
필요없는 데이터를 정리해보겠습니다.
Ticket, Cabin을 빼겠습니다.
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape
name와 passengerId도 빼려는데, 우선 이름과 생존여부의 상관관계에 대해 분석해보겠습니다.
우선 정규식을 이용하여 title feature를 추출하겠습니다.
이부분은 잘 모르겠어서 나중에 분석해보겠습니다
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df['Title'], train_df['Sex'])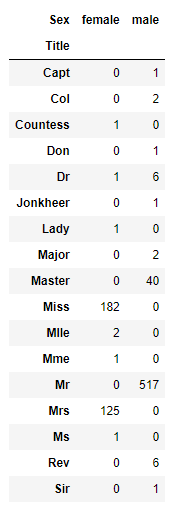
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()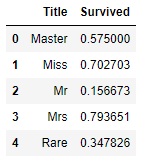
이제 처음의 train dataset에 title이라는 variable을 추가할 수 있습니다.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train_df.head()
이제 이름과 passengerID를 뺄 수 있습니다.
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape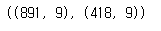
train_df.head()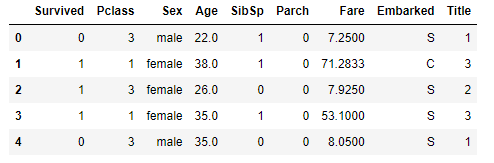
성별을 male, female이 아닌 0, 1로 치환하겠습니다.
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_df.head()
이제 결측값을 만져보겠습니다. 우선 Age의 결측값을 추정해보겠습니다.
결측값 추정 방법엔 세가지가 있습니다.
1. 평균과 표준편차 사이 난수를 생성합니다.
2. 조금 더 정확히 추정하는 방법으로, 상관관계를 따집니다. Age, Geneder, Pclass 사이의 상관관계를 알아봅니다. Pclass와 Gender의 조합 집합에서 연령의 중위수 값을 사용합니다.
3. 1번 방법과 2번 방법을 결합하여 상관관계를 따지되 중위수 대신 평균과 표준편차 사이의 난수를 사용합니다.
2번 방법을 사용해보겠습니다.
# grid = sns.FacetGrid(train_df, col='Pclass', hue='Gender')
grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()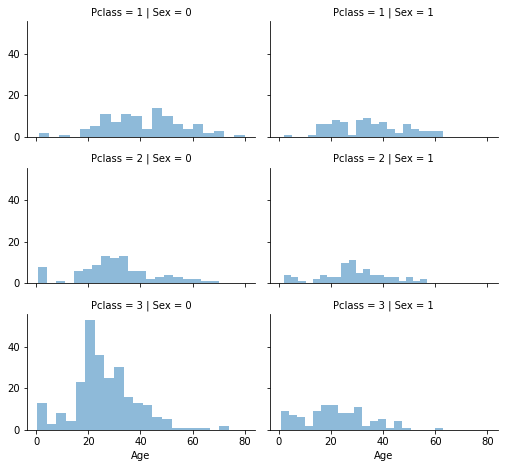
Pclass와 Gender의 조합으로 연령을 추측할 빈 배열을 만듭니다.
guess_ages = np.zeros((2,3))
guess_ages이제 6가지 조합에 대한 Age의 추정값을 구한 뒤 train 데이터셋을 보겠습니다.
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
guess_df = dataset[(dataset['Sex'] == i) & \
(dataset['Pclass'] == j+1)]['Age'].dropna()
# age_mean = guess_df.mean()
# age_std = guess_df.std()
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
age_guess = guess_df.median()
# Convert random age float to nearest .5 age
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\
'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
train_df.head() Age가 모두 정수가 되었네요.
Age가 모두 정수가 되었네요.
나중에 코드를 더 뜯어보도록 합시다
이제 Age를 다섯 범주로 나누어보겠습니다.
train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)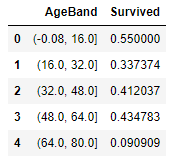 이제 데이터셋의 Age 데이터를 범주화한것으로 나타냅니다.
이제 데이터셋의 Age 데이터를 범주화한것으로 나타냅니다.
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train_df.head()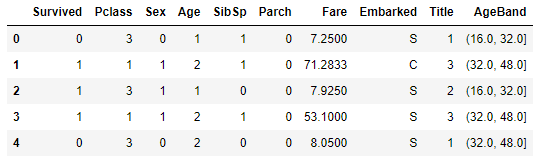 Age값이 범주값으로 치환된 것을 확인할 수 있습니다. 그리고 Ageband를 떼어내줍니다.
Age값이 범주값으로 치환된 것을 확인할 수 있습니다. 그리고 Ageband를 떼어내줍니다.
train_df = train_df.drop(['AgeBand'], axis=1)
combine = [train_df, test_df]
train_df.head()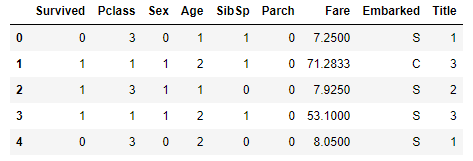 좋네요.
좋네요.
다음으로 Parch와 SibSp를 FamilySize라는 새로운 feature로 묶어주겠습니다. 그러면 Parch와 SibSp를 떼줄수 있을겁니다.
SibSp + Parch + 1은 해당 승객의 가족구성원수가 될 것입니다.
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)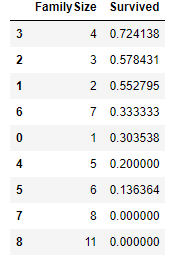 여기서 IsAlone이라는 feature를 만들 수 있을 것입니다.
여기서 IsAlone이라는 feature를 만들 수 있을 것입니다.
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()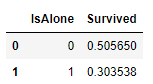 혼자였을때의 생존율이 더 낮네요
혼자였을때의 생존율이 더 낮네요
이제 Parch, SipSp, FamilySize를 떼어줍니다. IsAlone만 보겠습니다.
train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]
train_df.head()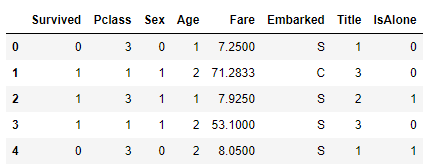 점점 간단해지고있습니다. (어떻게 이런 생각을 했던걸까요?)
점점 간단해지고있습니다. (어떻게 이런 생각을 했던걸까요?)
PClass와 Age를 결합하여 새로운 feature를 만들 수 있습니다.
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)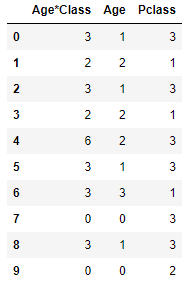
(출처: https://www.kaggle.com/startupsci/titanic-data-science-solutions)
