📔설명
각종 데이터 타입과 가상 칼럼에 대해 알아보자
🥀문자열(CHAR와 VARCHAR)
1. 저장 공간
char타입 : 고정 길이
=> 실제 저장된 값의 유효 크기가 얼마인지 별도로 저장할 필요 없음
varchar타입 : 가변 길이
=> 저장된 값의 유효 크기가 얼마인지 별도로 저장해야 하므로 1~2바이트의 저장 공간이 추가로 필요
CHAR vs VARCHAR
- 저장되는 문자열의 길이가 대개
비슷한가? - 칼럼의 값이
자주 변경되는가?
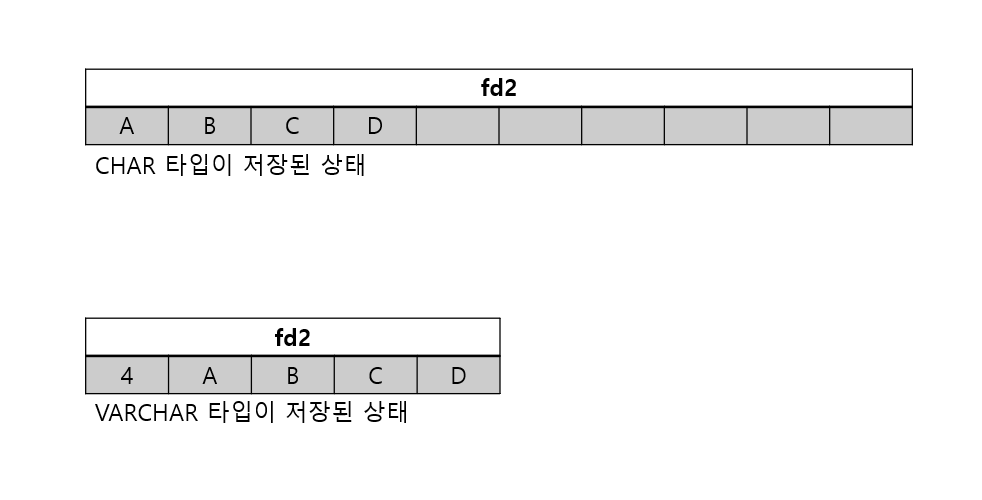
fd2 칼럼은 char(10)으로 저장됐을 땐 10바이트를 사용하면서, 앞의 4바이트만 유효한 값이며 나머지는 공백 문자로 채워짐
varchar(10)으로 저장되면, 해당 칼럼의 바이트 수를 저장하고, 그 이후 실제 칼럼 값을 저장
위 상태에서 ABCDE로 값을 변경했다고 가정
CHAR(10)일 땐, 10바이트가 준비돼 있으므로 그냥 변경되는 칼럼의 값 업데이트 하면 됨VARCHAR(10)일 땐,ROW MIGRATION필요
=> 레코드 자체를다른 공간으로 옮겨야 함
뒤에 지정하는 숫자는 문자의 수를 뜻함
2. 저장 공간과 스키마 변경(Online DDL)
varchar 데이터 타입을 사용하는 칼럼의 길이를 늘리는 작업은 매우 빠르게 처리될 수 있으나, 테이블에 대해 읽기 잠금을 걸고 레코드를 복사해야 할 수 있음
문자열 길이를 저장하는 공간의 크기가 바뀌게 되면, 읽기 잠금을 걸어서 아무도 데이터를 변경하지 못하도록 막고 테이블의 레코드를 복사하는 방식으로 처리
3. 문자 집합(캐릭터 셋)
#사용 가능한 문자 집합
show character set;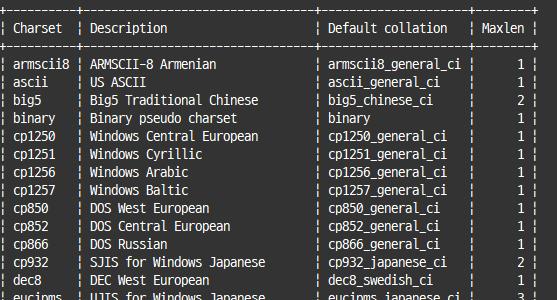
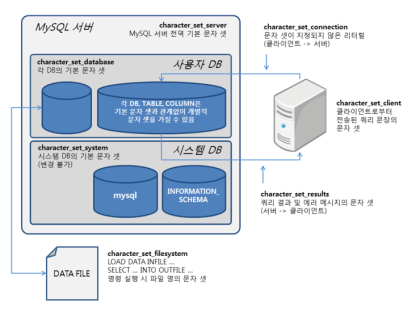
클라이언트로부터 쿼리 요청시 문자 집합 변환
MySQL 서버는 클라이언트로부터 받은 메시지를 character_set_client에 지정된 문자 집합으로 인코딩돼 있다고 판단 후, 받은 문자열 데이터를 character_set_connection에 정의된 문자 집합으로 변환
인트로듀서 : 별도의 문자 집합을 설정하는 지정자
select emp_no, first_name
from employees
where first_name=_latin1'Matt';처리 결과를 클라이언트로 전송할 때 문자 집합 변환
쿼리 결과를 character_set_results 변수에 설정된 문자 집합으로 변환해 클라이언트로 전송
4. 콜레이션(Collation)
콜레이션 : 문자열 칼럼의 값에 대한 비교나 정렬 순서를 위한 규칙
=> ex. 영어 대소문자를 같은 것으로 처리할지
콜레이션 이해
#콜레이션 목록
show collation;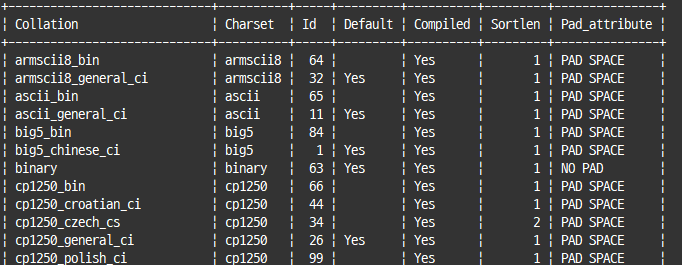
3개의 파트로 구성된 콜레이션 이름
- 문자 집합 이름
- 문자 집합 하위 분류
대문자나소문자구분 여부
=>ci:구분X,cs:구분
2개의 파트로 구성된 콜레이션 이름
- 문자 집합 이름
bin이라는 키워드 사용
=> 별도의 콜레이션X
=> 비교 및 정렬은 실제 문자 데이터의바이트 값을 기준으로 수행
문자 집합, 콜레이션, 타입 이름, 문자열 길이까지 같아야 똑같은 타입
create table ~~(
member_name varchar(20) not null collate uft8_bin,
...
);utf8mb4 문자 집합의 콜레이션
범용 응용 프로그램이라면 utf8mb4_0900_ai_ci로 충분
no pad 옵션 : 문자열 뒤에 존재하는 공백도 유효 문자 취급
5. 비교 방식
utf8bm4_0900_bin 콜레이션 사용 시 문자열 뒤의 공백이 비교 결과에 영향 미침
select 'ABC'='ABC ' as is_equal;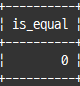
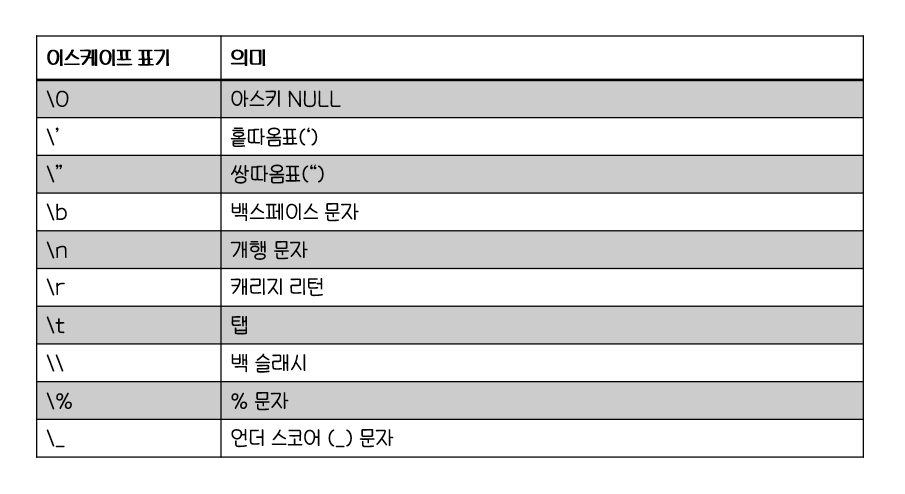
6. 문자열 이스케이프 처리
🌱숫자
참값(Exact value) : 소수점 이하 값의 유무와 관계없이 정확히 그 값을 그대로 유지
=> int, decimal
근삿값 : 부동 소수점이라고 하며, 처음 칼럼에 저장한 값과 조회된 값이 정확하게 일치하지 않고 최대한 비슷한 값으로 관리하는 것
=> float, double
이진 표기법 : 정수나 실수 타입
십진 표기법(DECIMAL) : 숫자 값의 각 자릿값을 표현하기 위해 4비트나 한 바이트를 사용해서 표기
=> 디스크나 메모리에 십진 표기법으로 저장됨
1. 정수
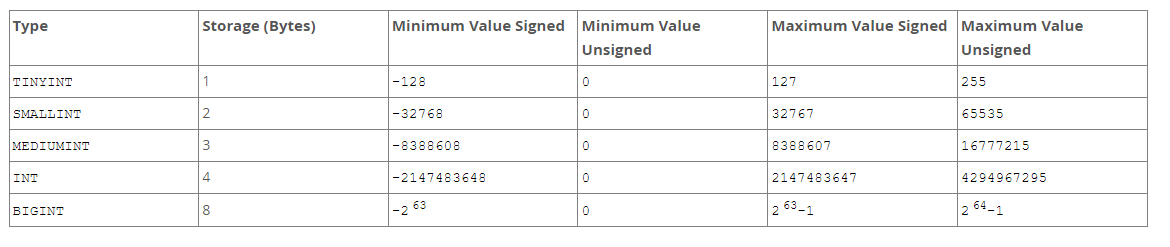
unsigned로 설정하면 0보다 큰 양의 정수만 저장 가능
2. 부동 소수점
근삿값을 저장하므로 동등 비교는 사용 불가
3. DECIMAL
DECIMAL : 소수점의 위치가 가변적이지 않은 고정 소수점 타입
4. 정수 타입 칼럼 생성시 주의사항
decimal(20,5)
# 정수부 : 15(20-5)
# 소수부 : 55. 자동 증가(AUTO_INCREMENT) 옵션 사용
auto_increment_offset : 초기값
auto_increment_increment : 증가값
auto_increment 옵션 사용한 칼럼은 반드시 그 테이블에서 프라이머리 키나 유니크 키의 일부로 정의해야 함
=> innodb에서는 auto_increment 칼럼을 프라이머리 키(또는 인덱스)의 시작에 배치해야 함
=> 프라이머리 키의 뒤쪽에 배치했으나, 유니크 키에서 선두에 위치하면 정상 생성
🌲날짜와 시간
YEAR, DATE, TIME, DATETIME, TIMESTAMP 등의 타입
TIMESTAMP는 UTC 타임존으로 저장되므로 타임존이 달라지면 값도 자동으로 보정
DATETIME은 타임존에 대해 아무런 변환 처리 수행X
#기본 타임존 확인
show variables like '%time_zone%';
system_time_zone : MySQL 서버의 타임존
time_zone : 클라이언트 커넥션의 기본 타임존
커넥션에서 시간 관련 처리할 땐 time_zone 시스템 변수 영향만 받음
1. 자동 업데이트
TIMESTAMP와 DATETIME 칼럼 모두 insert 와 update 실행 시 해당 시점으로 자동 업데이트 되게 하려면 테이블 생성시 칼럼 정의 뒤에 옵션 정의
create table tb_autoupdate(
update_ts timestamp default current_timestamp on update current_timestamp;
...
);default current_timestamp : INSERT될 때의 시점 자동 업데이트
on update current_timestamp : UPDATE될 때의 시점 자동 업데이트
🌳ENUM과 SET
문자열 값을 내부적으로 숫자 값으로 매핑해서 관리하는 타입
1. ENUM
테이블의 구조에 나열된 목록 중 하나의 값을 가질 수 있음
create table tb_enum(
fd_enum enum('PROCESSING', 'FAILURE', 'SUCCESS')
);
insert into tb_enum values ('PROCESSING'),('FAILURE');
select * from tb_enum;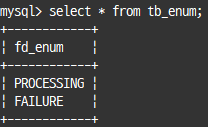
#숫자 연산 수행시 내부적으로 저장된 숫자값으로 연산 실행
select * from tb_enum where fd_enum=1;
ENUM 타입의 제일 마지막으로 새로운 값 추가시 테이블 구조 변경만으로 즉시 완료
디스크 저장 공간의 크기를 줄여줌
2. SET
하나의 칼럼에 1개 이상의 값을 저장 가능
=> BIT-OR 연산을 거쳐 선택된 값 저장
create table tb_set(
fd_set SET('TENNIS','SOCCER','GOLF','TABLE-TENNIS','BASKETBALL','BILLIARD')
);
insert into tb_set (fd_set) values ('SOCCER'),('GOLF,TENNIS');
select * from tb_set;
FIND_IN_SET() : 문자열 멤버를 가진 레코드 검색시
=> 인덱스 사용 불가
select * from tb_set where find_in_set('GOLF',fd_set);
🌴TEXT와 BLOB
TEXT 타입 : 문자열을 저장하는 대용량 칼럼
=> 문자 집합이나 콜레이션 가짐
BLOB 타입 : 이진 데이터 타입
=> 별도의 문자집합 또는 콜레이션 안가짐
인덱스 생성시 칼럼값의 몇 바이트까지 인덱스를 생성할 것인지 명시해야 할 때도 있음
🌵공간 데이터 타입
POINT, LINESTRING, POLYGON, GEOMETRY는 하나의 객체만 저장할 수 있음
MULTIPOINT, MULTILINESTRING, MULTIPOLYGON는 여러 개의 객체 저장 가능
공간 데이터는 BLOB 타입으로 저장되며, 실제 저장하는 데이터가 크지 않다면 외부 페이지로 저장하지 않으므로 걱정X
1. 공간 데이터 생성
WKT(Well Known Text)를 이진 데이터 포맷으로 변환
#point 타입
#wkt 포맷
point(x y)
#객체 생성
st_pointfromtext('point(x y)')#linestring 타입
#wkt 포맷
linestring(x0 y0, x1 y1,...)
#객체 생성
st_linestringfromtext('linestring(x0 y0, x1 y1, ...)')#polygon 타입
#wkt 포맷
polygon((x0 y0, x1 y1, x2 y2, x3 y3, x0 y0))
#객체 생성
st_polygonfromtext('polygon((x0 y0, x1 y1, x2 y2, x3 y3, x0 y0))')2. 공간 데이터 조회
- 이진 데이터 조회(WKB 또는 MySQL 이진 포맷)
=>ST_AsBinary()/ST_AsWKB() - 텍스트 데이터 조회(WKT)
=>ST_AsTEXT()/ST_AsWKT() - 공간 데이터의 속성 함수를 이용한 조회
=> ex. point 타입의st_x()와st_latitude()함수
🌾JSON 타입
MongoDB와 같이 바이너리 포맷의 BSON(Binary JSON)으로 변환해서 저장
1. 저장 방식
내부적으로 JSON 타입의 값을 BLOB 타입에 저장하지만, BSON 타입으로 변환해서 저장
JSON 칼럼의 특정 필드만 참조 및 업데이트 할 경우, 즉시 원하는 필드의 이름을 읽거나 변경 가능
부분 업데이트가 필요한 경우 blob 페이지 인덱스와 json 칼럼의 각 필드 주소 정보를 이용해 변경이 필요한 부분만 업데이트
2. 부분 업데이트 성능
json_set(), json_replace(), json_remove()를 이용하는 경우만 작동
#JSON 칼럼 값에서 user_id 필드값 12345로 변경
update tb_json
set fd=json_set(fd,'$.user_id',"12345")
where id=2;3. JSON 타입 콜레이션과 비교
utf8mb4_bin 콜레이션을 가지므로, 대소문자 구분과 액센트 문자 등도 구분
4. JSON 칼럼 선택
JSON 데이터를 저장해야한다면, Blob 보단 json 칼럼을 선택
=> 성능 중심이라면 정규화된 칼럼
🌿가상 칼럼(파생 칼럼)
가상 칼럼은 가상 칼럼과 스토어드 칼럼으로 구분
#가상 칼럼
create table ~~(
total_price decimal(10,2) as (quantity*price) virtual,
...
);#스토어드 칼럼
create table ~~(
total_price decimal(10,2) as (quantity*price) stored,
...
);가상 칼럼 : 다른 칼럼의 값을 참조해서 계산된 값 관리
가상 칼럼(Virtual Column)
- 칼럼 값이 디스크에 저장 X
- 칼럼 구조 변경이 테이블 리빌드 필요X
- 칼럼 값은 레코드가 읽히기 전 또는 before 트리거 실행 직후에 계산
스토어드 칼럼(Stored Column)
- 물리적으로 디스크에 저장
- 테이블 리빌드 방식으로 처리
- insert와 update 시점에만 칼럼 값 계산
