 스레드는 여전히 위와 같은 문제 발생 가능
=>relay_log_recovery옵션이 도입되며 해결
복제 사용 형태별 크래시 세이프 복제 설정
바이너리 로그 파일 위치 기반 복제 + 싱글 스레드 동기화
relay_log_recovery=ON
relay_log_info_repository=TABLE바이너리 로그 파일 위치 기반 복제 + 멀티 스레드 동기화
#커밋 순서 일치(소스 서버와)
relay_log_recovery=ON
relay_log_info_repository=TABLE
#커밋 순서 불일치
relay_log_recovery=ON
relay_log_info_repository=TABLE
sync_relay_log=1 #릴레이 로그를 디스크와 얼마나 자주 동기화GTID 기반 복제 + 싱글 스레드 동기화
#gtid_executed 테이블 데이터가 매 트랜잭션 적용 시 갱신되는 경우
relay_log_recovery=ON
source_auto_position=1 #복구 시 mysql.gtid_executed 데이터 참조, SQL 스레드가 마지막으로 적용한 트랜잭션의 GTID를 얻기 위함
#gtid_executed 테이블 데이터가 매 트랜잭션 적용 시 갱신되지 않는 경우
relay_log_recovery=ON
source_auto_position=1
sync_binlog=1
innodb_flush_log_at_trx_commit=1GTID 기반 복제 + 멀티 스레드 동기화
#gtid_executed 테이블 데이터가 매 트랜잭션 적용 시 갱신되는 경우
relay_log_recovery=ON
source_auto_position=1 #복구 시 mysql.gtid_executed 데이터 참조, SQL 스레드가 마지막으로 적용한 트랜잭션의 GTID를 얻기 위함
#gtid_executed 테이블 데이터가 매 트랜잭션 적용 시 갱신되지 않는 경우
relay_log_recovery=ON
source_auto_position=1
sync_binlog=1
innodb_flush_log_at_trx_commit=1멀티 스레드인 경우, relay_log_recovery=ON 설정으로 재구동시 트랜잭션 갭을 메우는 작업 수행
=> 해당 옵션 사용시 GTID 기반일 땐 생략됨
4. 필터링된 복제(Filtered Replication)
소스 서버의 특정 이벤트들만 레플리카 서버에 적용될 수 있도록 필터링
=> 데이터베이스 단위
https://dev.mysql.com/doc/refman/8.4/en/change-replication-filter.html
CHANGE REPLICATION FILTER filter[, filter]
[, ...] [FOR CHANNEL channel]
filter: {
REPLICATE_DO_DB = (db_list)
| REPLICATE_IGNORE_DB = (db_list)
| REPLICATE_DO_TABLE = (tbl_list)
| REPLICATE_IGNORE_TABLE = (tbl_list)
| REPLICATE_WILD_DO_TABLE = (wild_tbl_list)
| REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list)
| REPLICATE_REWRITE_DB = (db_pair_list)
}
db_list:
db_name[, db_name][, ...]
tbl_list:
db_name.table_name[, db_name.table_name][, ...]
wild_tbl_list:
'db_pattern.table_pattern'[, 'db_pattern.table_pattern'][, ...]
db_pair_list:
(db_pair)[, (db_pair)][, ...]
db_pair:
from_db, to_dbStatement 포맷은 USE문으로 지정된 데이터베이스 기반, Row 포맷은 실제 데이터베이스 기반 필터링 체크
Row 포맷 사용시
:DDL 문에 대해USE 문을 사용해 디폴트 데이터베이스 설정, 쿼리에서데이터베이스명 지정XSTATEMENT또는MIXED
:DML 및 DDL모두USE 문을 사용해디폴트데이터베이스 설정,쿼리에서 데이터베이스명 지정X,복제 대상 테이블과복제 제외 대상 테이블을모두 변경하는 DML 사용X
