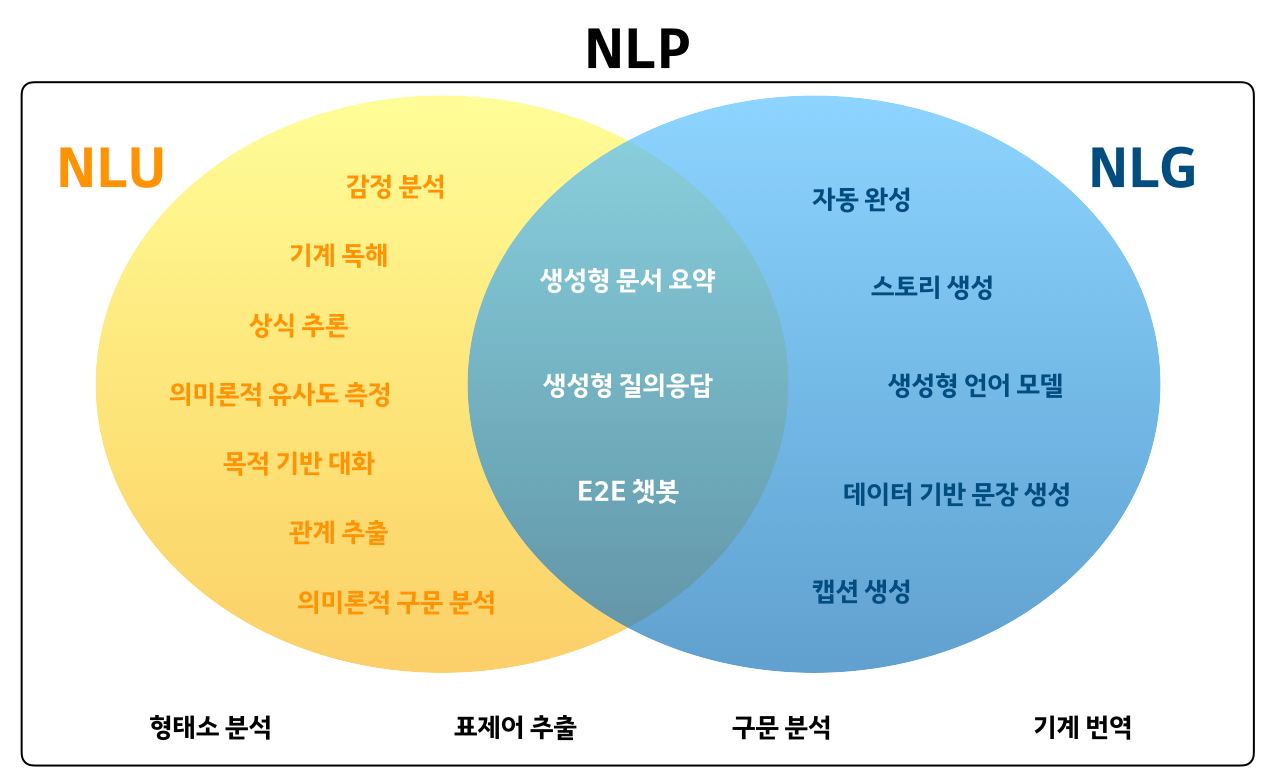
Intro
시멘틱 검색은 어휘 일치 만으로 문서를 찾는 기존 검색 엔진과 달리, 동의어까지 찾을 수 있다.
기본 개념은 문장, 단락, 문서 등 corpus에 있는 모든 항목을 벡터 공간에 포함시키는 것이다.
검색할 때 쿼리가 동일한 벡터 공간에 임베드 되고, corpus에서 가장 가까운 임베딩이 발견된다. 이 항목은 쿼리와 의미론적 중첩이 높아야 한다.
Symmetric vs. Asymmetric Semantic Search!
Symmetric semantic search(대칭 시멘틱 검색)의 경우 쿼리와 corpus의 항목의 길이가 거의 같고 콘텐츠의 양이 동일하다. -> 비슷한 질문을 검색하는데 활용할 수 있다.
예를 들어 “ML을 인터넷으로 배우는 방법”이라는 쿼리를 “웹에서 ML을 배우는 방법”과 같은 항목을 찾고자 할 수 있다.
Asymmetric Semantic Search(비대칭 시멘틱 검색)의 경우 질문이나 일부 짧은 질문과 같은 쿼리가 있고, 쿼리에 대한 답변이 포함된 긴 단락을 찾는 것이다.
예를 들어 “ML이란 무엇인가”라는 쿼리를 입력하면 “ML이란 ~~~다”와 같은 단락을 찾을 수 있다.
따라서 작업 유형에 적합한 모델을 선택하는 것이 유용하다
Semantic Search By Python
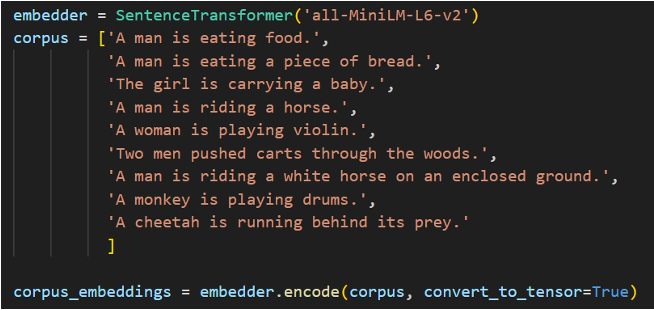
검색 대상인 corpus를 임베딩한다.
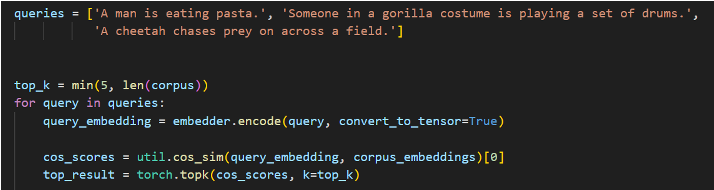
찾으려는 문장 query를 순회하면서 tensor로 임베딩 한 후, 해당 문장과 corpus의 코사인 일치도인 cos_socores를 계산한다.
이후 해당 코사인 일치도가 상위 5위 안에 들어가는 벡터값만 반환하는 함수 torch.top_k를 통해 정해진 우선순위에 따라 정렬되고 잘라진 벡터를 반환하도록 한다.

cos_scores의 data를 확인하면 다음과 같이 query와 corpus의 코사인 일치도를 담은 벡터가 tensor로 저장되어 있음을 확인할 수 있다.

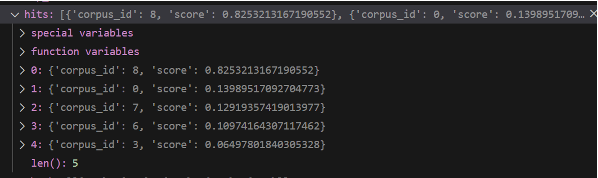
top_result의 data를 확인하면 0번째 인덱스에는 corpus_embeddings와 query_embedding의 코사인 일치도 상위 5개의 벡터가 저장되어 있다.
1번 인덱스에는 해당 벡터값이 본래 벡터에서 몇 번째 인덱스에 위치하는지 저장되어 있다.

다음과 같이 corpus와 해당 문장의 일치도를 명확하게 확인할 수 있다.
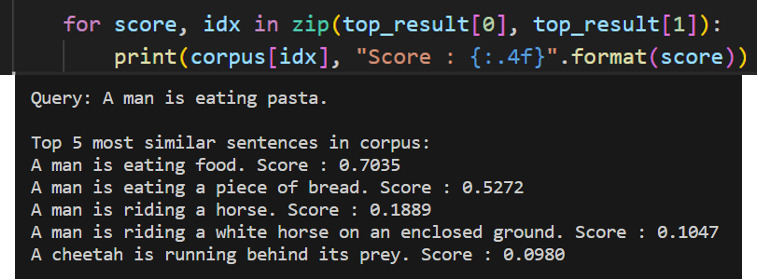
아니면 다음과 같이 util.semantic_search메서드를 통해 한 번에 우선순위에 따른 코사인 일치도와 해당 벡터의 인덱스를 반환할 수 있다.
util.semantic_search

sentence_transformer에서 제공하는 semantic_search 함수를 통해 직접 시멘틱 함수를 구현하지 않고 시멘틱 탐색이 가능하다.
query_embeddings와 corpus_embeddings의 코사인 유사도 검색을 수행하며, 최대 약 100만 개의 corpus에 대한 검색에 사용할 수 있다.
- query_chunk_size : 한 번에 처리하는 쿼리의 수 (기본 100개). 이 값을 늘리면 속도는 빨라지지만 메모리가 더 많이 필요하다.
- corpus_chunk_size : corpus에서 한 번에 스캔하는 항목의 수, 이 값을 늘리면 속도는 빨라지지만 메모리가 더 많이 필요하다.
- top_k : 일치하는 상위 k개의 항목을 검색한다.
- score_function - 점수 계산을 위한 함수, 기본적으로 코사인 유사도로 설정
기본적으로 최대 100개의 쿼리가 병렬로 처리된다. 또한 corpus는 최대 50만개의 항목으로 구성된 집합으로 chunk된다.
Example

0번째 인덱스를 접근하는 이유는 해당 메서드의 데이터는 0번째 인덱스에 저장되어 있기 때문이다

0번째 인덱스에 접근하여 데이터를 확인하면 다음과 같이 코사인 일치도에 따른 벡터 인덱스와 일치도 값을 확인할 수 있다.
Speed Optimization
해당 메서드의 최적 속도를 얻기 위해서는 동일한 GPU 장치에 query embedding과 corpus embedding을 함께 사용하는 것이 좋다. 성능이 크게 향상된다.
또한 각 corpus embedding의 길이가 1이 되도록 corpus embedding을 정규화할 수 있다. 이 경우 일치도 점수를 계산하는데 dot-product를 사용할 수 있다.
