📔설명
InnoDB 클러스터에 대해 알아보자
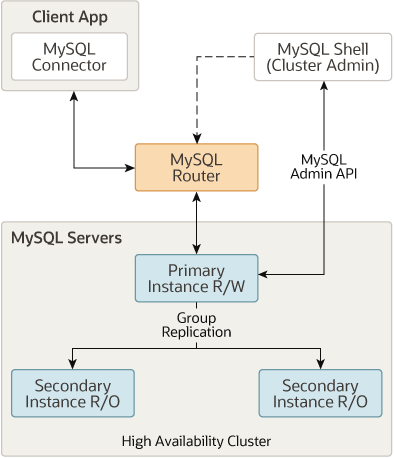
🧨InnoDB 클러스터 아키텍처
InnoDB 클러스터 : MySQL의 고가용성(HA) 실현을 위해 만들어진 여러 구성 요소들의 집합체
구성 요소
그룹 복제(Group Replication): 소스 서버의 데이터를 레플리카 서버로동기화하는 복제 역할, MySQL 서버에 대한자동화된 멤버십 관리역할MySQL 라우터(MySQL Router):애플리케이션 서버와MySQL 서버사이에 동작하는미들웨어로,애플리케이션이 실행한쿼리를적절한 MySQL 서버로 전달하는프락시(Proxy)역할MySQL 셸(MySQL Shell): 새로운클라이언트 프로그램으로, SQL문 실행뿐만 아니라자바스크립트및파이썬기반의스크립트작성 기능,어드민 작업을 할 수 있게 해주는API제공
-
InnoDB 클러스터에서 데이터가 저장되는 MySQL 서버들은그룹 복제 형태로복제구성
=> 각서버는읽기/쓰기가 모두 가능한프라이머리또는읽기만 가능한세컨더리중 하나의 역할
=>프라이머리- 기존 복제에서소스 서버
=>세컨더리-레플리카 서버 -
서버를
최소 3대 이상으로 구성 -
클라이언트는MySQL 서버로직접 접근X,MySQL 라우터에 연결해서 쿼리 실행
=>MySQL 라우터는MySQL 서버에 대한메타데이터정보를 지니며, 이를 바탕으로클라이언트로부터 실행된 쿼리를 적절한MySQL 서버로 전달 -
MySQL 셸: 사용자가InnoDB 클러스터를생성및관리할 수 있도록API 제공, InnoDB 클러스터의상태 확인또는 MySQL 서버의설정 변경기능 제공
=>InnoDB 클러스터관련 작업 진행시MySQL 서버에직접 연결해서 작업해야 함 -
MySQL 서버에
장애발생시,그룹 복제가감지해서자동으로 해당 서버복제 그룹 제외,MySQL 라우터는클라이언트로부터 실행된 쿼리가정상 작동 서버로만 전달될 수 있도록 함
✨그룹 복제(Group Replication)
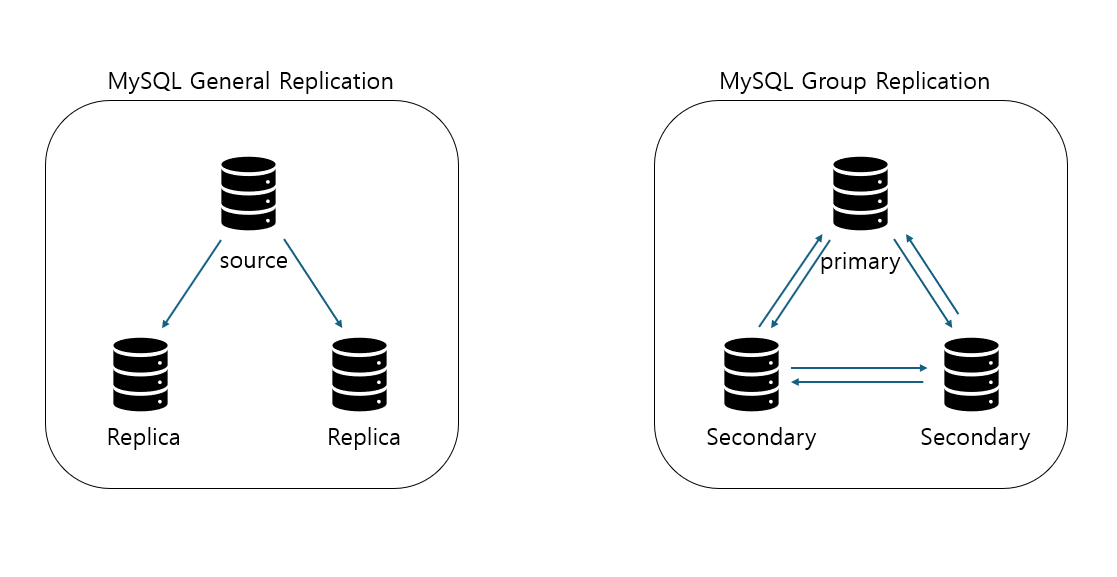
그룹 복제 : 복제 프레임워크를 기반으로 구현, Row 포맷의 바이너리 로그, 릴레이 로그, GTID 사용
=> 기존 복제와 달리 복제에 참여하는 MySQL 서버들이 하나의 복제 그룹으로 묶인 클러스터 형태를 가지며, 그룹 내 서버들은 서로 통신하면서 양방향 복제 처리
=> 그룹 멤버 : 그룹 복제에 참여하는 서버들
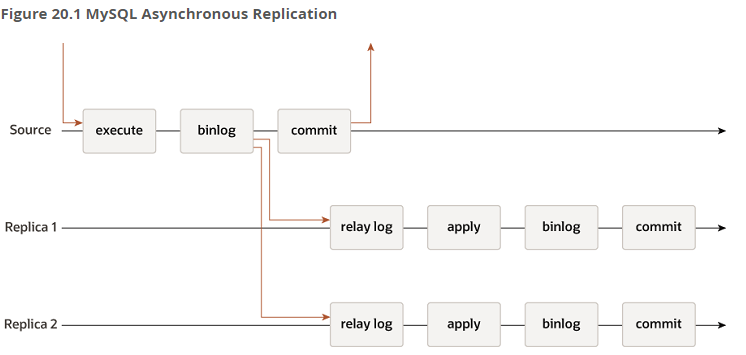
소스 서버에서의 트랜잭션 커밋 처리가 레플리카 서버와는 무관
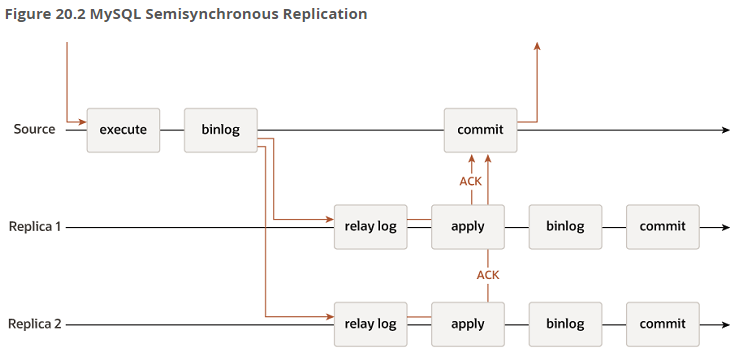
소스 서버에서 트랜잭션 커밋 처리 중 레플리카 서버로 트랜잭션이 잘 전달됐는지 응답을 기다린 후 최종적으로 커밋 처리
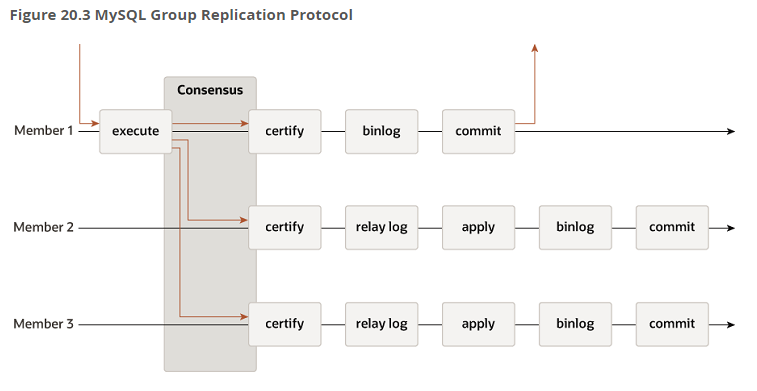
그룹 내 다른 멤버들의 응답을 확인하는 단계 존재
=> 트랜잭션 커밋할 준비 되면, 다른 멤버들에게 전송 후 과반수 이상 응답 받으면 해당 트랜잭션을 인증하고 최종적으로 커밋
=> 과반수 이상 응답 못받으면 해당 트랜잭션 적용X
1. 그룹 복제 아키텍처
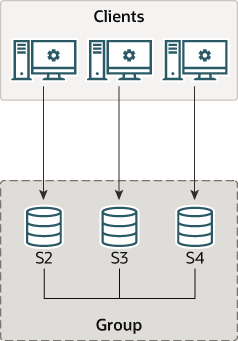
그룹 복제에 참여하는 MySQL 서버들은 group_replication_applier라는 복제 채널을 생성하며, 해당 채널을 통해 트랜잭션 전달받아 처리
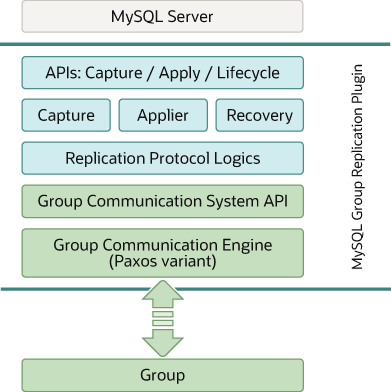
최상위 계층 : 그룹 복제 플러그인이 MySQL 서버와 상호작용하기 위해 구현된 플러그인 API 집합
=> API를 통해 그룹 복제 플러그인 혹은 반대 방향으로 요청 전달
=> MySQL 서버의 시작 또는 복구, 트랜잭션 커밋 등의 이벤트를 그룹 복제 플러그인에 전달하고 그룹 복제 플러그인에서는 처리 중인 트랜잭션에 대한 커밋 또는 중단, 릴레이 로그 기록 요청 등을 서버에 전달
복제 플러그인 계층 : 그룹 복제의 기능들이 실질적으로 구현
=> 로컬 및 그룹 복제의 다른 MySQL 서버에서 실행된 원격 트랜잭션들이 처리
=> 트랜잭션들에 대한 충돌 감지 및 그룹 내 전파 등이 수행
=> 그룹 복제의 분산 복구 작업
그룹 통신 시스템 API와 그룹 통신 엔진 : 상위 플러그인 계층에서 그룹 통신 시스템 API를 통해 그룹 통신 엔진과 상호작용
=> 그룹 통신 엔진 : 그룹 복제에 참여 중인 다른 MySQL 서버들과의 통신 처리 담당
=> 그룹 통신 엔진은 트랜잭션이 그룹 복제 멤버들에 동일한 순서로 전달되도록 보장, 토폴로지 변경과 그룹 멤버의 장애 등 감지
2. 그룹 복제 모드
쓰기를 처리할 수 있는 프라이머리 서버 수에 따라 싱글 프라이머리 모드와 멀티 프라이머리 모드로 나뉨
싱글 프라이머리 모드
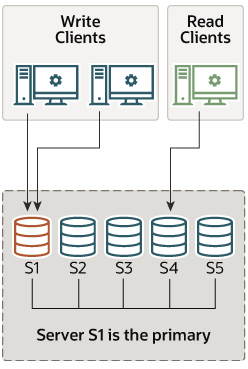
쓰기를 처리할 수 있는 프라이머리 서버가 한 대만 존재
=> 그룹 복제 구축을 진행한 서버가 프라이머리로 지정됨
싱글 프라이머리 모드 동작 중 그룹 내 프라이머리 서버가 변경될 경우
자발적혹은예기치않게현재프라이머리 서버가그룹 탈퇴하는 경우새로운 프라이머리로그룹의 특정 멤버지정한 경우
그룹 복제가 새로운 프라이머리 선출하는 우선순위
1. MySQL 서버 버전 : 가장 낮은 버전
2. 각 멤버의 가중치 값 : 가중치 값 비교
3. UUID 값의 사전식 순서 : 가장 낮은 값
멀티 프라이머리 모드
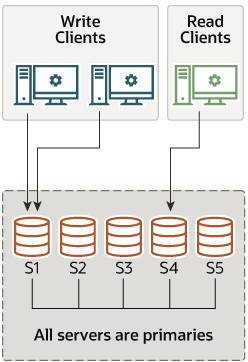
그룹 멤버들이 전부 프라이머리로 동작하는 형태
3. 그룹 멤버 관리(Group Membership)
현재 어떤 서버들이 그룹에 참여하고 있는지 목록과 상태 관리
4. 그룹 복제에서의 트랜잭션 처리
그룹 복제에서 트랜잭션은 합의(Consensus)와 인증(Certification) 단계를 거친 후 최종적으로 그룹의 각 서버들에 적용
합의 : 일관된 트랜잭션 적용을 위해 그룹 멤버들에게 트랜잭션 적용을 제안하고 승낙받는 과정
=> 클라이언트가 한 그룹 멤버에서 트랜잭션 실행 후 커밋 요청 보내면, 해당 그룹 멤버는 그룹 통신 엔진을 통해 트랜잭션에서 변경한 데이터에 대한 WriteSet과 커밋될 당시의 gtid_executed 스냅샷 정보, 트랜잭션의 이벤트 로그 데이터 등이 포함된 데이터를 다른 멤버로 전파
다수의 그룹 멤버들에서 실행된 트랜잭션들은 합의 단계를 거친 후 정렬되어, 각 멤버들에서 모두 동일한 순서로 인증 단계 거침
=> 트랜잭션 충돌 여부 확인
트랜잭션 일관성 수준
group_replication_consistency 변수를 통해 그룹 복제에서의 트랜잭션 일관성 수준 설정 가능
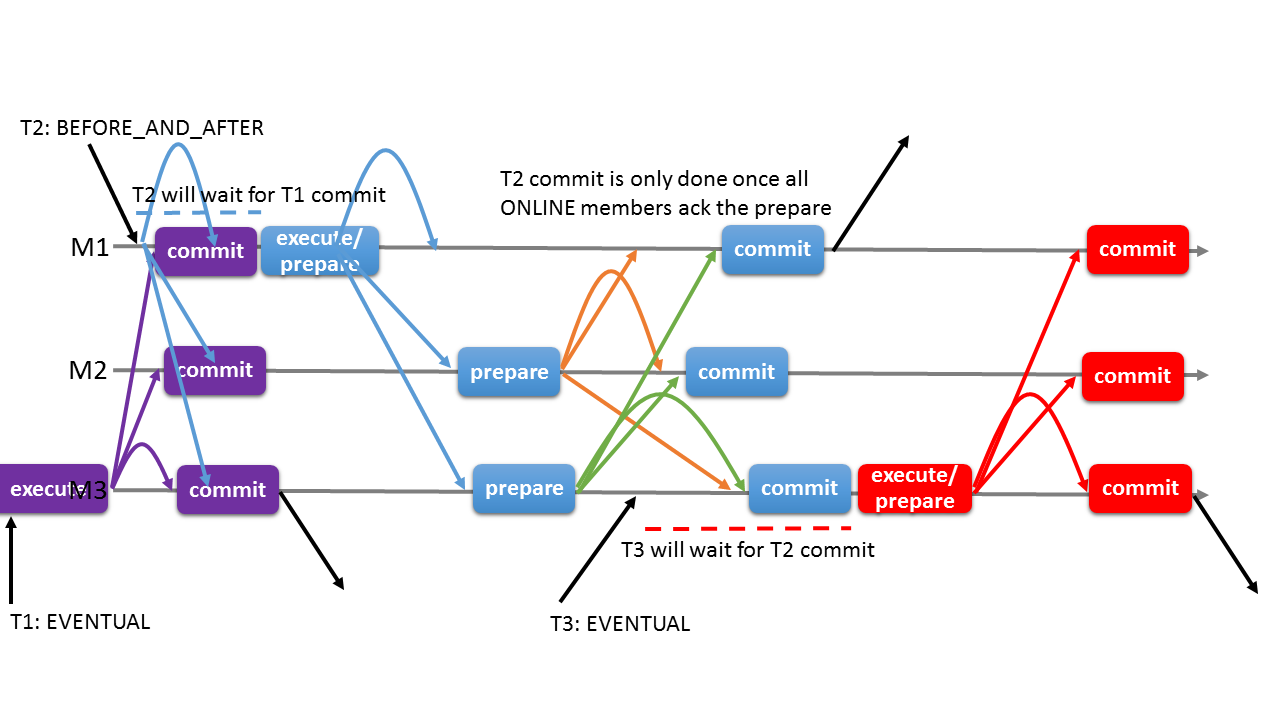
EVENTUAL 일관성 수준
최종적으로는 멤버들이 일관된 데이터를 가지게 됨
=> 오래된 데이터를 읽을 수 있음
=> 트랜잭션과 충돌시 롤백 가능성 존재
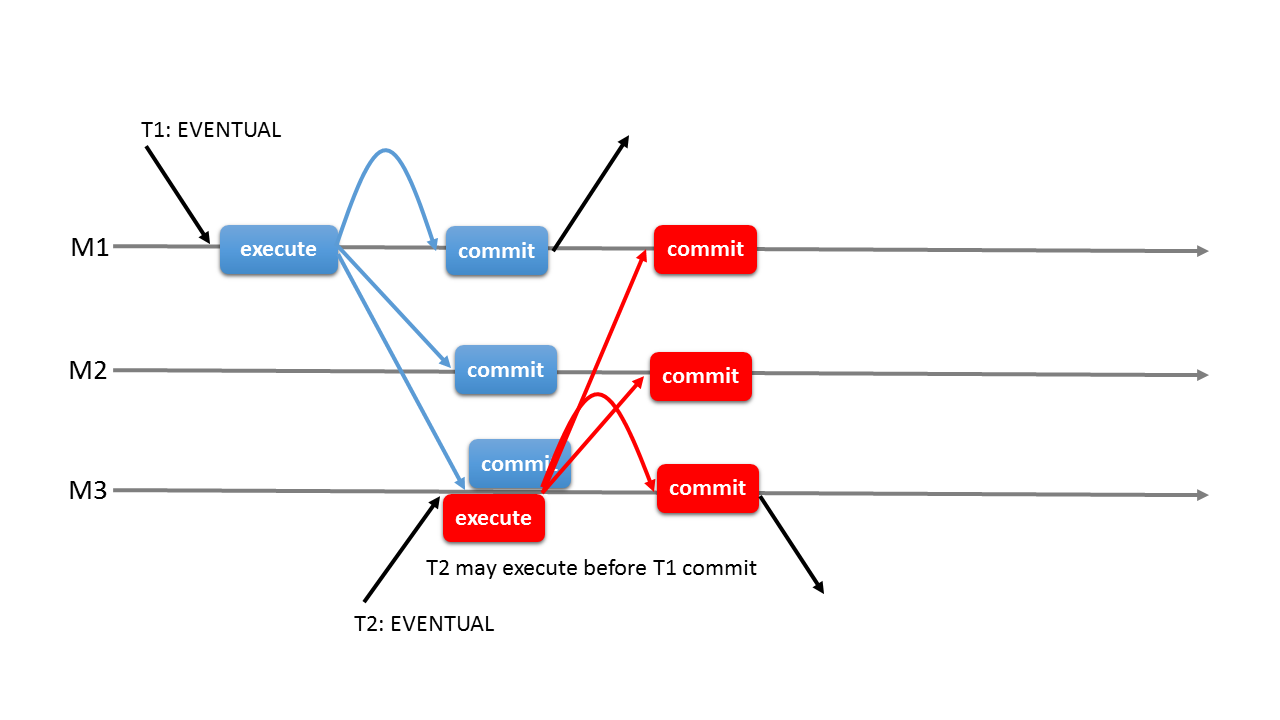
BEFORE_ON_PRIMARY_FAILOVER 일관성 수준
싱글 프라이머리 모드로 설정된 그룹 복제에서 프라이머리 페일오버 발생해 신규 프라이머리 선출시 트랜잭션에 영향
=> 이전 프라이머리의 트랜잭션이 모두 적용될 때까지 대기
=> 신규 프라이머리로 유입된 읽기 전용 및 읽기-쓰기 트랜잭션들은 오래된 데이터가 아닌 최신 데이터 바탕으로 동작
=> 적용 대기 중인 이전 프라이머리 트랜잭션과 충돌로 롤백X
BEFORE 일관성 수준
모든 선행 트랜잭션이 완료될 때까지 대기 후 처리
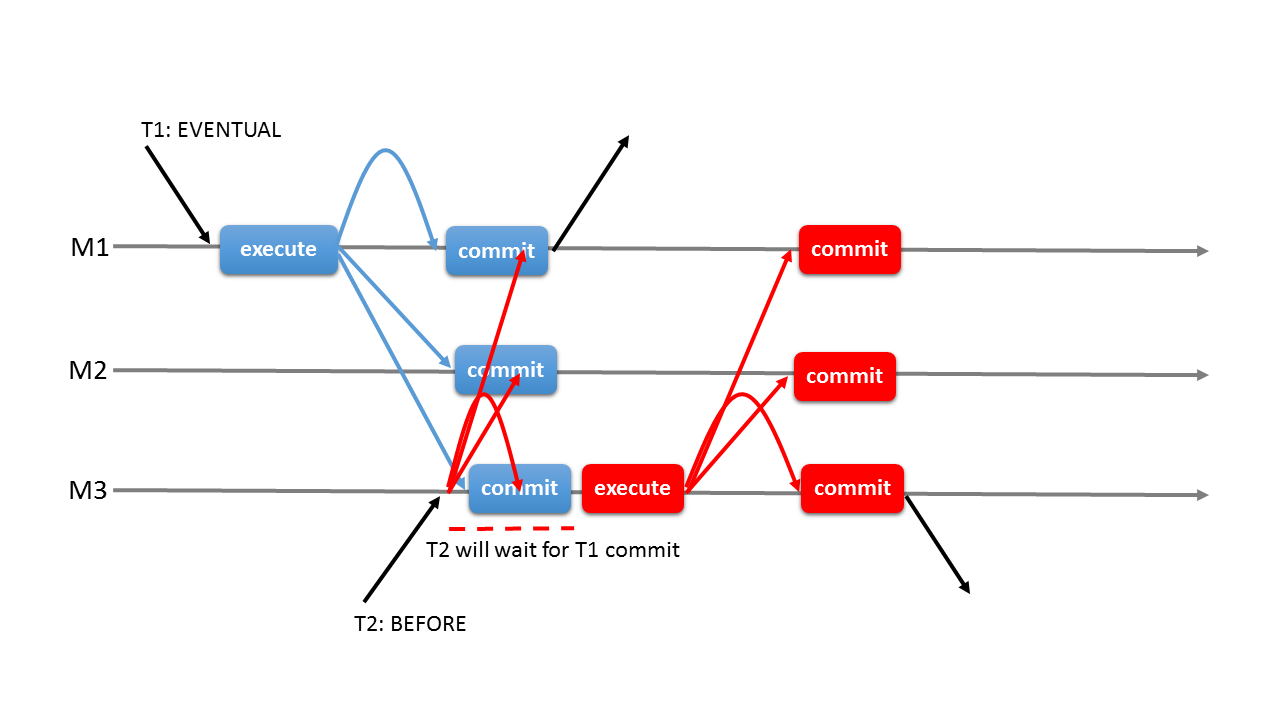
AFTER 일관성 수준
트랜잭션 적용 시 해당 시점에 그룹 멤버들이 모두 동기화된 데이터를 갖게 함
=> 읽기-쓰기 트랜잭션은 다른 모든 멤버들에서도 해당 트랜잭션이 커밋될 준비가 됐을 때까지 대기 후 처리
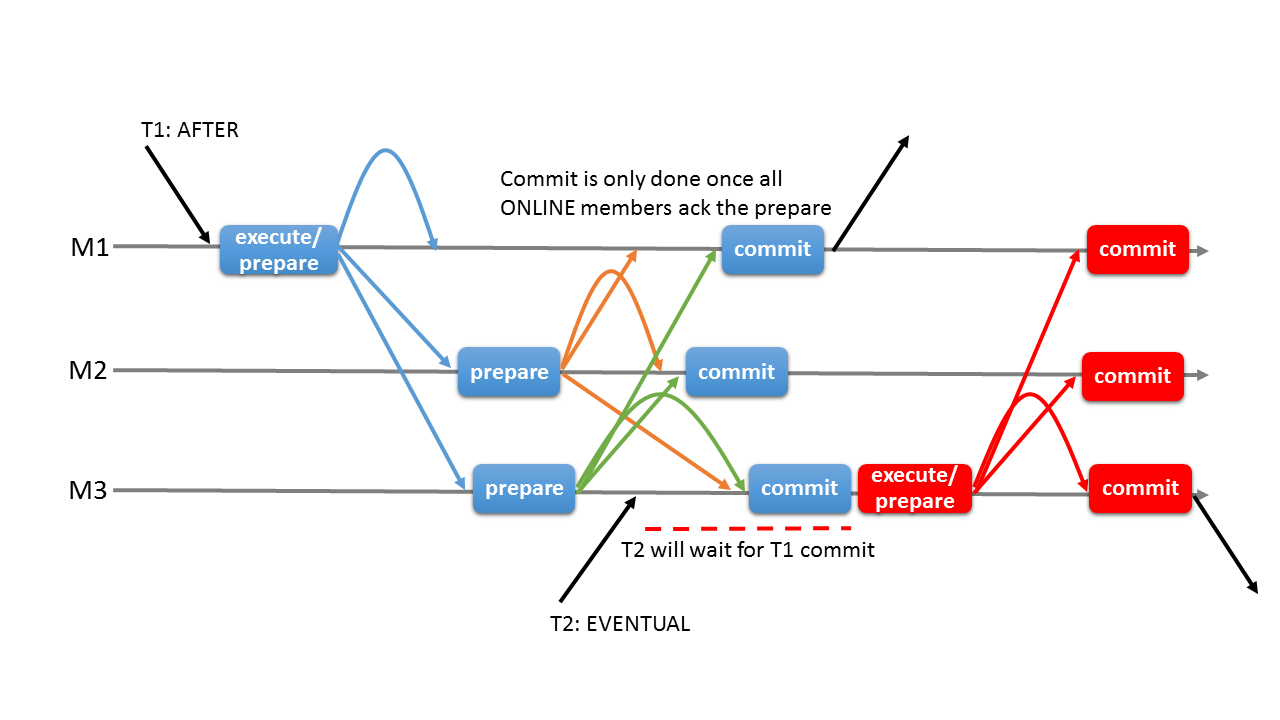
BEFORE_AND_AFTER 일관성 수준
읽기-쓰기 트랜잭션은 모든 선행 트랜잭션이 적용될 때까지 대기 후 실행, 다른 모든 멤버들에서도 커밋 준비되어 응답시 최종적 커밋
읽기 트랜잭션은 모든 선행 트랜잭션 적용 대기 후 실행
흐름 제어(Flow Control)
지연된 멤버에서 트랜잭션 실행 시, 오래된 데이터를 읽을 수 있으므로 해결해야 함
=> 흐름 제어 : 그룹 멤버들의 쓰기 처리량을 조절하는 메커니즘
5. 그룹 복제의 자동 장애 감지 및 대응
문제 상태에 있는 멤버를 식별하고 해당 멤버를 그룹 복제에서 제외시킴으로써 그룹이 정상적으로 동작 중인 멤버로만 구성될 수 있게 함
6. 그룹 복제의 분산 복구
분산 복구 : 멤버가 그룹 가입 시 다른 그룹 멤버들과 동일한 최신 데이터를 가질 수 있도록 가입 멤버에서 누락된 트랜잭션들을 다른 그룹 멤버에서 가져와 적용하는 복구 프로세스
기증자(Donor) : 가입 멤버가 복구 작업을 위해 선택한 기존 그룹 멤버
분산 복구 방식
바이너리 로그 복제 방식: 가입 멤버에 적용되지 않은 트랜잭션들을복제해서 가져와 가입 멤버에 적용원격 클론 방식:모든 데이터와메타데이터를 일관된스냅샷으로 가져와가입 멤버재구축
분산 복구 프로세스
로컬 복구:가입 멤버가 이전에 그룹에가입한 적이 있는 경우, 릴레이 로그에 미쳐 적용하지 못한 트랜잭션 먼저 적용 후 복구 작업 진행글로벌 복구:기증자 멤버를 선택해데이터또는누락된 트랜잭션을 가져와 적용,현재 처리되는 트랜잭션들은내부적으로 캐싱캐시 트랜잭션 적용:캐싱해서 보관하던 트랜잭션들을 적용해 최종적으로 그룹에 참여
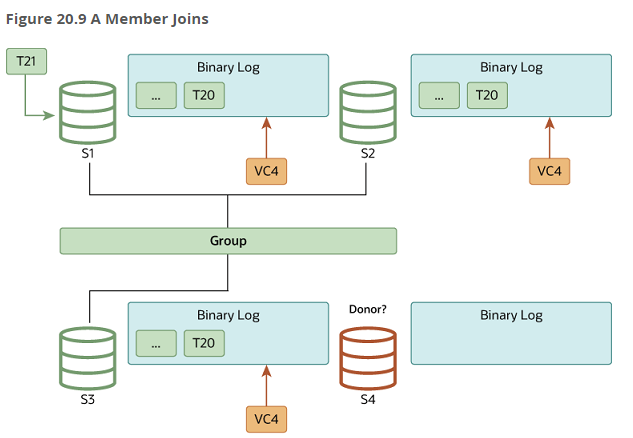
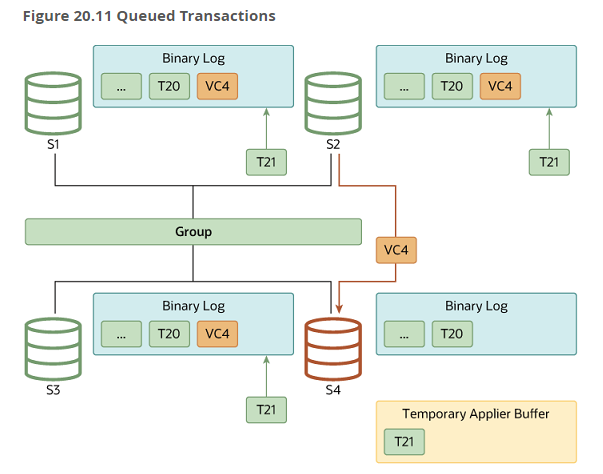
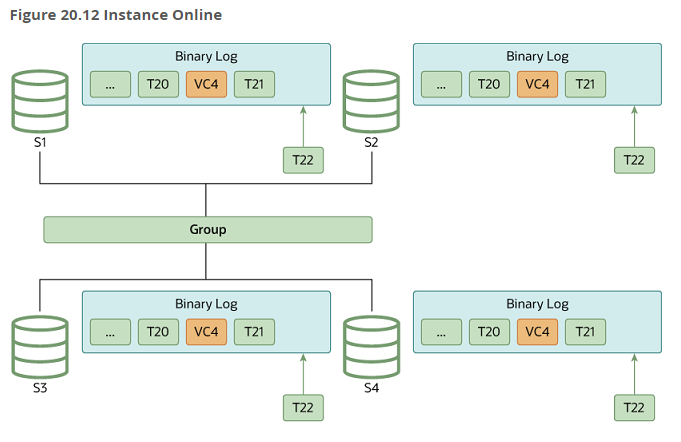
분산 복구 설정
- 연결 시도 횟수
- 연결 시도 간격
- 가입한 멤버를 온라인으로 표기하는 시점
분산 복구 오류 처리
분산 복구 도중 문제 발생시 자동으로 새로운 그룹 멤버로 연결 전환
기증자로 선택한 멤버로의연결이 정상적으로 이뤄지지 않은 경우바이너리 로그 복제 방식으로 복구 작업 진행 중레플리케이션 I/O 스레드또는SQL 스레드에서 에러 발생한 경우원격 클론 작업이실패하거나중단된 경우복구 작업동안기증자 멤버에서그룹 복제가중단된 경우
7. 그룹 복제 요구사항
InnoDB스토리지 엔진 사용프라이머리 키사용- 원활한
네트워크 통신환경 바이너리 로그활성화ROW형태의 바이너리 로그 포맷 사용- 바이너리 로그
체크섬설정 log_slave_updates활성화GTID사용- 고유한
server_id값 사용 - 복제
메타데이터 저장소설정 - 트랜잭션
WriteSet설정 테이블스페이스 암호화설정lower_case_table_names설정멀티 스레드 복제설정
8. 그룹 복제 제약 사항
트랜잭션 격리 수준을READ-COMMITED로 사용하는 것이 좋음테이블 락및네임드 락고려 X멀티 프라이머리 모드는serializable격리 수준 사용 X동일한 테이블에 대해서로 다른 멤버에서 동시에 실행되는DDL및DML지원XCASCADE제약 조건 사용된 테이블 지원X
🎉MySQL 셸
MySQL 셸 : MySQL을 위한 고급 클라이언트 툴
=> 기본적으로 자바스크립트 모드로 동작
\py #파이썬 모드로 전환
\sql #sql모드로 전환
\js #자바스크립트 모드로 전환API 제공
X DevAPI:관계형 데이터와문서 기반 데이터모두 처리AdminAPI:InnoDB 클러스터관련 설정
🎊MySQL 라우터
MySQL 라우터 : InnoDB 클러스터에서 애플리케이션 서버로부터 유입된 쿼리 요청을 클러스터 내 적절한 MySQL 서버로 전달하고 MySQL 서버에서 반환된 쿼리 결과를 다시 애플리케이션 서버로 전달하는 프락시 역할
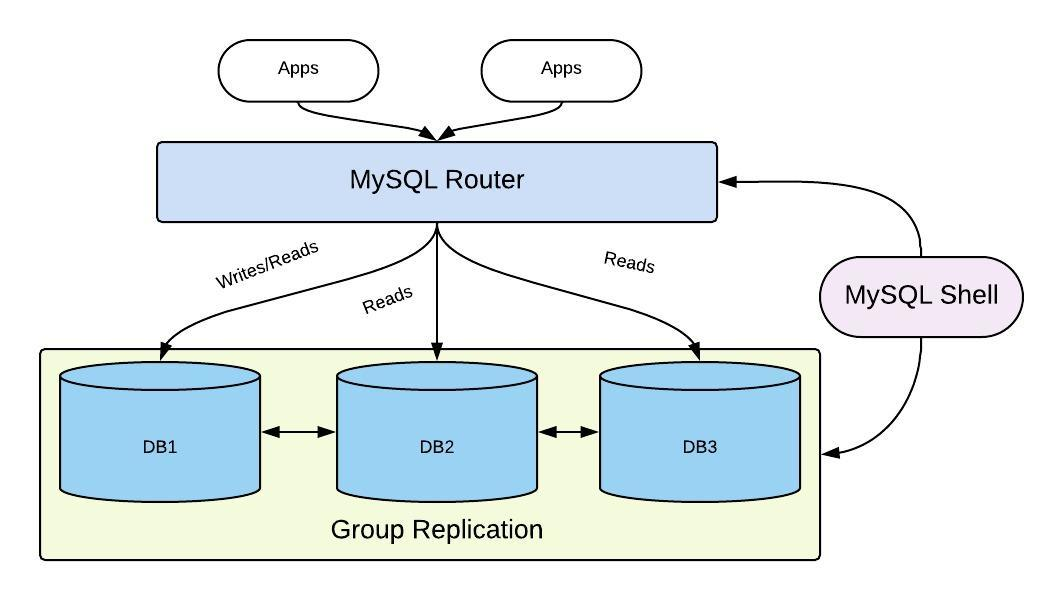
- InnoDB 클러스터의
MySQL 구성 변경자동 감지 - 쿼리 부하 분산
- 자동 페일오버
🎃InnoDB 클러스터 구축
1. InnoDB 클러스터 요구사항
최소한의 버전 요구Performance 스키마활성화파이썬설치
2. InnoDB 클러스터 생성
사전 준비
#MySQL 셸 접속
$mysqlsh//dba.configureInstance() : 인자 서버에 접속해 InnoDB 클러스터 요구사항 충족하는지 확인
$dba.configureInstance("root@localhost:3306")InnoDB 클러스터 생성
MySQL 서버 중 한 대에 접속
\connect ~~@~~~//dba.createCluster() : 클러스터 생성
var cluster=dba.createCluster("testCluster")
//멀티로 생성하고 싶을 경우
var cluster=dba.createCluster("testCluster",{multiPrimary:true})//상태 조회
var cluster=dba.getCluster()
cluster.status()InnoDB 클러스터 인스턴스 추가
<cluster>.addInstance() 메서드를 통해 서버 추가
//현재 클러스터에 존재하는 MySQL 서버 중 한 대에 접속
var cluster=dba.getCluster()
cluster.addInstance("~~~@~~~")MySQL 라우터 설정
별도의 라우터용 서버가 존재한 경우, InnoDB 클러스터에서 사용할 라우터 서버 구성을 위해 라우터용 서버에서 아래 명령 실행
#라우터 부트스트랩
mysqlrouter --bootstrap 계정명@주소:3306 --name icrouter1 \
--directory /tmp/myrouter --account icrouter --user root#라우터 실행
/tmp/myrouter/start.sh🎄InnoDB 클러스터 모니터링
//클러스터 복제 토폴로지 구성 확인
cluster.describe()//클러스터 전반적인 상태
//자세히 표시
cluster.status({'extended':1}) 🎋InnoDB 클러스터 작업
1. 클러스터 모드 변경
싱글 프라이머리 모드와 멀티 프라이머리 모드 전환
cluster.switchToMultiPrimaryMode()
//멀티 프라이머리 모드로 전환
cluster.switchToSinglePrimaryMode([instance])
//싱글 프라이머리 모드로 전환2. 프라이머리 변경
프라이머리 서버를 강제로 특정 서버로 변경
cluster.setPrimaryInstance(instance)
//인자 인스턴스를 새로운 프라이머리 서버로3. 인스턴스 제거
클러스터의 특정 인스턴스 제거
cluster.removeInstance(instance)4. 클러스터 해체
클러스터의 사용 종료 혹은 클러스터 단위의 설정 변경 등으로 인한 경우
cluster.dissolve()5. 클러스터 및 인스턴스 설정 변경
현재 동작 중인 클러스터 및 인스턴스 설정을 온라인으로 변경
//클러스터 현재 설정 확인
cluster.options()
cluster.setOption(option,value)
//모든 인스턴스에 대해 설정 변경 또는 클러스터 단위 설정 변경
cluster.setInstanceOption(instance,option,value)
//클러스터 인스턴스별 설정 변경빌트인 태그
cluster.setInstanceOption("ic-node1:3306","tag:location","Seoul")사용자가 임의로 설정하는 태그의 키 값은 언더스코어(_)로 시작X
=> 빌트인 태그가 _로 시작
cluster.setInstanceOption("ic-node1:3306","tag:_hidden",true)
//태그 값이 true라면 MySQL 라우터에서 해당 인스턴스로 쿼리 요청 전달X
cluster.setInstanceOption("ic-node1:3306","tag:_disconnect_existing_sessions_when_hidden1",false)
//_hidden과 위 태그가 true면 MySQL 라우터는 해당 인스턴스와 연결된 커넥션 끊음🎍InnoDB 클러스터 트러블슈팅
1. 클러스터 인스턴스 장애
네트워크 통신이 안정화되고, 서버에 별다른 문제가 없다면 사용자는 인스턴스에서 MySQL 그룹 복제가 재시작되게 해서 인스턴스를 다시 클러스터에 참여
cluster.rejoinInstance(instance)
//클러스터에 참여하는 데 필요한 설정 확인 및 재설정 후 그룹 복제 실행2. 클러스터의 정족수 손실
정족수, 즉 과반수 이상의 인스턴스에 장애 발생시 쓰기 요청 처리 불가
cluster.forceQuorumUsingPartitionOf(instance)
//해당 인스턴스에서 정상적인 상태로 인식되는 클러스터 내 다른 인스턴스들 확인 후 그 인스턴스들로 클러스터 재구성🎎InnoDB 클러스터 버전 업그레이드
클러스터 안전하게 업그레이드 하는 순서
1. MySQL 라우터 업그레이드
2. MySQL 셸 및 InnoDB 클러스터 메타데이터 스키마 업그레이드
3. MySQL 인스턴스 업그레이드
dba.upgradeMetadata()
//메타데이터 스키마 버전 업그레이드롤링 업그레이드(Rolling Upgrade) : 세컨더리 서버부터 순차적으로 업그레이드해서 프라이머리 서버를 가장 마지막에 업그레이드
=> _hidden 태그 이용
🎏InnoDB 클러스터 제약 사항
그룹 복제의 제약 사항 포함
--defaults-extra-file 옵션을 사용해 추가적 옵션 파일 지정해 사용X별도 복제 채널관리X샤딩지원X- MySQL
라우터는하나의 클러스터에 대해서만 설정 가능
