임베딩이란
- 텍스트, 문서, 이미지, 오디오 등의 정보를 숫자로 표현한 것.
- 임베딩은 정보의 semantic meaning을 포착해서 많은 사업 분야에서 다양하게 사용 가능하다.
- 어떤 텍스트가 주어지면 이 문장의 임베딩은 여러 개의 숫자목록으로 이루어진 벡터 배열로 표현된다. 서로 다른 텍스트의 일치도를 확인할 때 이 벡터 값의 거리를 계산하는 방식으로 활용할 수 있다.
- 이미지 임베딩을 생성하고 텍스트 임베딩과 비교해서 해당 문장과 이미지의 일치도를 확인하는 데에도 활용할 수 있다.
-> 이미지 검색, 분류, 설명 등을 위한 시스템에서 활용 가능.
-> 검색 엔진, 추천 시스템, 챗봇 등을 구축하는데에도 활용 가능. - 참고한 블로그에서는 Sentence Transformer라는 오픈 소스 라이브러리를 사용해서 이미지와 텍스트로 임베딩을 진행하는 예시를 통해 설명한다.
sentence transformer을 활용한 임베딩 구현
먼저 데이터 셋을 sentence transformer를 통해 전환한다.
사전 훈련된 transformer model과, Hugging Face API가 활용된다.
활용할 model_id가 있는 url로 hugging face의 write token값을 bearer 헤더에 담아 json 요청을 보내면 임베딩이 포함된 리스트를 반환한다.
이를 pandas라이브러리에서 dataframe 메서드를 통해 임베딩 값으로 전환한다. 이후 csv로 전환하고 hugging face에 업로드하면 dataset에 대한 공유와 로드를 쉽게 할 수 있다.
텍스트 임베딩을 활용한 유사성 검색

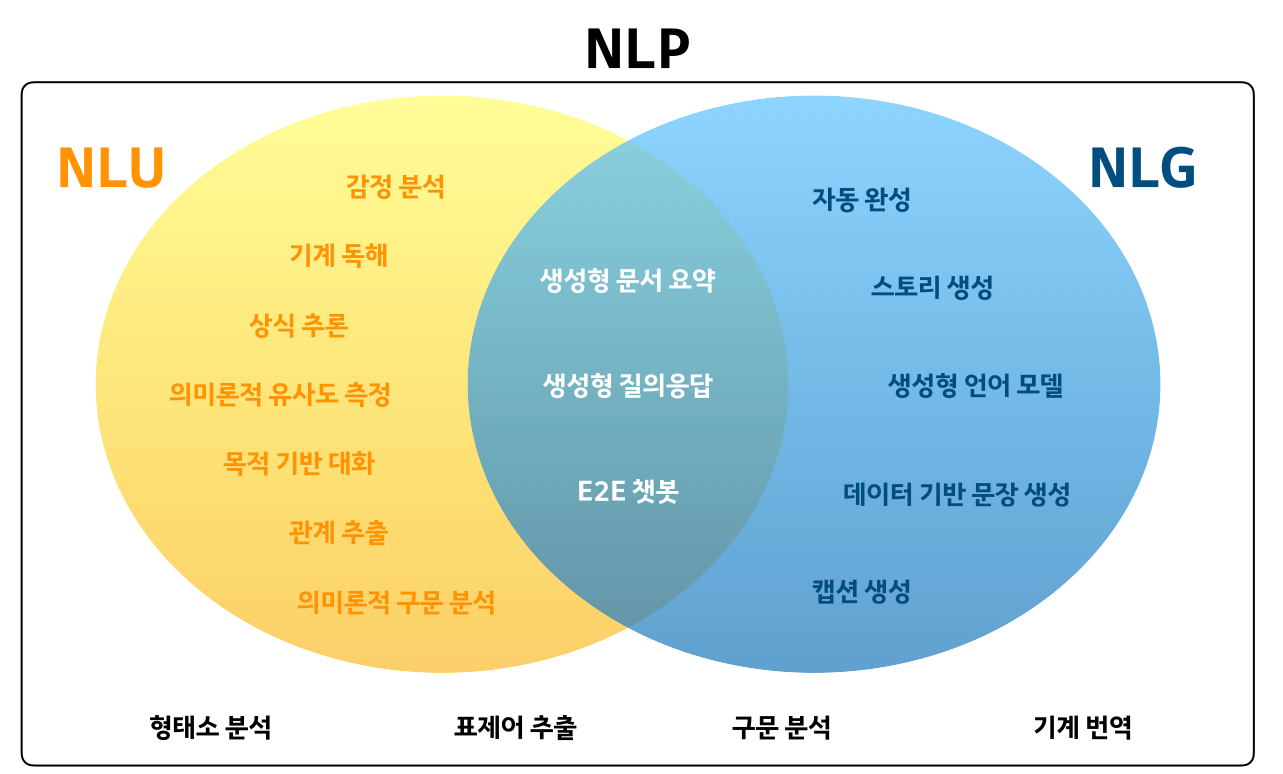
faqs_embeddings는 Hugging Face에서 업로드했던 데이터셋 csv를 로드해온 결과값이다.
먼저 train이 실제로 활용할 데이터셋이다.
아래 과 같은 형태를 보인다.

해당 값을 panda data frame으로 변환하면 아래와 같이 임베딩 했던 값 그대로의 형태로 확인된다.

dataset_embedding은 사전에 임베딩된 질문 내용의 [train]인덱스의 값을 pd dataframe으로 전환한뒤 to_numpy를 통해 nd array로 전환한다 그리고 해당 데이터를 float 값으로 구성된 tensor를 생성한 값이다.
cf) 반환된 tensor와 ndarray는 동일한 메모리를 공유한다. 따라서 각 수정사항은 서로에게 영향을 미친다
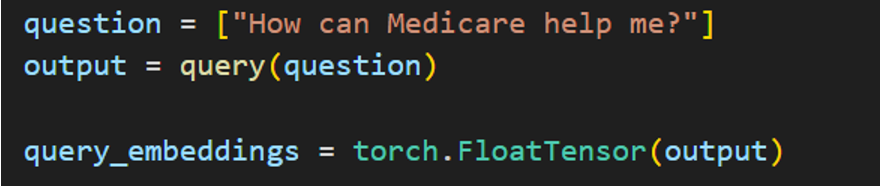
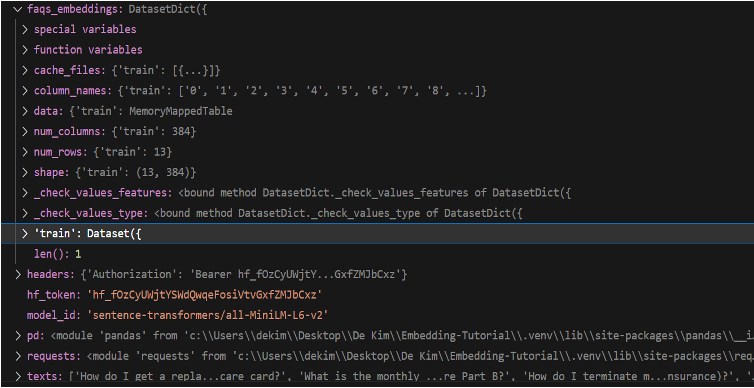
torch.FloatTensor - 질문을 tensor 값으로 전환한다. query를 통해 vetor로 전환된 output은 2차원 list의 형태를 가진다. torch.FloatTensor는 해당 vector를 Tensor로 전환한다.
이렇게 검색하려는 쿼리와, 데이터 셋을 tensor로 변환하는 이유는 sentence transformer.util에서 제공하는 semantic_search메서드를 활용하기 위함이다.


인자를 Tensor로 받아 query_embedding과 corpus_embedding의 일치도를 계산해서 top_k의 개수만큼 일치도 순대로 반환하는 메서드이다.
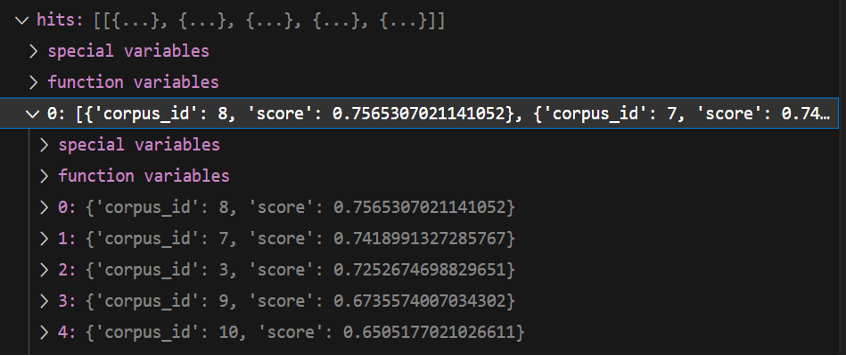
이렇게 sentence transformer에서 query와 dataset을 비교해서 일치도에 따른 해당 데이터의 인덱스와 일치 점수를 반환한다.
만약 해당 데이터 셋의 값을 텍스트로 반환하고 싶은 경우에는 아래와 같이 데이터 셋이 있다고 가정하면
semantic_search의 반환값에서 0번째 인덱스안의 각 딕셔너리 인덱스에서 corpus_id에 접근하면 해당 데이터가 위치한 인덱스를 확인할 수 있다.

