
이제 범주형 데이터를 다듬어보겠습니다. Embarked에는 S, Q, C 값이 있는데 2개의 값이 null입니다. 이때는 최빈값으로 null값을 채워줍니다.
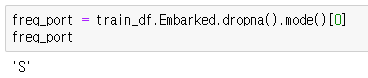 최빈값은 S입니다.
최빈값은 S입니다.
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)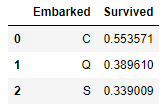 승선항에 따른 생존율입니다.
승선항에 따른 생존율입니다.
이제 S, Q, C라는 값을 숫자값으로 바꿔주겠습니다. (0, 1, 2)
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()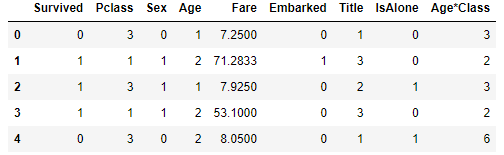 거의 다 되어가는 느낌입니다.
거의 다 되어가는 느낌입니다.
이제 Fare가 남았습니다. test datasaet에 단 한개의 null값이 있습니다. 이 결측치는 최빈값으로 대체합니다.
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()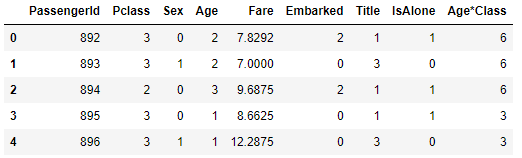
이제 운임을 네개의 범주로 나누어보겠습니다.
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)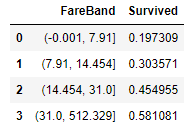 벌써부터 운임료에 따른 생존율 차이가 보이네요..
벌써부터 운임료에 따른 생존율 차이가 보이네요..
Age처럼 Fare도 범주값으로 치환해주겠습니다.
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]
train_df.head(10)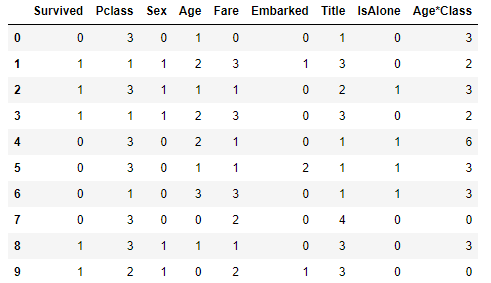 진짜 간단하네요.
진짜 간단하네요.
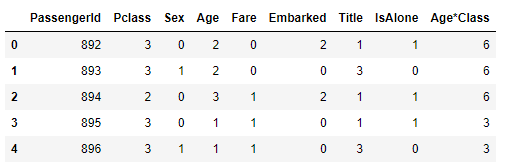
test dataset은 이렇게 바뀌었습니다.
이제 모두 다듬었으니 모델을 만들어 보겠습니다.
(참고: https://www.kaggle.com/startupsci/titanic-data-science-solutions)

데이터 사이언티스트를 꿈꾸는 감자