Intro
문장을 임베딩하기 위해서는 sentence-transformer model을 로드해야 한다.
sentence_transformers 라이브러리를 통해 SentenceTransformer 생성자를 통해 해당 변환기 모델을 로드할 수 있다.
이때, 사전 학습된 모델을 지정하거나 디스크에 경로를 전달하여 해당 폴더에서 모델을 로드할 수도 있다.
모델을 기본적으로 GPU에서 자동적으로 실행된다(가능하다면). 하지만 별도로 모델에 대한 장치를 지정할 수 있다.
Input Sequence Length
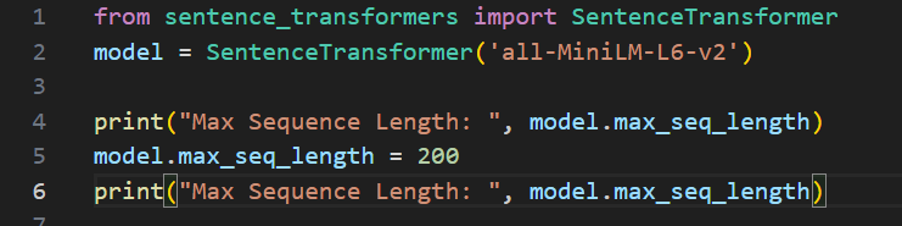
트랜스포머 모델에서는 런타임과 메모리 요구량이 입력 길이에 따라 4제곱으로 증가한다. 기본적으로 제공된 메서드에는 최대 시퀀스 길이가 정해져 있어 더 긴 입력을 잘린다. 하지만 다음과 같이 최대 시퀀스 길이를 설정할 수 있다.
각 트랜스포머 모델에서 최대로 지원하는 길이보다 더 길게 늘릴수 없고 짧은 텍스트로 학습된 모델은 긴 텍스트의 표현이 좋지 않을 수 도 있다.

Store & Loading Embeddings
전체 코드
from sentence_transformers import SentenceTransformer
import pickle
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
embeddings = model.encode(sentences)
#Store sentences & embeddings on disc
with open('embeddings.pkl', "wb") as fOut:
pickle.dump({'sentences': sentences, 'embeddings': embeddings}, fOut, protocol=pickle.HIGHEST_PROTOCOL)
#Load sentences & embeddings from disc
with open('embeddings.pkl', "rb") as fIn:
stored_data = pickle.load(fIn)
stored_sentences = stored_data['sentences']
stored_embeddings = stored_data['embeddings']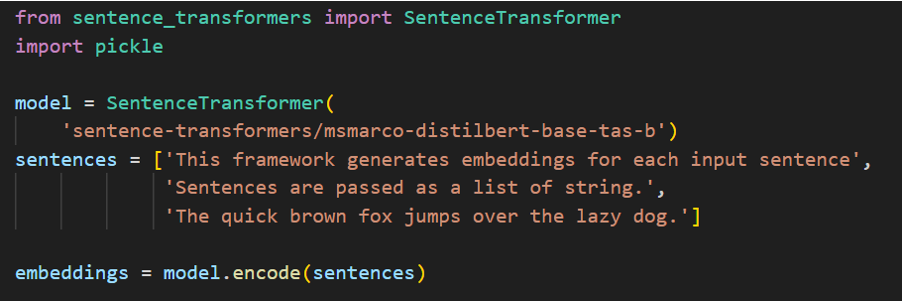
특정 문장을 임베딩하는 코드이다.
가장 쉽게 저장하고 로드하는 방법은 미리 계산된 임베딩을 디스크에 저장하고 디스크에서 로드하는 방법이다. 특히 큰 문장 집합 - corpus 을 인코딩해야 할 때 유용하다.
임베딩한 파일을 디스크에 다음과 같이 저장할 수 있다.

해당 코드는 문장 목록과 해당 임베딩을 embeddings.pkl에 저장하는 코드이다. 나중에 다시 생성할 필요 없이 임베딩을 사용할 수 있다.
pickle.dump는 pickle 라이브러리의 함수인데 python 객체를 직렬화하여 파일을 쓰는데 활용된다. 직렬화를 통해 다시 파이썬 객체로 되돌리거나 역직렬화 할 수 있도록 객체의 상태를 바이트 스트림으로 변환한다.
이때 직렬화 프로토콜을 지정할 수 있는데 HIGHEST_PROTOCOL은 가장 효율적인 직렬화를 위해 본적으로 가장 최적화된 방식으로 데이터를 저장하는 방식이다.
이를 통해 해당 문장 목록과 임베딩의 딕셔너리는 직렬화되어 embeddings.pkl에 저장된다.

이진 파일이기 때문에 다음과 같이 BufferedWriter라는 클래스가 생성된 것을 확인할 수 있다.
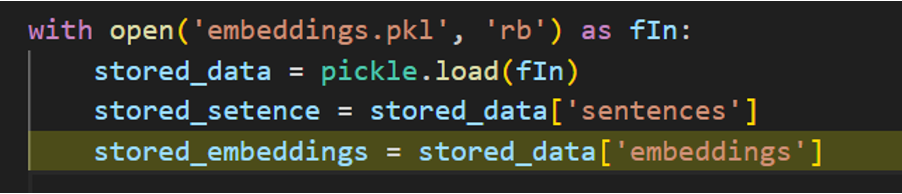
이후 다음과 같은 코드를 통해 저장된 pkl 파일을 메모리로 다시 읽고 변수에 로드할 수 있다.
pickle.load()를 통해 역직렬화를 하면 해당 데이터가 sentence와 embeddings의 딕셔너리임을 확인할 수 있다.
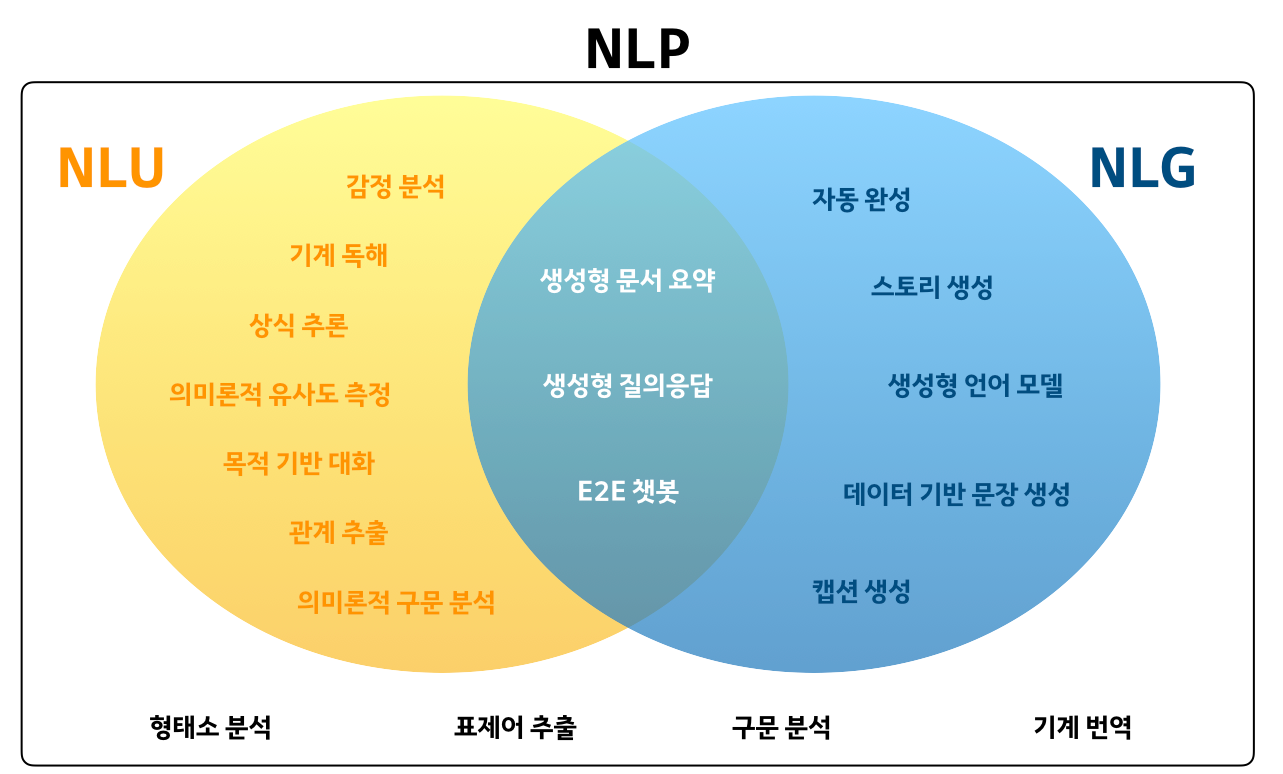
Sentence Embeddings with Transformers
사전 학습된 대부분의 모델은 HuggingFace의 Transformers를 기반으로 하며 HuggingFace의 모델 저장소에서도 호스팅된다.
문장 트랜스포머를 설치하지 않고도 문장에 대한 임베딩 모델을 사용할 수 있다.
-> huggingface model repository를 통해 AutoTokenizer와 AutoModel을 로드함.

Model - AutoModel
기본적으로 Model들을 PretrainedModel 클래스를 상속받는다. 따라서 학습된 모델을 불러오고 다운로드하고 저장하는 메서드를 갖고 있다.
실제로 사용할 모델과 관계없이 부모 클래스를 상속하기 때문에 동일하게 활용 가능하다.
AutoModel은 모델에 관한 정보를 처음부터 명시하지 않고 쉽게 모델 구성이 가능하다.
Tokenizer
transformer는 바로 불러와서 사용할 수 있도록 다양한 tokenizer를 각 모델에 맞춰 구비하고 있다.
직접 명시하여 사용할 tokenizer를 지정할 수 있고 AutoTokenizer를 사용하여 이미 구비된 model에 맞는 tokenizer를 자동으로 불러올 수도 있다.
model에서 명시하는 것과 동일한 id로 생성해야 한다.
padding, truncation, return_tensors와 같이 옵션을 설정할 수 있다.
tokenizer 함수는 자연어 텍스트를 ML Model에서 처리할 수 있는 형식으로 반환되는데 사용된다. 인자로 들어간 문장을 일련의 토큰으로 변환한 다음 단어에 따라 정수로 매핑한다.

예시 코드를 보면서 동작 원리에 대해 이해하면
- padding=True : 문장의 길이가 서로 다른 경우 패딩 토큰을 추가해서 모두 같은 길이로 만든다.
-> 이 때 문장의 실제 토큰과 패딩 토큰을 구분하기 위해 “attention token”을 생성한다. binary list로 1은 실제 토큰을, 0은 패딩 토큰을 의미한다. - truncation=True : 문장의 최대 길이(max_length)보다 많은 토큰이 있을 경우 문장을 잘라낸다.
- max_length : 토큰화된 문장의 최대 길이
- return_tensors=’pt’ : pytorch tensor를 반환한다.

이렇게 sentence를 tokenzier한 반환값인 encode_input을 확인하면 다음과 같이 input ids, 와 token_type_ids와 attention_mask로 이루어진 딕셔너리임을 알 수 있다.
즉 text data를 입력받아 ML Model에 입력할 수 있는 형식으로 변환하고 이때 발생하는 다양한 문장 길이나, 문장 당 토큰 한도와 같은 문제를 처리할 수 있게 하는 메서드이다.
torch.no_grad

Pytorch에서는 ML 모델을 훈련할 때 매개 변수가 얼마나 변경되어야 하는지 측정하는 척도인 기울기를 계산한다. 이를 gradation이라 하는데 이를 위해서는 추가 메모리가 필요하다.
하지만 해당 작업은 이미 로드한 ML 모델에서 토큰화된 텍스트를 처리해서 임베딩을 생성하는 것이기 때문에 해당 연산이 필요하지 않으므로 메모리 절약을 위해 torch.no_grad() 상태에서 실행한다.
(**encoded_input)의 형태로 인자를 넣는 이유는 이중 별표는 python에서 key-value 쌍으로 언패킹 하는 방식이기 때문이다. 이를 통해 encoded_input의 값이 key-value의 형태로 model에 인수로 들어간다.
BaseModelOutputWithPoolingAndCrossAttentions의 형태로 반환된다.
mean_pooling
Padding toeken을 무시하는 attention mask를 고려해서 각 문장에 대한 token embedding의 평균을 계산한다.
이를 통해 해당 문장의 임베딩 값을 추출한다.

